Ruby 和 InfluxDB 入门
作者 Community / 产品, 用例, 开发者, 入门
2022年1月4日
导航至
本文由 Oluwaseun Raphael Afolayan 撰写。向下滚动查看作者的照片和简介。
像 InfluxDB 这样的时间序列数据库按时间索引数据。它们在记录恒定的数据流方面非常有效,例如服务器指标、应用程序监控、传感器报告或任何其他包含时间戳的数据。这种结构使得分析随时间的变化变得轻而易举。
本教程将向您展示如何使用示例 Ruby 应用程序设置 InfluxDB。
什么是时间序列数据库?
时间序列数据库是一种针对存储和检索 带时间戳的数据,或涉及在特定时间段内收集的事件和测量的数据而优化的数据库。
时间序列数据库 在物联网 (IoT) 设备的实施中尤其有用,因为远程设备不断捕获用于分析目的的指标。另一个方便的用例是构建服务器监控应用程序时,因为您可能需要关于您的系统在特定时间段内如何运行的详细报告,以监控业务或安全关键数据。
为什么使用 InfluxDB?
InfluxDB 是时间序列数据库最流行的 可用选项 之一。所有功能都呈现在一个统一的 API 中,并且它提供了强大的 UI 和仪表板工具。
尽管 InfluxDB 与传统数据库有一些相似之处,但 它不是一个实际操作的 CRUD 数据库。InfluxDB 更侧重于写入和读取数据,而不是修改和销毁数据。
您可以通过插入具有相同测量值、标签集和时间戳的数据来更新 InfluxDB 中的记录。这使得 InfluxDB 更好地优化以处理读/写操作。
如何使用 InfluxDB
您将在本地计算机上安装 InfluxDB,并使用 influxdb-client-ruby package 将其与 Ruby 集成,然后学习一些基本的数据库操作。
InfluxDB 提供了一系列客户端库,使与各种技术的集成变得轻松。对于 Ruby 开发者,InfluxDB 提供了 influxdb-client-ruby 软件包,该软件包适用于 InfluxDB 1.8+ 和 2.x 版本。
