InfluxDB API 入门
作者:社区 / 产品,用例,开发者,入门指南
2022年2月4日
导航至
本文由 Nicolas Bohorquez 撰写。向下滚动查看作者的照片和简介。
时间序列数据库(如 InfluxDB)按时间索引数据。它们非常高效地记录持续的数据流,例如服务器指标、应用程序监控数据、传感器报告以及任何包含时间戳的数据。
时间序列数据库中的数据始终使用最新的数据值写入,但之前的值不会更新。在传统的事务性方法中,您会更改实体模型的信息,但在时间序列数据库中,您可以保存随时间生成的所有数据点。
Telegraf 是 InfluxDB 首选的数据采集方式,但在某些情况下,您可能希望使用应用程序编程接口 (API) 来开发您的解决方案;例如,如果您需要在将数据放入时间序列数据库之前对其进行预处理,或者如果您没有找到与您的源系统兼容的 Telegraf 输入插件。
InfluxDB 包含了适用于最流行的编程语言(Python、Java、Go、Ruby 等)的 API 客户端,也可以直接与 REST API 一起使用。
在本教程中,您将学习如何通过 API 进行身份验证、读取数据流、将其作为时间序列存储到 InfluxDB 中,以及使用 InfluxDB 的 HTTP API 对数据运行查询。
在开始之前,您需要在您的操作系统上安装 InfluxDB 2.x 和一个 HTTP 客户端,例如 curl、httpie 或 Postman。本教程将展示如何在您的机器上使用本地 InfluxDB 实例,但您也可以使用 InfluxDB Cloud 以更快地开始,并且无需在您的机器上安装任何东西。
什么是时间序列数据库?
时间序列数据库是一种新型的专用数据存储,它要求数据模型包含基于时间的维度。
此类数据的一些示例包括:一天中特定时间的特定地理位置的温度、高峰时段穿越街道的人数,或应用程序每周的注册人数。
累积数据,具有小数据点和更高的时间粒度,是存储在时间序列数据库中的首选数据类型。以下是一些时间序列数据的示例
- 来自传感器的数据:可以记录特定动作的小型设备为时间序列数据提供了良好的来源。
- 金融数据:股票价格或金融资产的价值随时间变化,是时间序列数据的经典示例。
- 计算基础设施监控数据:随着云基础设施的增长,监控工具的数量也在增加,为每个组件的性能提供了许多数据点。
InfluxDB 是您可以用于此类数据的最佳工具之一,因为它允许您以一致且可扩展的方式捕获、存储和查询数据。
InfluxDB API
InfluxDB API(目前版本为 2.x)是一组 HTTP 端点,它提供对 InfluxDB 系统所有功能的编程访问。API 按资源和对这些资源的操作进行组织。
端点涵盖
- 系统信息:端点可以检查实例的状态、实例在启动时的就绪状态、实例的健康状况以及可用的顶级路由。
- 安全和访问:端点管理组织、用户和授权,这些授权为 API 访问提供令牌。这种基于令牌的安全方法提供了独立的对像(令牌),这些对象提供访问权限和管理组织的权限。
- 资源访问:端点可以管理存储桶、仪表板、任务和其他资源。
- 数据 I/O:端点对存储桶中的数据执行读写操作。
- 其他资源:端点允许您执行备份操作并管理其他 InfluxDB 资源,例如单元格、检查、标签和通知规则。
