Java 和 InfluxDB 入门
作者:社区 / 产品, 用例, 开发者, 入门
2021 年 12 月 08 日
导航至
本文由 Reshma Sathe 撰写。向下滚动查看作者的照片和简介。
从物联网 (IoT) 设备的传感器到金融处理,时间序列数据正变得至关重要。从这些来源收集的数据可以帮助进行销售预测,并为营销和财务规划做出明智的决策。在本文中,您将了解 InfluxDB,它是目前可用的最高效的时间序列数据库之一,并探索如何将 InfluxDB 与 Java 结合使用。
时间序列基础知识
根据统计学家的说法,时间序列是通过在一段时间内重复测量获得的明确定义的数据项的观测集合。这些数据有助于我们分析和跟踪数据随时间的变化。时间序列数据的一些来源包括物联网 (IoT) 设备传感器、自动驾驶汽车、温度变化、股票市场价格,甚至每日上升和下降的 COVID-19 病例。
为了理解为什么时间序列数据很重要,请考虑以下示例
传统上,组织使用平均每日温度 (MDT) 指标来跟踪特定位置一段时间内的温度变化。对于特定位置,白天和夜间温度或导致温度变化的环境因素可能会发生巨大变化,但 MDT 可能仅略有变化。因此,MDT 不能准确反映全天的温度变化。相反,使用时间序列数据可以准确地描绘出温度每小时如何在特定条件下变化。它清晰地描绘出导致温度变化的环境因素,如降水、云层覆盖、风速等。所有这些信息都可以帮助组织更好地建模和优化其所在位置的能源利用率。
时间序列数据在提供对可用数据的深刻而有意义的见解以及帮助构建模式方面是不可估量的。然而,构建模式所需的数据量是巨大的,并且需要快速可靠的存储和检索以进行分析。这就是时间序列数据库 (TSDB) 的用武之地。
时间序列数据库 (TSDB)
时间序列数据库是专门为处理时间序列数据而设计的。时间序列数据可以使用“普通”数据库处理,但由于规模和可用性,TSDB 更受青睐。
- 规模:时间序列数据往往呈指数级增长。大多数非 TSDB 数据库未针对处理这种规模的变化进行优化。因此,它们的性能会下降,严重影响分析速率和整体应用程序速度。然而,TSDB 针对基于时间戳的数据进行了优化,因此可以对时间序列数据进行闪电般的快速插入和检索查询。
- 可用性:由于 TSDB 针对处理时间序列数据进行了优化,因此它们附带了许多内置功能,如时间聚合、连续查询、灵活的保留策略等。TSDB 简化了趋势分析,并具有更多选项。
这些是开发人员青睐 TSDB 的主要原因。事实上,根据 DB-Engines 的数据,TSDB 目前是数据库中增长最快的部分。
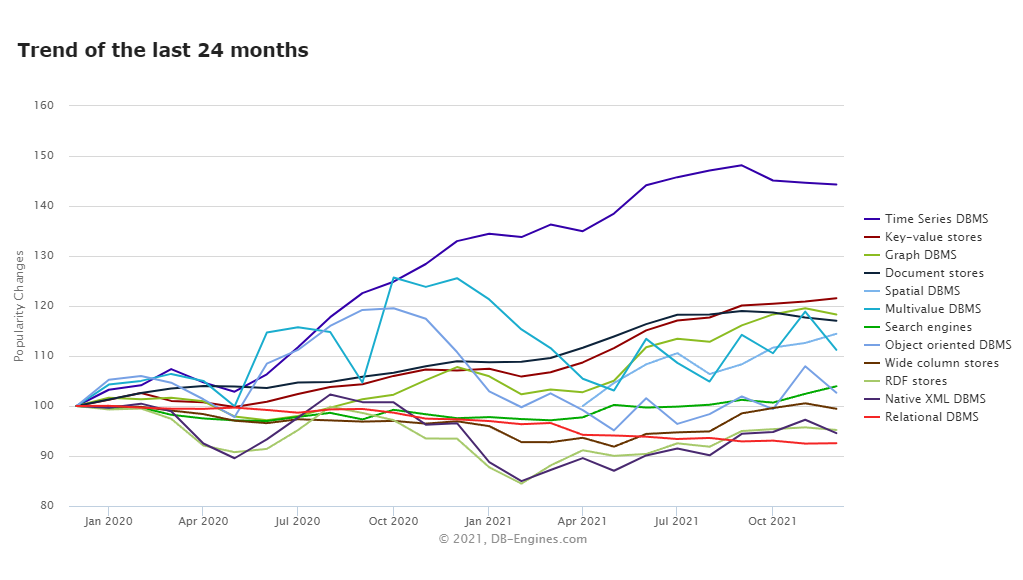
为什么选择 InfluxDB?
