Python 和地理时空分析入门
作者:Susannah Brodnitz / 产品
2022 年 10 月 31 日
导航至
本文最初发表于 The New Stack,经许可在此转载。
处理地理时空数据可能很困难。除了通常与时间序列分析相关的挑战(例如,您希望实时访问的大量数据)之外,处理纬度和经度通常涉及三角学,因为您必须考虑地球的曲率。这在计算上是昂贵的。它会推高成本并减慢程序运行速度。幸运的是,InfluxDB 的地理时空包旨在处理这些问题。
该软件包通过 S2 几何来实现这一点。S2 系统将地球划分为单元格,以帮助计算机更快地计算位置。与许多其他投影不同,它基于球体而不是平面,因此没有间隙或重叠区域。您可以选择不同的级别来改变每个单元格的大小。使用此系统,计算机可以检查两个点之间相隔多少个单元格,以估计它们之间的距离。
在许多情况下,您可以从 S2 计算中获得的估计值足够精确,并且计算机的计算速度比三角学快得多。在您需要精确答案的情况下,使用 S2 几何仍然可以加快速度,因为计算机可以先获得粗略的估计值,然后仅执行真正需要的昂贵计算。
入门示例
在此示例中,我们将计算指定区域和不同时间窗口内海洋的平均表面温度,以及标准偏差。我们将在 Jupyter 笔记本中使用 InfluxDB 的 Python 客户端库工作。这里 和 其他一些 博客文章讨论了这些主题。
我通过 Anaconda 使用 Jupyter 笔记本,所以我的第一步是在 Anaconda 中安装 InfluxDB,方法是在命令窗口中键入以下内容。
conda install -c conda-forge influxdb然后,按照提示,我必须使用以下命令更新 anaconda:
conda update -n base -c defaults conda本示例中使用的文件是 NetCDF 格式,因此我还必须安装以下内容才能读取它:
conda install -c conda-forge netcdf4NetCDF 文件是科学数据的常用格式。本示例中使用的数据是 Roemmich-Gilson Argo 温度气候学数据,可从此处的页面上标题为“2004-2018 RG Argo Temperature Climatology”的第二个链接中获取。此数据来自数千个漂浮物在整个海洋中进行的不定期和不规则位置的测量,这些测量值被平均到网格化产品中,该产品在 1° 网格上具有月度值。
在您的 Jupyter 笔记本中,首先运行以下命令来导入本示例所需的各种包。
import matplotlib.pyplot as plt
import numpy as np
import datetime
import pandas as pd
import influxdb_client, os, time
from influxdb_client import InfluxDBClient, Point, WritePrecision, WriteOptions
from influxdb_client.client.write_api import SYNCHRONOUS
import netCDF4 as nc清理数据
运行以下命令以读取文件。
file_name = '/filepath/RG_ArgoClim_Temperature_2019.nc'
data_structure = nc.Dataset(file_name)如果您运行
print(data_structure.variables.keys())则以下应该是输出。
dict_keys(['LONGITUDE', 'LATITUDE', 'PRESSURE', 'TIME', 'ARGO_TEMPERATURE_MEAN', 'ARGO_TEMPERATURE_ANOMALY', 'BATHYMETRY_MASK', 'MAPPING_MASK'])这些是文件中的各种数组,用于存储数据。我们感兴趣的是 LONGITUDE、LATITUDE、TIME、ARGO_TEMPERATURE_MEAN 和 ARGO_TEMPERATURE_ANOMALY。要从文件中读取数据,请运行
lon = data_structure.variables['LONGITUDE']
lat = data_structure.variables['LATITUDE']
time = data_structure.variables['TIME']
temp_mean = data_structure.variables['ARGO_TEMPERATURE_MEAN']
temp_anom = data_structure.variables['ARGO_TEMPERATURE_ANOMALY']要查看每个数组的维度,请运行