在本教程中,您将使用数据 I/O 端点来写入和查询 API,但在开始之前,您需要了解可用于调用 InfluxDB API 端点的不同身份验证方法。
身份验证类型
InfluxDB 中可以使用三种身份验证方法
_用户/密码_ 组合,也称为_基本身份验证_,您可以在其中发送编码的_用户:密码_字符串_查询字符串_ 方法使用两个 URL 编码的参数 (_u和p_)- 基于令牌的身份验证,这是首选方法
对于前两个选项,您需要生成用户名和密码;但对于本教程,您将使用基于令牌的身份验证,您可以从 InfluxDB UI 或使用 /api/v2/authorizations API 端点生成令牌。
建立连接
基于令牌的方法是首选方法,因为基本身份验证和查询字符串身份验证方法不支持令牌方案。
一旦您运行了 InfluxDB 安装,系统将提示您创建组织、用户和存储桶。
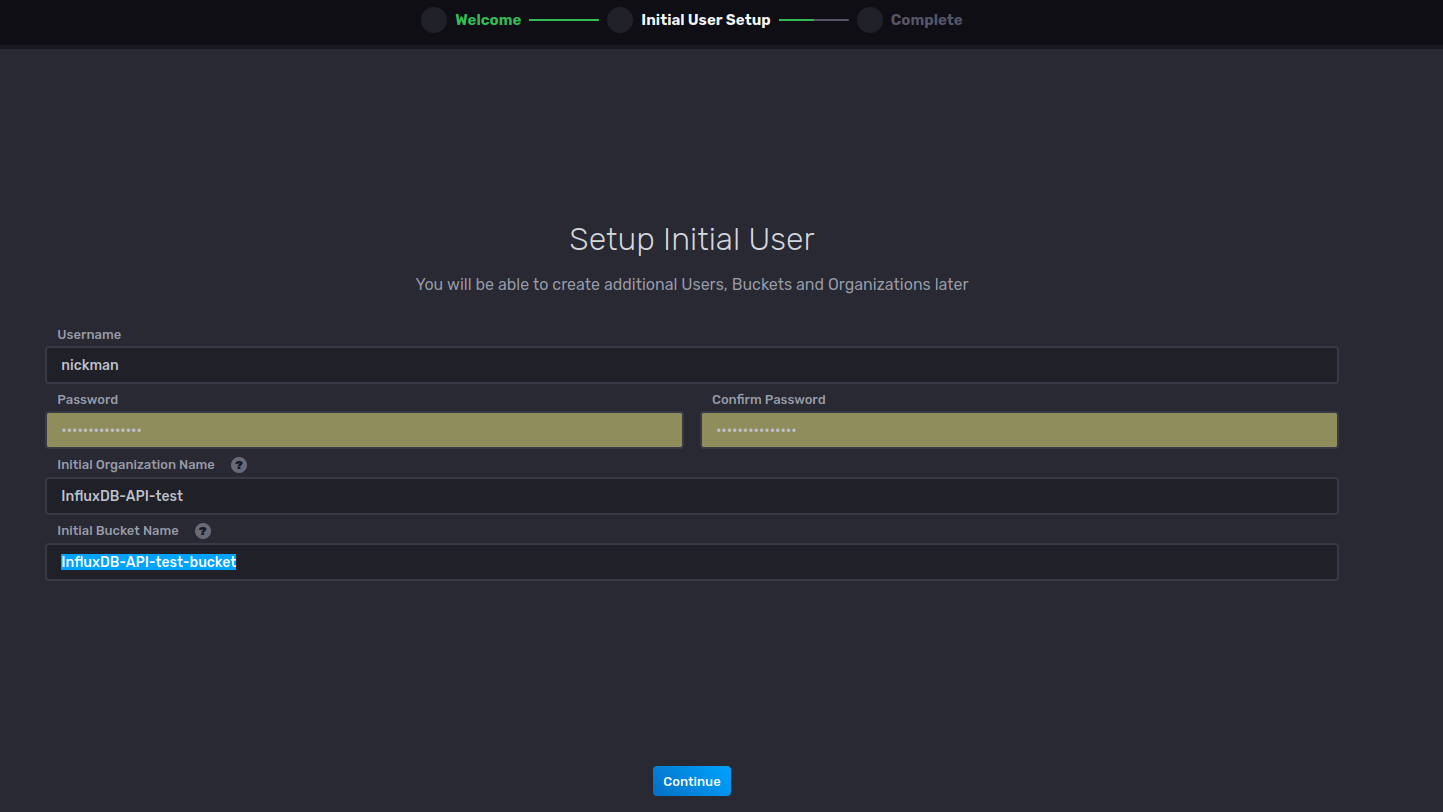
创建组织、用户和存储桶后,在 Web 用户界面的“加载数据”>“API 令牌”选项卡中检查自动创建的 API 令牌。
在此界面中,您还可以通过选择“生成 API 令牌”按钮来创建新令牌。在那里,您可以命名令牌并分配权限。
在本示例中,使用的令牌具有完全访问权限,但在生产环境中,您应该应用最小权限原则。
要测试您对 InfluxDB 实例的访问状态,请使用 _/ping_ 端点。例如,在下面的终端中使用 _curl_ 客户端
$ curl localhost:8086/health
您将获得一个 JSON 响应负载,其中包含本地服务器的状态和版本
{
"checks": [],
"commit": "657e1839de",
"message": "ready for queries and writes",
"name": "influxdb",
"status": "pass",
"version": "2.1.1"
}启用 TLS/SSL 加密
与任何其他开放外部访问的资源一样,您需要尝试最大限度地减少暴露数据时可能出现的潜在安全风险,即使在受控环境中也是如此。
您可以使用 SSL/TLS 加密 API 和消费者之间的通信,方法是获取证书(自签名或由证书颁发机构签名)并配置 InfluxDB 使用该证书来加密数据。
您可以按照 influxdata 的安全和授权说明 来启用 TLS/SSL 加密,这允许客户端验证 InfluxDB 服务器的真实性。
插入数据
要使用 API 插入数据,您将需要目标组织和存储桶。在本教程中,我们将使用此 数据集,其中包含全球 CO2 数据。确保您下载该文件并将其存储在您用于本教程的同一文件夹中。以下脚本将期望 CSV 文件位于同一目录中。
让我们使用 API 通过调用 _/api/v2/buckets_ 端点来检查所有可用的存储桶
curl https://:8086/api/v2/buckets --header "Authorization: Token your_api_token"
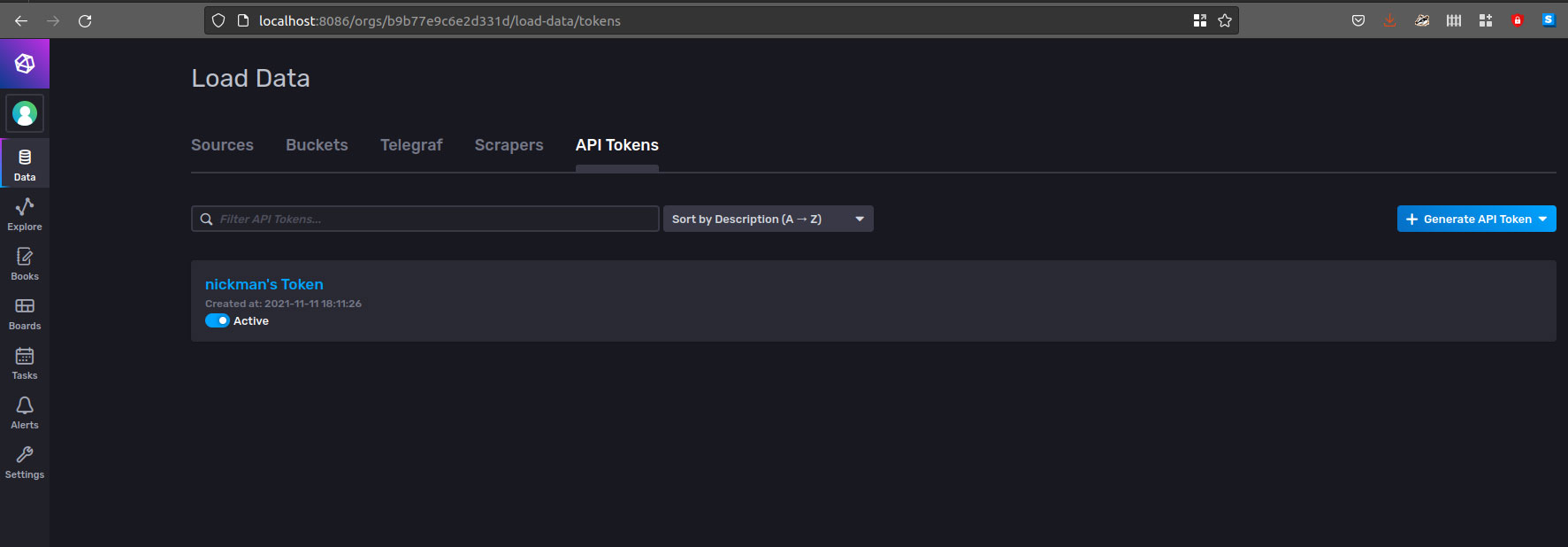
JSON 响应至少包含三个存储桶。先前显示的设置屏幕 _InfluxDB-API-test-bucket_ 是最初配置的存储桶,也是我们测试的目标。
{