设置您的机器
本教程假设您的本地计算机上有一个 Ruby 开发环境。
要验证您的 Ruby 安装,请运行以下命令以查看安装的版本。

如果您没有 Ruby,请运行 brew install ruby 命令,如果您是 Mac 用户,则可以使用 Homebrew(macOS 包管理器)下载 Ruby 编译器。
基于 Debian/Ubuntu 的 Linux 用户可以使用 APT 包管理器或运行 sudo apt-get install ruby-full 来安装编译器。
如果您使用的是 Windows 设备,请运行 Ruby 安装程序。
其他操作系统或 Linux 发行版的安装指南可以在官方 Ruby 文档中找到。一旦您设置了本地 Ruby 安装,您就可以安装 InfluxDB 平台了。
或者,您可以使用 InfluxDB Cloud 在几分钟内获得免费的 InfluxDB 实例运行,而无需在本地计算机上进行任何设置。除了您需要在代码中使用您选择托管实例的云提供商的 URL 而不是 localhost 作为 URL 参数之外,其他都将相同。
安装 InfluxDB
您可以通过运行在您的 Mac 上安装 InfluxDB 软件包
## update Homebrew
brew update
brew install influxdb对于其他操作系统或基于 Docker 或 Kubernetes 的环境,请查看 安装指南。
安装完成后,您可以使用终端中的 influxd 命令来启动服务器。
设置 InfluxDB
您有两种 本地设置选项:通过基于 Web 的 UI 或通过命令行。
使用 UI
为了访问 InfluxUI 界面,您需要运行带有 influxd 命令的守护程序。前往 localhost:8086 并输入您的配置配置文件。
使用 CLI
InfluxDB CLI 允许您从命令行操作本地数据库。您可以通过运行 influx --help 或 influx -h 来查看可用命令列表
