Apache Kafka 和 InfluxDB 入门
作者:社区 / 开发者, 产品, 入门
2022 年 9 月 29 日
导航至
本文由 Aykut Bulgu 撰写。向下滚动查看他的简介和照片。
随着越来越多的应用程序架构转向微服务或无服务器结构,应用程序和服务的数量每天都在增加。您可以使用实时聚合或输出为度量或指标的计算来处理不断增长的时间序列数据量。这些指标需要被监控,以便您可以快速解决问题并对系统进行相关更改。
系统中的更改可以通过多种方式捕获和观察。最流行的一种方式,尤其是在云原生环境中,是使用事件。
事件驱动系统已成为创建松耦合分布式系统的标准。您可以以事件驱动的方式(例如 事件溯源、变更数据捕获 (CDC) 等)收集应用程序指标、度量或日志,并将它们发送到消息传递骨干网,以便被另一个资源(如数据库或可观测性工具)使用。在这种情况下,持久性和性能非常重要,而传统的消息代理通常不提供这些功能。
相反,Apache Kafka 是一个持久、高性能的消息传递系统,也被认为是分布式流处理平台。Apache Kafka 可以应用于许多用例,包括消息传递、数据集成、日志聚合和指标。
当涉及到指标时,拥有消息传递骨干网或代理是不够的。虽然 Apache Kafka 是持久的,但它并非旨在运行指标和监控查询。这就是 InfluxDB 发挥作用的地方。
InfluxDB 是一个时间序列数据库 (TSDB),它为监控、应用程序指标、物联网 (IoT) 传感器数据和实时分析提供存储和时间序列数据检索。它可以与 Apache Kafka 集成,以发送或接收指标或事件数据,用于处理和监控。
在本教程中,您将了解 Apache Kafka 和 InfluxDB。您还将了解如何将它们一起使用来创建任务和警报,以及通过客户端查询数据。
先决条件
要完成本教程,您需要以下内容
- 安装了 Homebrew 的 macOS 环境。
- 最新版本的 Docker。(在撰写本文时,使用了 Docker Desktop 4.6.1。)
- 最新版本的 Docker Compose(此处使用了 2.3.3 版本)。
- Python 3.8 或更高版本。
要继续学习,您可以使用此 GitHub 存储库。
背景信息:IoT SaaS
在本文中,您将了解一家名为 InfluxGarden 的虚构物联网软件公司,该公司为园艺公司提供服务。最近,他们需要一位软件开发专家将 Apache Kafka 与他们的 InfluxDB 系统集成,他们计划将其作为软件即服务 (SaaS) 平台提供。
InfluxGarden 拥有测量湿度、温度、土壤和风等事物的传感器。在本文中,您将从模拟应用程序收集数据,然后将数据发送到 Apache Kafka,以便 InfluxDB 读取并在其数据浏览器界面上显示。
整体应用程序架构将如下所示
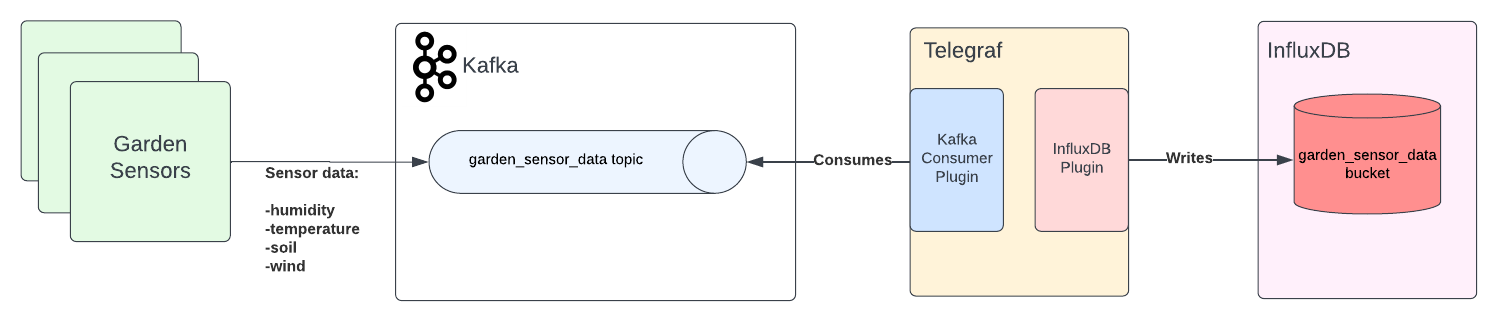
什么是 Apache Kafka?