InfluxDB 是 InfluxData 的 TSDB。它具有支持数据收集、存储、监控和可视化的功能,并提供时间序列数据警报。InfluxDB 支持微秒和纳秒精度,这使其成为科学和金融分析的理想选择。
它具有出色的文档,其中包含所有功能的语法和示例。最新版本的 InfluxDB 2.0 提供对整个 Telegraf、InfluxDB、Chronograf 和 Kapacitor (TICK) 堆栈的支持。
InfluxDB 附带 Flux 语言,与 SQL 不同,Flux 是一种函数式语言,它使其更冗长、可读、可组合且更易于测试。其创建者 Paul Dix 给出了创建它的理由
“我不希望生活在一个人类能想到的用于处理数据的最佳语言是在 70 年代发明的世界里。”
由于 InfluxDB 提供对 TICK 堆栈的支持,因此 UI 附带“警报”和“仪表板”功能。还有一个集成的查询构建器,可以减少开发人员的工作量。
InfluxDB 客户端库
InfluxDB 支持与 Java、Kotlin、Scala、Python 和许多其他编程语言连接。要专门连接到 Java,请使用 InfluxDB Client Java 库。此客户端库取代了早期的 InfluxDB Java 库。完整的文档可在此处获得。
influxdb-client-java 需要 Java 版本高于 8.0 和 InfluxDB 版本 2.0。在开始使用客户端之前,您需要安装 InfluxDB 实例。设置 InfluxDB 的说明可以在其文档中找到。
假设 InfluxDB 已安装并在您的系统上设置,将 InfluxDB 客户端包含在 Java 应用程序中的最简单方法是通过 Maven。Maven 依赖项如下
<dependency>
<groupId>com.influxdb</groupId>
<artifactId>influxdb-client-java</artifactId>
<version>3.3.0</version>
</dependency>最新的 Maven 依赖项可在 Maven 仓库中找到。
一旦 InfluxDB 设置完成并且实例正在运行,您就可以在 UI 上创建用户、存储桶和组织。或者,您也可以使用客户端的 Management API。
示例应用程序
为了更好地理解如何使用 Influx Java 客户端,请查看以下示例应用程序。该示例应用程序有两个文件
App.java是主应用程序,负责所有调用。InfluxDBConnection.java负责所有 InfluxDB 调用,并将令牌、存储桶和 org 作为类成员。
应用程序代码可在 GitHub 上获取。
建立连接
要使用 Influx 客户端创建连接,请确保 InfluxDB 实例正在您的系统上运行。
在 Java 应用程序中,使用 InfluxDBClientFactory 类的 create() 方法建立连接。您需要为此方法提供 URL、组织名称、存储桶和令牌。
要生成令牌,请转到 InfluxDB 实例的 UI 并使用您的用户 ID 登录。为了更好地理解如何使用 InfluxDB UI,请参阅文档的“通过 UI 设置 InfluxDB”部分。
然后导航到“数据”表并单击“令牌”。在这里,您可以为您的用户生成令牌。生成的令牌用于连接到 InfluxDB 实例。
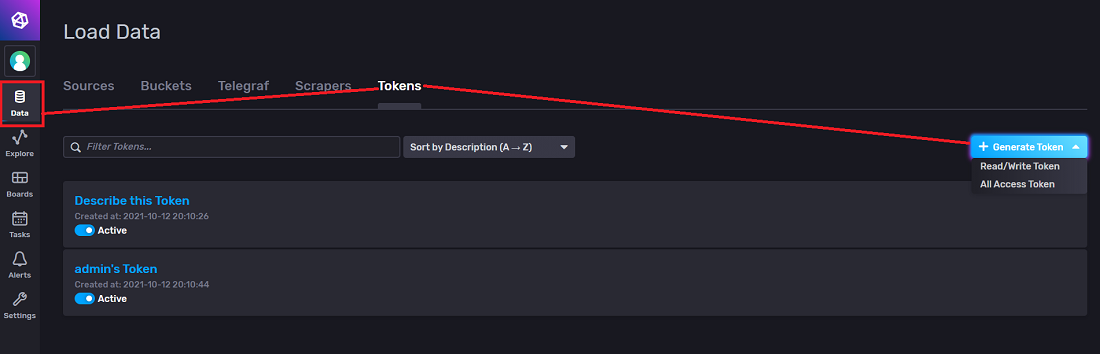
InfluxDB 建议至少有一个“完全访问”令牌,该令牌授予管理员权限。
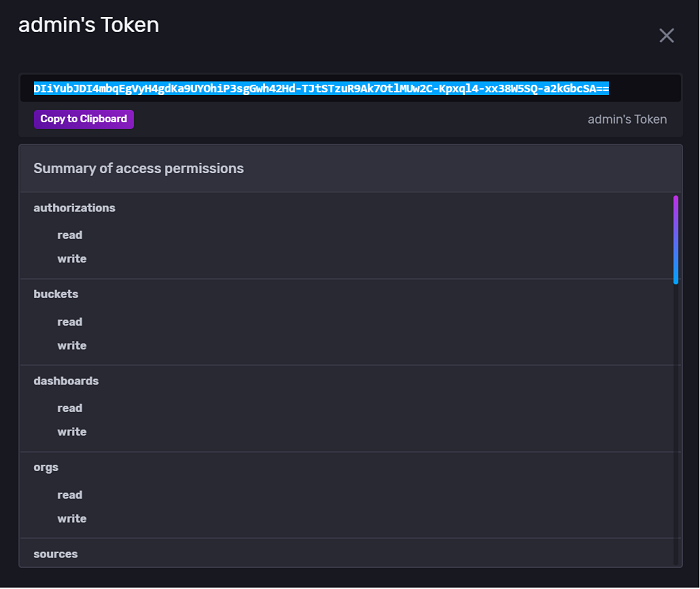
在示例应用程序中,您可以按如下方式在 InfluxDBConnectionClass 中构建连接
public InfluxDBClient buildConnection(String url, String token, String bucket, String org) {
setToken(token);
setBucket(bucket);
setOrg(org);
setUrl(url);
return InfluxDBClientFactory.create(getUrl(), getToken().toCharArray(), getOrg(), getBucket());
}插入数据