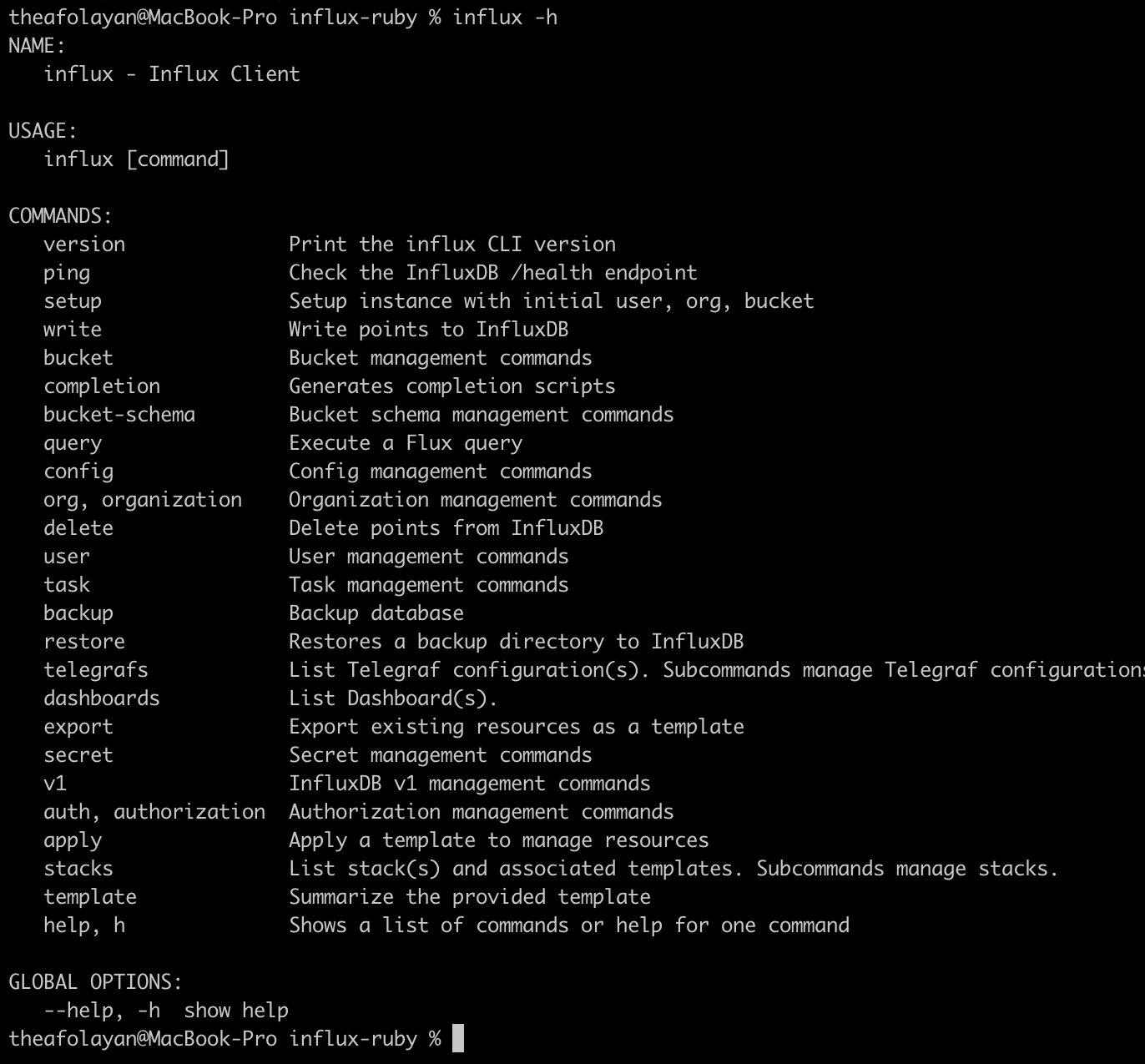
要设置 CLI,请运行 influx setup 并按照提示输入您的用户信息。
生成令牌
要使用客户端与您的存储桶交互,您需要设置一个授权令牌,该令牌可以从 CLI 生成,方法是运行 influx auth create -o <organization-name>。
使用 influx auth create 命令还允许您指定应该授予令牌哪些权限,如下所示
influx auth create -o organization-name \
--read-buckets \
--write-buckets \
--read-dashboards \
--read-tasks \
--read-user如果您更喜欢更直观的界面,您可以通过单击 UI 中的 Data 选项卡,然后在左侧单击 Tokens 选项卡来创建和管理令牌
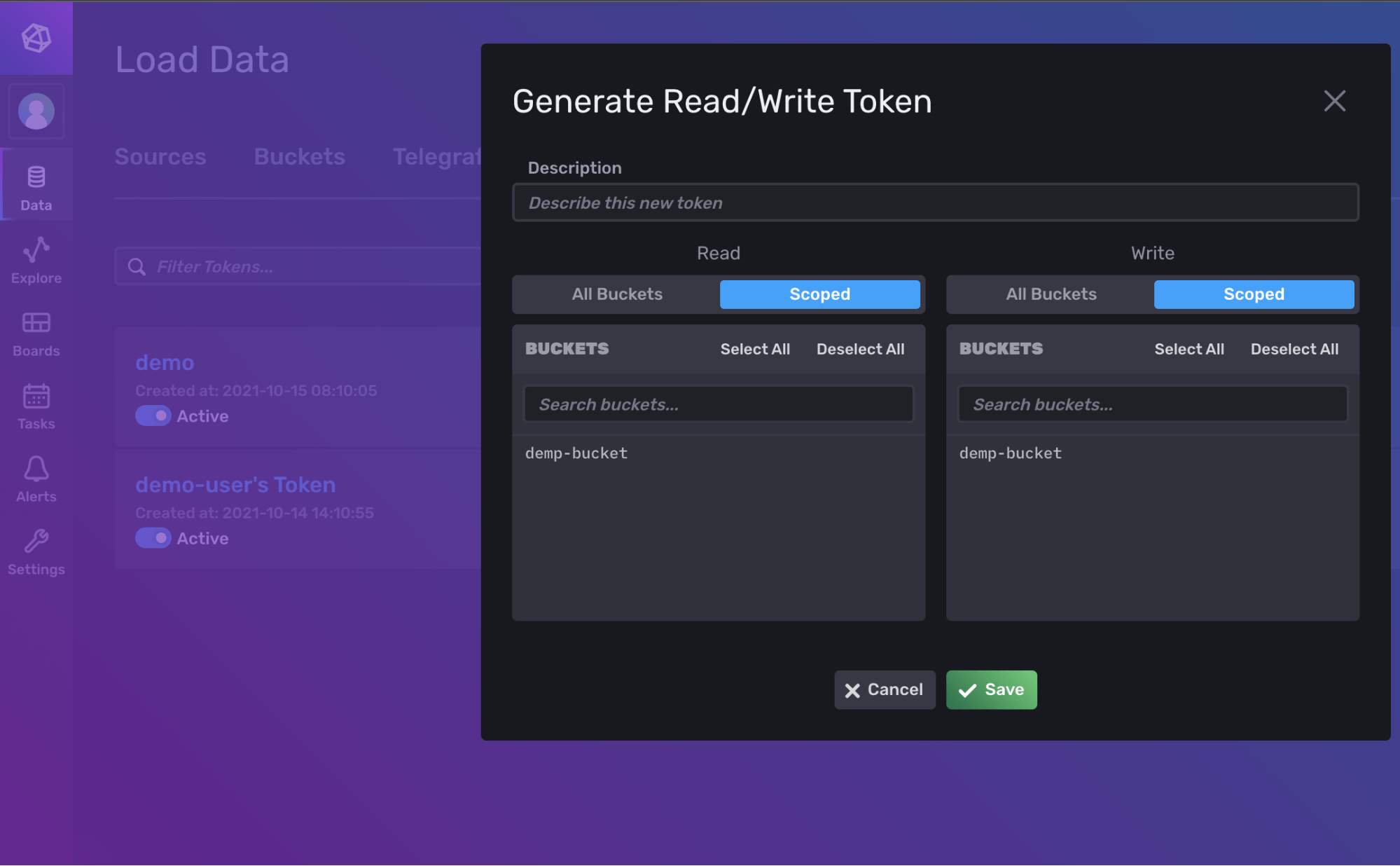
成功设置令牌后,将其存储在安全的地方,因为您稍后需要它。
安装客户端库
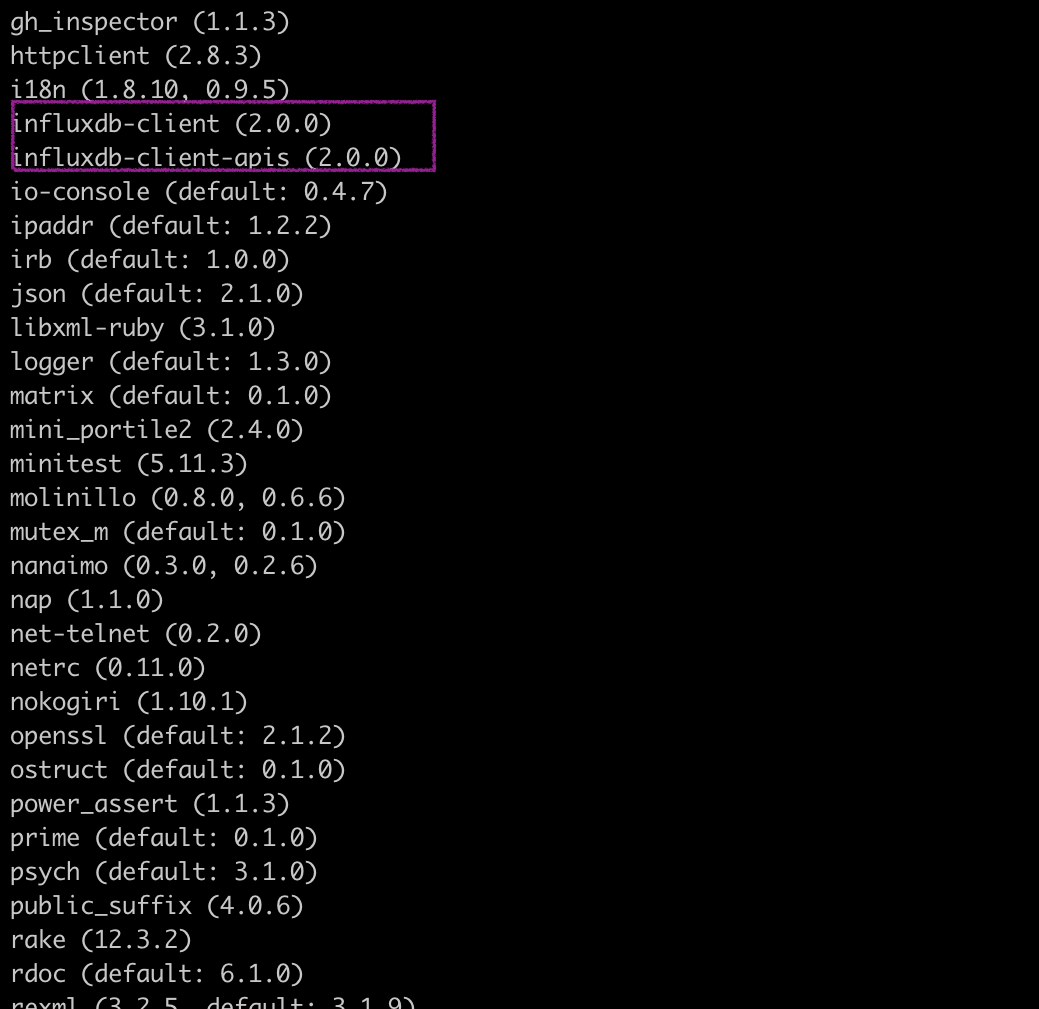
influx-ruby library 是一个标准的 Ruby 软件包,可以从 RubyGems 安装
gem install influxdb-client -v 2.0.0
## Optionally install the client-apis
gem install influxdb-client-apis -v 2.0.0您可以通过运行 gem list 来验证 gems 的安装状态,这将输出您的可用 gems 列表。
建立连接
要与您的本地 InfluxDB 实例建立连接,您需要在文件顶部导入 influx-db-client,使用 require 'influxdb-client'。