print(lon.shape)
print(lat.shape)
print(time.shape)
print(temp_mean.shape)
print(temp_anom.shape)您应该看到
(360,)
(145,)
(180,)
(58, 145, 360)
(180, 58, 145, 360)有 360 个经度值、145 个纬度值和 180 个时间值。还有 58 个压力值。由于我们只对表面海洋温度感兴趣,而表面海洋温度是最低压力,因此我们将对数组进行子集化以取第一个压力索引。
您还会注意到,平均温度没有时间维度。此数据集将温度分为整个时间序列的平均值和每月与平均值的差异(称为异常值)。要获得每个月的实际温度,我们只需将平均值和异常值相加。
如果您尝试显示数组中随机点的值,您应该看到
temp_anom[0,0,0,0]
masked_array(data=1.082,
mask=False,
fill_value=1e+20,
dtype=float32)现在,每个值都在数组中,这是作为 netCDF 文件中的一部分。运行以下命令以获取值的简单数组
lon = lon[:]
lat = lat[:]
time = time[:]
temp_mean = temp_mean[:]
temp_anom = temp_anom[:]
temp_anom[0,0,0,0]
1.082时间单位是自数据集开始以来的月数。要创建可理解的日期时间向量,请运行以下命令。
time_pass=pd.date_range(start='1/1/2004', periods=180, freq='MS')要创建仅在表面的温度数组,请使用以下代码将第一个压力索引处的平均值和异常值数组相加。
ocean_surface_temp=np.empty((180,145,360))
for itime in range(180):
ocean_surface_temp[itime,:,:]=temp_mean[0,:,:]+temp_anom[itime,0,:,:]将数据写入 InfluxDB Cloud
现在我们想要的数据已放入格式良好的数组中,我们可以开始将其发送到 InfluxDB Cloud。为了节省存储空间,在此示例中,我们不打算上传全部内容,只上传来自大西洋 10 度 x 10 度框中的 10 年数据。我为此选择的坐标是北纬 15.5° 至北纬 25.5°,西经 34.5° 至西经 44.5°,或纬度指数 80 至 90 和经度指数 295 至 305。
为了最有效地将数据发送到 InfluxDB,我们将创建一个数据点数组。我们将每个点称为 ocean_temperature,并且该名称将设置为其测量值。
要在 InfluxDB 中使用地理时空包,您需要将数据与纬度和经度作为字段一起发送,因此我们的每个点都将具有纬度、经度和温度字段。在 InfluxDB 中,如果在同一时间戳有两个字段值,则您上传的下一个值将覆盖前一个值。这对我们来说是一个问题,因为我们的数据在同一时间具有多个纬度、经度和温度值。
防止数据被覆盖的一种简单方法是为每个点提供一个位置标签。在我们的数据中,在同一时间有很多测量值,但没有两个测量值在同一位置和时间。您可以为不想被覆盖的同一时间点的点开发其他唯一标签,如 此处 更详细的描述。
points_to_send = []
for itime in range(120):
for ilat in range(80, 90):
for ilon in range(295, 305):
p = Point("ocean_temperature")
p.tag("location", str(lat[ilat]) + str(lon[ilon]))
p.field("lat", lat[ilat])
p.field('lon', lon[ilon])
p.field('temp', ocean_surface_temp[itime,ilat,ilon])
p.time(time_pass[itime])
points_to_send.append(p)然后在 InfluxDB UI 中,从“加载数据”侧边栏创建一个存储桶和令牌,如这些屏幕截图所示。
您的 org 是您帐户的电子邮件,url 是您的云帐户的 url。
token=token
org = org
url = url
bucket = bucket在这里,我们将批处理大小设置为 5,000,因为这可以提高效率,如 此处 文档中所述。
with InfluxDBClient(url=url, token=token, org=org) as client:
with client.write_api(write_options=WriteOptions(batch_size=5000)) as write_api:
write_api.write(bucket=bucket, record=points_to_send)查询数据
现在数据已在 InfluxDB 中,我们可以查询它。我将使用几个查询来逐步向您展示每个命令的作用。首先,设置查询 API。
client = influxdb_client.InfluxDBClient(url=url, token=token, org=org)
query_api = client.query_api()在您的 Jupyter 笔记本中,每个查询都是一个 Flux 代码字符串,然后您使用查询 API 调用它。在所有这些情况下,我们有很多选项可以处理查询结果。对于前几个,我将打印前几个结果以确保它们正在工作,最后我们将以绘图结束。
此查询仅收集所有纬度、经度和温度字段。
query1='from(bucket: "sample_geo")\
|> range(start: 2003-12-31, stop: 2020-01-01)\
|> filter(fn: (r) => r["_measurement"] == "ocean_temperature")\
|> filter(fn: (r) => r["_field"] == "lat" or r["_field"] == "temp" or r["_field"] == "lon")\
|> yield(name: "all points")'此查询返回纬度。
query2='from(bucket: "sample_geo")\
|> range(start: 2003-12-31, stop: 2020-01-01)\
|> filter(fn: (r) => r["_measurement"] == "ocean_temperature")\
|> filter(fn: (r) => r["_field"] == "lat")\
|> yield(name: "lat")'要执行其中任一查询,并打印点的数量和前几个结果,您可以运行以下命令,更改您传入的查询。
result = client.query_api().query(org=org, query=query2)
results = []
for table in result:
for record in table.records:
results.append((record.get_value(), record.get_field()))
print(len(results))
print(results[0:10])现在我们将开始使用地理时空包。geo.shapeData 函数重新格式化数据并为每个点分配一个 S2 单元格 ID。您指定您的纬度和经度字段名称是什么,在本例中为“lat”和“lon”,以及您想要的 S2 单元格级别。在本例中,我选择了 10,它对应于平均 1.27 平方公里。您可以在此处阅读有关单元格级别的信息。
接下来,我们将使用 geo.filterRows 函数来选择我们要计算平均温度的区域。我选择了一个以北纬 20.5° 和西经 39.5° 为中心,半径 150 公里的圆形区域,但您可以选择任何类型的框、圆形或多边形,如 此处 所述。
默认情况下,数据按 s2_cell_id 分组,因此要计算整个区域的运行平均值,我们必须运行 group 函数并告诉它不按任何内容分组,以便区域中的所有数据都分组在一起。然后,您可以使用 aggregateWindow 函数来计算您选择的时间窗口的运行平均值和标准偏差。
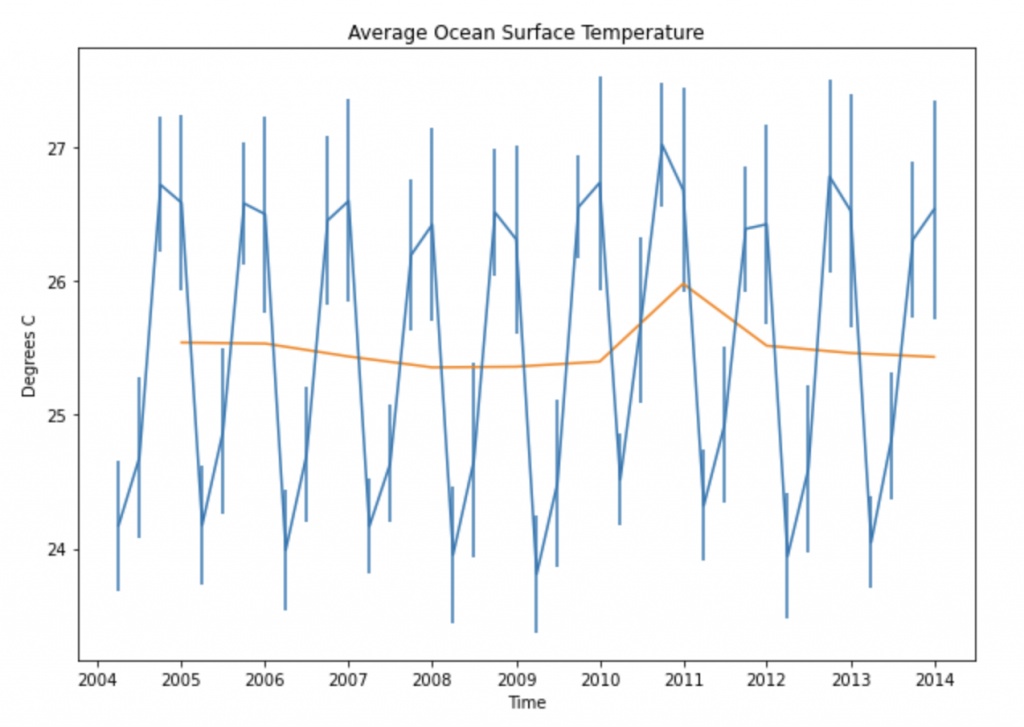
将所有这些放在一起,下面的代码计算并绘制了每三个月和每年此圆圈的平均值,以及每三个月的标准偏差,我将其作为下图中的误差条。
query3='import "experimental/geo"\
from(bucket: "sample_geo")\
|> range(start: 2003-12-31, stop: 2020-01-01)\
|> filter(fn: (r) => r["_measurement"] == "ocean_temperature")\
|> geo.shapeData(latField: "lat", lonField: "lon", level: 13)\
|> geo.filterRows(region: {lat: 20.5, lon: -39.5, radius: 150.0}, strict: true)\
|> group()\
|> aggregateWindow(column: "temp",every: 3mo, fn: mean, createEmpty: false)\