"id": "81fef1d4510e235d",
"orgID": "b9b77e9c6e2d331d",
"type": "user",
"name": "InfluxDB-API-test-bucket",
"retentionRules": [
{
"type": "expire",
"everySeconds": 0,
"shardGroupDurationSeconds": 604800
}
],
"createdAt": "2021-11-11T23:11:26.588182068Z",
"updatedAt": "2021-11-11T23:11:26.588182158Z",
"links": {
"labels": "/api/v2/buckets/81fef1d4510e235d/labels",
"members": "/api/v2/buckets/81fef1d4510e235d/members",
"org": "/api/v2/orgs/b9b77e9c6e2d331d",
"owners": "/api/v2/buckets/81fef1d4510e235d/owners",
"self": "/api/v2/buckets/81fef1d4510e235d",
"write": "/api/v2/write?org=b9b77e9c6e2d331d\u0026bucket=81fef1d4510e235d"
},
"labels": []
}|保存 orgID 值,以便在以下请求中用作参数。
现在,使用一个开放数据集将数据写入存储桶:自 1751 年以来全球化石燃料的 CO2 排放量。此存储桶包含二氧化碳信息分析中心汇编的 266 年的碳排放数据。通过一个简单的 bash 脚本,您可以读取文件,打印每年最有趣的值,并将数据写入 InfluxDB 存储桶。
首先,让我们创建一个简单的 write.sh bash 脚本
#! /bin/bash
#1. iterates over the global_emissions.csv file and reads each comma-separated column
while IFS="," read -r Year Total GasFuel LiquidFuel SolidFuel Cement GasFlaring PerCapita
do
echo "Year: $Year , total: $Total , Per capita $PerCapita"
#2. Converts the value of the year into a UNIX timestamp
ts=`date "+%s" -u -d "Dec 31 $Year 23:59:59"`
#3. Inserts the total value of co2 per year
curl -i -XPOST "https://:8086/api/v2/write?precision=s&orgID=$1&bucket=$2" \
--header "Authorization: Token $3" \
--data-raw "total_co2,source=CDIAC value=$Total $ts"