将您的连接凭据设置为变量,将令牌变量替换为您之前创建的令牌的实际值。如果您在默认端口 8086 以外的端口中运行 InfluxDB,请在以下示例中更改它
token = 'YOUR_TOKEN_HERE'
org = 'demo'
bucket = 'demobucket'
url = 'https://:8086'在生产用例中,您希望将其作为机密存储在受保护的 .env 文件中。
接下来,使用 InfluxDB2::Client class 创建连接
client = InfluxDB2::Client.new(url, token, bucket: bucket, org: org)
使用 SSL/TLS 连接
当使用 InfluxDB2::Client.new() 方法与正在运行的 InfluxDB 2 实例建立连接时,需要一些参数。这些参数允许您将额外的选项(例如写入精度和 SSL 首选项)传递给实例。
默认情况下,对 Influx 客户端的访问启用了 SSL 加密,以便保护传入和传出的 HTTP 请求。要关闭它,请将 use_ssl 参数传递值 false
client = InfluxDB2::Client.new(url, token, bucket: bucket, org: org, use_ssl: false插入数据
现在您将创建要使用的示例数据。如果您不熟悉 Flux,请查看 文档 以开始查询您的实例。
使用 create_write_api.write() 方法,使用 InfluxDB 行协议、数据点或数组结构将数据存储在 InfluxDB 存储桶中。
使用行协议
使用 InfluxDB 行协议写入数据涉及以字符串格式将您的数据直接传递给 write() 方法。将测量名称作为字符串的第一个元素传递,后跟标签值对列表和实际数据字段的逗号分隔列表。
如果您要构建一个应用程序,用于监控仓库中不同时间间隔的人数,则行协议将以此格式表示