|> yield(name: "running mean")\
'
query4='import "experimental/geo"\
from(bucket: "sample_geo")\
|> range(start: 2003-12-31, stop: 2020-01-01)\
|> filter(fn: (r) => r["_measurement"] == "ocean_temperature")\
|> geo.shapeData(latField: "lat", lonField: "lon", level: 13)\
|> geo.filterRows(region: {lat: 20.5, lon: -39.5, radius: 150.0}, strict: true)\
|> group()\
|> aggregateWindow(column: "temp",every: 3mo, fn: stddev, createEmpty: false)\
|> yield(name: "standard deviation")\
'
query5='import "experimental/geo"\
from(bucket: "sample_geo")\
|> range(start: 2003-12-31, stop: 2020-01-01)\
|> filter(fn: (r) => r["_measurement"] == "ocean_temperature")\
|> geo.shapeData(latField: "lat", lonField: "lon", level: 13)\
|> geo.filterRows(region: {lat: 20.5, lon: -39.5, radius: 150.0}, strict: true)\
|> group()\
|> aggregateWindow(column: "temp",every: 12mo, fn: mean, createEmpty: false)\
|> yield(name: "running mean")\
'
result = client.query_api().query(org=org, query=query3)
results_mean = []
results_time = []
for table in result:
for record in table.records:
results_mean.append((record["temp"]))
results_time.append((record["_time"]))
result = client.query_api().query(org=org, query=query4)
results_stddev = []
for table in result:
for record in table.records:
results_stddev.append((record["temp"]))
result = client.query_api().query(org=org, query=query5)
results_mean_annual = []
results_time_annual = []
for table in result:
for record in table.records:
results_mean_annual.append((record["temp"]))
results_time_annual.append((record["_time"]))
plt.rcParams["figure.figsize"] = (10,7)
plt.errorbar(results_time,results_mean,results_stddev)
plt.plot(results_time_annual,results_mean_annual)
plt.xlabel("Time")
plt.ylabel("Degrees C")
plt.title("Average Ocean Surface Temperature")
更多资源
在 Python 中使用 InfluxDB 可以提高地理时空分析的效率。我希望您能从这个关于您可以使用此软件包进行的计算类型的示例中获得一些启发。这真的只是冰山一角。您还可以使用该软件包来计算距离、查找交叉点、查找某些区域是否包含特定点等等。并且它可以更有效地节省计算,尤其是在更复杂、点更多的数据集上。
专为 时间序列数据 构建的平台与 S2 单元格系统的结合非常强大。有关更多信息,您可以阅读我们文档中关于 Flux 地理时空包的信息 此处,并观看我们关于该主题的 Meet the Developers 迷你系列 此处。