#4. Checks if there is a value per capita
if [ -z "$PerCapita" ]; then
PerCapita=0
fi
#5. Inserts the per capita value of co2 emissions per year
curl -i -XPOST "https://:8086/api/v2/write?precision=s&orgID=$1&bucket=$2" \
--header "Authorization: Token $3" \
--data-raw "per_capita_co2,source=CDIAC value=$PerCapita $ts"
done < <(tail -n +2 global_emissions.csv)上面的脚本执行以下操作
- 迭代
global_emissions.csv文件并读取每个逗号分隔的列 - 将年份的值转换为 UNIX 时间戳
- 插入每年 CO2 的总值
- 检查是否存在人均值
- 插入每年人均 CO2 排放量的值
您可以使用终端调用此脚本,并传递三个空格分隔的参数:组织 ID(之前保存的 orgID)、存储桶的名称和之前使用的 API 令牌。
请注意,前面的脚本在与脚本相同的文件夹中查找 global_emissions.csv 文件。
一旦您将源文件和脚本放在一起,您可以使用以下命令运行它
./write.sh b9b77e9c6e2d331d InfluxDB-API-test-bucket your_api_token
输出应如下面的代码所示,这是每次 API 调用返回的 HTTP 204 响应代码。
HTTP/1.1 204 No Content
X-Influxdb-Build: OSS
X-Influxdb-Version: 2.1.1
Date: Fri, 12 Nov 2021 00:05:44 GMT请注意 InfluxDB /api/v2/write 端点的调用。如 文档所述,它需要 precision、organization 和 bucket 查询参数,并期望负载遵循 InfluxDB 行协议。
此协议是一种基于文本的数据表示形式,包含四个组件
- Measurement(测量):您正在测量的对象
- Tag set(标签集):如何标识测量
- Field set(字段集):与测量关联的一组值(在本例中,只有一个)
- Timestamp(时间戳):上次测量的时间
使用此格式,您可以表达复杂的时间序列数据。在本示例中,只有 total co2 和 per capita co2 测量值被写入存储桶。
查询数据
与写入操作类似,有一个 query 端点,它接受以 Flux 语言(这是一种简洁且功能强大的语言,专为查询、分析和处理数据而设计)编写的查询作为负载。您还将使用之前保存的 orgID 值作为查询参数来调用端点。
然后,一个查询生成一个 CSV 结果,其中包含 2000 年至 2015 年期间每五年 total co2 的平均值
curl --request POST \
https://:8086/api/v2/query?orgID=your_org_id \
--header 'Authorization: Token your_api_token' \