workers_in_warehouse,building=main,floor=one,supervisor=james count=200
您可以在 InfluxDB 文档中了解有关行协议的更多信息。
使用数据点
influxdb-client-ruby 软件包还提供了一个 InfluxDB2::Point 类,该类公开了一个 new() 方法,用于格式化要作为数据点写入存储桶的值。
执行此操作的通用语法如下所示
point = InfluxDB2::Point.new(name: 'workers_in_warehouse')
.add_tag('building', 'main')
.add_tag('floor', 1)
.add_tag('supervisor', 'james')
.add_field('count', 201)使用哈希
将数据写入存储桶的另一种方法是将数据解析为哈希——一种以纯对象形式存在的数据格式。
hash = { name: 'workers_in_warehouse',
tags: { building: 'main', floor: 1, supervisor: 'james' },
fields: { count: 213 }
}使用哈希写入数据非常棒,因为它很简单,但是您可以使用您最喜欢的任何语法。它们都工作得很好。
将数据保存到您的存储桶中
# Configuring write options
write_options = InfluxDB2::WriteOptions.new(write_type: InfluxDB2::WriteType::BATCHING, batch_size: 10, flush_interval: 5_000, max_retries: 3, max_retry_delay: 15_000, exponential_base: 2, precision: InfluxDB2::WritePrecision::NANOSECOND)