InfluxDB 客户端可以是同步阻塞 API 或异步阻塞 API。对于同步阻塞 API,InfluxDB 客户端提供 WriteApiBlocking API。
使用 WriteApiBlocking,您可以执行
- 单数据点插入
- 多点插入
- 使用 POJO 插入
要初始化 WriteApiBlocking,请使用以下命令
WriteApiBlocking writeApi = influxDBClient.getWriteApiBlocking();接下来,您可以创建一个单数据点并将其插入到 InfluxDB 中
Point point = Point.measurement("sensor").addTag("sensor_id", "TLM0100").addField("location", "Main Lobby")
.addField("model_number", "TLM89092A")
.time(Instant.now(), WritePrecision.MS);
writeApi.writePoint(point);您还可以构建一个多点列表并将该列表插入到 InfluxDB 中
WriteApiBlocking writeApi = influxDBClient.getWriteApiBlocking();
Point point1 = Point.measurement("sensor").addTag("sensor_id", "TLM0103")
.addField("location", "Mechanical Room").addField("model_number", "TLM90012Z")
.time(Instant.now(), WritePrecision.MS);
Point point2 = Point.measurement("sensor").addTag("sensor_id", "TLM0200")
.addField("location", "Conference Room").addField("model_number", "TLM89092B")
.time(Instant.now(), WritePrecision.MS);
Point point3 = Point.measurement("sensor").addTag("sensor_id", "TLM0201").addField("location", "Room 390")
.addField("model_number", "TLM89102B")
.time(Instant.now(), WritePrecision.MS);
List<Point> listPoint = new ArrayList<Point>();
listPoint.add(point1);
listPoint.add(point2);
listPoint.add(point3);
writeApi.writePoints(listPoint);最后,您还可以使用 POJO 插入数据
WriteApiBlocking writeApi = influxDBClient.getWriteApiBlocking();
Sensor sensor = new Sensor();
sensor.sensor_id = "TLM0101";
sensor.location = "Room 101";
sensor.model_number = "TLM89092A";
sensor.last_inspected = Instant.now();
writeApi.writeMeasurement(WritePrecision.MS, sensor);
flag = true;Measurement 是 POJO,需要定义为类
@Measurement(name = "sensor")
private static class Sensor {
@Column(tag = true)
String sensor_id;
@Column
String location;
@Column
String model_number;
@Column(timestamp = true)
Instant last_inspected;
}查询数据
InfluxDB 提供 Flux 用于查询数据。要查询数据库,请使用 Query API 和 query 方法来检索数据。在示例应用程序中,您将根据传感器 ID 检索传感器数据。