--header 'Accept: application/csv' \
--header 'Content-type: application/vnd.flux' \
--data 'from(bucket:"InfluxDB-API-test-bucket")
|> range(start: 2000-12-31T00:00:00Z, stop: 2015-01-01T00:00:00Z)
|> filter(fn: (r) => r._measurement == "total_co2")
|> aggregateWindow(every: 5y, fn: mean)'/api/v2/query 可以使用请求中的附加标头压缩结果。
您还可以包含一组键/值对,这些键/值对表示要注入到查询中的参数,甚至可以将结果作为特定的 CSV 方言 获取。这使得提取数据成为一项简单的任务,其中您的创造力和 Flux 语言的知识是驱动力。
如果您有 InfluxDB v1.x 数据库,您也可以使用 InfluxDB v2.x API 查询您的数据。首先,请务必验证数据库和保留策略是否已使用 /api/v2/dbrps 端点映射到存储桶以列出和创建 必要的 映射,然后使用 API 启动查询
curl --request GET \
https://:8086/api/v2/query?orgID=your_org_id \
--header 'Authorization: Token your_token' \
--header 'Accept: application/csv' \
--header 'Content-type: application/json' \
--data-urlencode "q=SELECT mean(*) FROM example-db.example-rp.total_co2"鉴于本教程使用 InfluxDB v2.x 数据库,您无法使用当前设置直接测试此 InfluxQL 示例。但它对于与以前版本的兼容性测试非常有用。
您在使用像 InfluxDB 这样的时间序列数据库时可能遇到的常见错误是尝试按照关系范式设计您的解决方案。InfluxDB 的文档提供了 最佳实践,用于时间序列用例中的模式设计,您应该在开始建模之前查看这些实践。
结论
在本教程中,您学习了 InfluxDB HTTP API 的基本用法、如何进行身份验证和测试 InfluxDB 实例中 API 的可用性,以及如何使用 write 端点使用行协议发送数据。
您还学习了如何通过使用 Flux 语言进行查询来读取数据。使用的脚本和数据可在 GitHub Gist 中找到。
InfluxDB HTTP API 为您提供了大量可以以编程方式使用的资源和操作,从而增加了灵活性和与任何编程语言的兼容性。您可以使用任何 InfluxDB 安装方法 在本地部署 InfluxDB HTTP API,或者您可以尝试 InfluxData 平台以获得托管环境的所有优势。
请记住,您还可以使用适用于许多流行语言的 API 客户端。
关于作者

Nicolas Bohorquez 是 Merqueo 的数据架构师,曾是多家初创公司开发团队的成员,并在美洲创立了三家公司。他热衷于复杂性建模以及使用数据科学来改善世界。