# Writing to the bucket
write_api = client.create_write_api(write_options: write_options)
# writing to the bucket
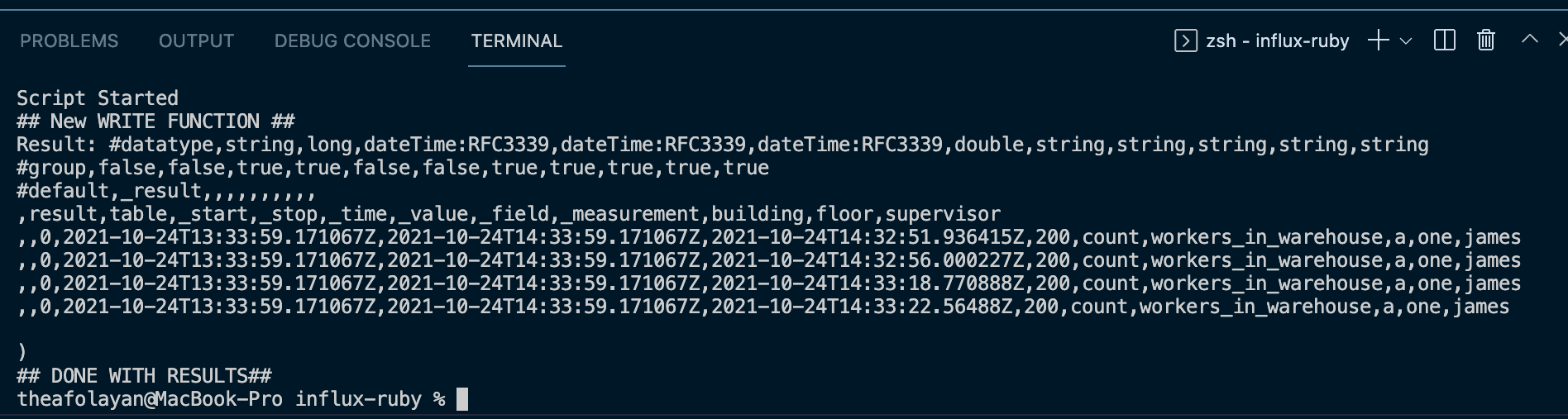
write_api.write(data: 'workers_in_warehouse,building=main,floor=one,supervisor=james count=200')运行此脚本后,前往 InfluxUI 的数据浏览器部分,查看您已插入存储桶的内容。
通过 InfluxDB UI 读取数据
如前所述,在本地安装 InfluxDB 会为您提供一个用于编辑数据的 Web 界面。使用该界面可以查看插入到存储桶中的数据的可视化表示。
使用您之前设置的用户名和密码登录到 InfluxUI。您应该会进入“入门”页面。
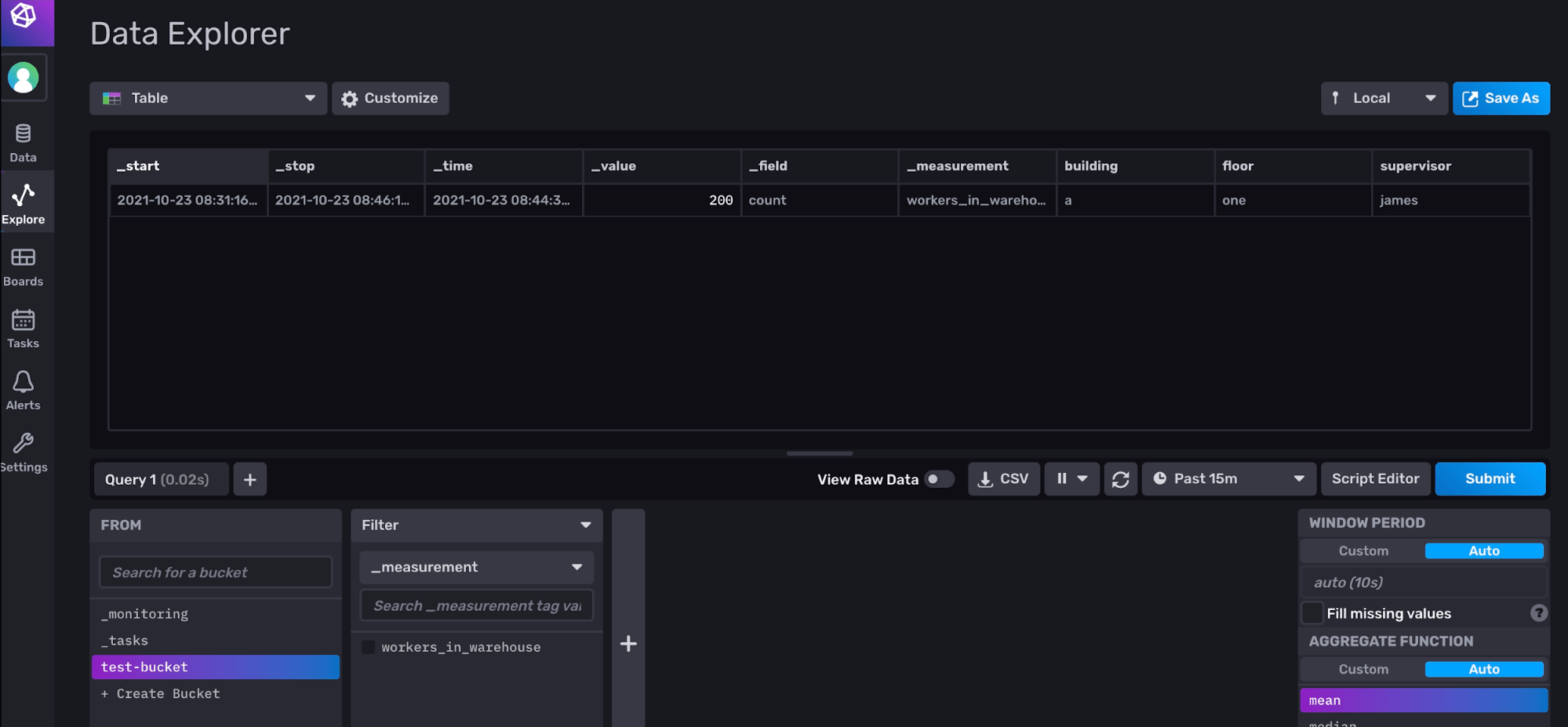
- 通过单击侧边栏上的 Data 菜单打开“加载数据”页面。
- 进入“加载数据”页面后,通过单击上面的水平菜单切换到“存储桶”部分。
- 打开
test-bucket,选择所需的测量值 (workers_in_warehouse),然后点击 Submit 以在数据浏览器部分显示数据。 - 您可以从可用选项中选择数据的格式
现在您需要一种方法来读取或查询从您的 Ruby 脚本插入到 InfluxDB 中的数据。
从 InfluxDB 读取数据
从 InfluxDB 读取或查询数据应该使用 Flux——一种数据脚本语言,旨在与 InfluxDB 和 Prometheus 等时间序列数据库以及 MySQL 和 PostgreSQL 等关系数据库一起使用。
如果您不熟悉 Flux,请查看 文档 以开始使用。
您可以通过从客户端实例化 create_query_api 属性来查询您的 InfluxDB 实例: query_api = client.create_query_api。