还有更多查询数据的示例;所有这些可能性都在 Query API 文档中讨论。
如果您想要所有记录,则范围应从 0 开始。具有特定传感器 ID 的查询在 Flux 中如下所示
String flux = String.format( "from(bucket:\"%s\") |> range(start:0) |> filter(fn: (r) => r[\"_measurement\"] == \"sensor\") |> filter(fn: (r) => r[\"sensor_id\"] == \"TLM0100\"or r[\"sensor_id\"] == \"TLM0101\" or r[\"sensor_id\"] == \"TLM0103\" or r[\"sensor_id\"] == \"TLM0200\") |> sort() |> yield(name: \"sort\")", getBucket());要触发上述 Flux 查询,influxdb-client 提供了 QueryApi,其中包含 query 方法。
QueryApi queryApi = influxDBClient.getQueryApi();
List<FluxTable> tables = queryApi.query(flux);
for (FluxTable fluxTable : tables) {
List<FluxRecord> records = fluxTable.getRecords();
for (FluxRecord fluxRecord : records) {
System.out.println(fluxRecord.getValueByKey("sensor_id"));
}
}删除数据点
要从 InfluxDB 存储桶中删除数据,请使用 DeleteAPI。一个绑定条件是删除查询应至少有一个时间戳。如果您不提及谓词,InfluxDB 将删除测量(表)中的所有数据。
要删除特定数据,请使用以下查询
DeleteApi deleteApi = influxDBClient.getDeleteApi();
try {
OffsetDateTime start = OffsetDateTime.now().minus(72, ChronoUnit.HOURS);
OffsetDateTime stop = OffsetDateTime.now();
String predicate = "_measurement=\"sensor\" AND sensor_id = \"TLM0201\"";
deleteApi.delete(start, stop, predicate,getBucket(), getOrg());
flag = true;
}结论
如您所见,时间序列数据对于更好地分析和获得有意义的见解至关重要。随着物联网 (IoT) 设备、自动驾驶汽车和其他更高效系统的出现,对时间序列数据的需求和范围正在增加。
与“传统”数据库相比,像 InfluxDB 这样专门设计和优化的时间序列数据库非常适合处理时间序列数据增长的量和速度。InfluxDB 以优化的方式管理时间序列数据,并提供闪电般的快速检索。其新的查询语言 Flux 使查询数据变得简单。Flux 是一种独立的、类似 JavaScript 的语言,其最有用的功能之一是它可以使用第三方 API 与不同的数据源和工具集成。因此,您可以非常轻松地将 InfluxDB 与第三方分析工具、数据源等连接起来。
根据应用程序的需要,您可以轻松集成 InfluxDB,无论您的应用程序是用 Java、Python、Kotlin、Scala 还是其他多种编程语言编写的。
在本文中,您学习了如何开始将 InfluxDB 与 Java 结合使用,并回顾了一些标准操作,例如使用 InfluxDB 客户端插入数据、查询数据等。
您可以向应用程序添加许多功能,例如创建和管理存储桶、为数据库应用程序设置运行状况检查、与 Telegraf 连接等。文档提供了出色的示例,是探索这些强大功能的最佳场所。
关于作者

Reshma 是伊利诺伊大学厄巴纳-香槟分校计算机科学硕士学位的应届毕业生,她热爱学习新事物。她曾担任软件工程师,参与的项目范围从生产支持到编程和软件工程。她目前正在从事 Java、Python、Angular、React 以及其他前端和后端技术的自驱动项目。