例如,如果您查询 InfluxDB 存储桶中过去一小时内插入的数据,则相应的 Flux 查询字符串将是
query = 'from(bucket:"' + bucket + '" ) |> range(start: -1h, stop: now())'
定义 Flux 查询后,您可以执行它以换取 query_raw() 方法返回的未处理字符串的数据,并将您的字符串作为参数传入
result = query_api.query_raw(query: query)
优化 InfluxDB 库
虽然 InfluxDB 已被证明是一个用于存储和检索时间序列数据的多功能平台,但您应该遵循某些 指南和最佳实践 以充分利用您的数据库。以下是一些提示
- 避免在测量名称中编码数据,以使其保持简单。
- 为了减小 InfluxDB 实例的大小和成本,请避免在存储桶中存储重复或不必要的数据。
- 以批处理方式写入数据,以最大限度地减少写入 InfluxDB 实例时的网络开销。您可以通过在写入选项中提供
batch_size属性,使用influxdb-client-ruby软件包启用批量写入。 - 在可能的情况下,在将数据写入实例时,请谨慎使用
time_precision属性的值。尽管 InfluxDB 默认使用纳秒精度将数据写入存储桶,但您并不总是需要在项目中这样做。
结论
InfluxDB 是一个令人兴奋的平台,可用于构建各种依赖时间的项目,用于分析和物联网 (IoT) 以及云原生服务。它与多个库配合使用,其开发者社区可帮助解决云或开源问题。
正如本教程所示,将 InfluxDB 与 Ruby 结合使用,为您提供了多种编译、查看和分析时间敏感数据的选项。
代码示例可以在此 GitHub 存储库 或此链接中的 GitHub gist 中找到。
关于作者

开发者 & 数字增长黑客。自由技术作家,致力于一次拯救世界,一个段落。