如前所述,Apache Kafka 是一个开源分布式流处理平台,它最初是作为高性能消息传递系统创建的,并且已被 超过 80% 的财富 100 强公司 使用。
Apache Kafka 以其高吞吐量和低延迟而闻名。它可以用于多种方式,包括以下几种
-
消息传递: Apache Kafka 替代了许多(尤其是基于 Java 的)传统消息传递系统,包括 ActiveMQ 和 RabbitMQ。
-
流处理: 它通过存储实时事件以进行聚合、丰富和处理来提供事件骨干网。
-
指标: Apache Kafka 成为许多分布式组件或应用程序(如微服务)的集中聚合点。这些应用程序可以发送实时指标,以便被包括 InfluxDB 在内的其他平台使用。
-
数据集成: 数据和事件更改可以被捕获并发送到 Apache Kafka,在那里它们被任何需要对这些更改采取行动的应用程序使用。
-
日志聚合: Apache Kafka 可以充当日志流平台的 messaging backbone,该平台将日志块转换为数据流。
安装后,Apache Kafka 形成一个集群,该集群由 brokers 和 Zookeeper 实例组成。 Zookeeper 是一个第三方开源平台,它与 Apache Kafka 项目分开开发。它是 Apache Kafka 用于选择控制器 broker 等任务的依赖项。
Kafka 社区一直在努力摆脱这种依赖,并在其最新版本中具有无 Zookeeper 模式(目前,这些版本尚未准备好用于生产)。
有关此方面的更多信息,请参阅 Apache Kafka 改进提案 (KIP-500)。
broker 通常指的是 Apache Kafka 服务器实例,它是 Kafka 集群的一部分。为了实现水平可扩展性和可用性,brokers 必须在不同的机器上运行,其中一个 broker 成为控制器。有关 Apache Kafka 结构的更多信息,请参阅 官方 Apache Kafka 文档。
Apache Kafka 具有 topics,它们是逻辑存储单元,就像关系数据库的表一样。Topics 通过分区分布在 brokers 中,从而提供可扩展性和弹性。
当客户端向 Apache Kafka 集群实例发送数据时,它必须将其发送到 topic。
此外,当客户端从 Apache Kafka 集群读取数据时,它必须从 topic 中读取。将数据发送到 Apache Kafka 的客户端成为生产者,而从 Kafka 集群读取数据的客户端成为消费者。
与传统消息传递平台不同,在 Apache Kafka 中,brokers 是“哑”的,但生产者和消费者是“智能”的。这意味着 brokers 仅配置为在特定保留时间内保留数据;除此之外,所有复杂的配置都在客户端(生产者和消费者)上完成。

当您从 Apache Kafka topic 中消费消息时,该消息不会被删除。只要消息存储在 brokers 中,您就可以重新消费任何消息,具体取决于保留配置。这是 Apache Kafka 的重放机制,对于许多用例(包括事件驱动架构)非常重要。
什么是 InfluxDB?
TSDB 是一个为时间序列 数据 优化的数据库,时间序列数据是在一段时间内跟踪、监控和聚合的指标或事件。这些指标和事件与时间戳一起保存在 TSDB 中。
InfluxDB 专门为监控、应用程序指标、IoT、传感器数据和 实时分析 中的时间序列数据而创建。它可以与第三方数据存储(如 MongoDB、Elasticsearch、API、服务和消息队列)集成,以便发送和接收指标数据。
InfluxDB 提供了一个插件驱动的服务器代理,称为 Telegraf,它可以从任何受支持的源收集和报告指标,并将数据馈送到 InfluxDB 或反之亦然。
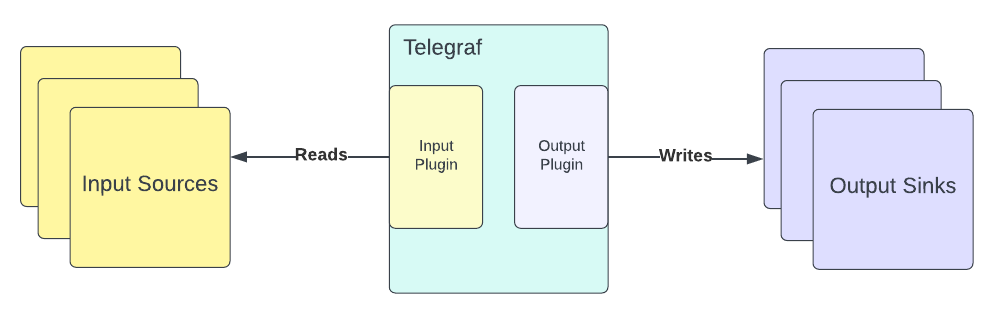
Telegraf 可以作为 Linux 上的 sysvinit 或 systemd 服务启动,也可以作为终端命令运行。
Telegraf 具有 输入和输出插件,必须在启动前预先配置。例如,它有一个 Apache Kafka 消费者输入插件,可以从 Kafka topic 读取消息,还有一个输出插件,可以帮助将任何输入数据写入 InfluxDB。在这里,您将使用 Telegraf 的这些插件。
运行 Apache Kafka
在本教程中,您将在容器中运行 Apache Kafka。首先,下载 Docker compose YAML 文件,其中包含 Apache Kafka 及其依赖项 Zookeeper 的配置。compose 文件使用基于 Strimzi 的容器镜像。
文件内容应如下所示
version: '3.3'
services:
zookeeper:
container_name: zookeeper
image: quay.io/strimzi/kafka:0.28.0-kafka-3.1.0
command: [
"sh", "-c",
"bin/zookeeper-server-start.sh config/zookeeper.properties"
]
ports:
- "2181:2181"
environment:
LOG_DIR: /tmp/logs
kafka:
container_name: kafka
image: quay.io/strimzi/kafka:0.28.0-kafka-3.1.0
command: [
"sh", "-c",
"bin/kafka-server-start.sh config/server.properties --override listeners=$${KAFKA_LISTENERS} --override advertised.listeners=$${KAFKA_ADVERTISED_LISTENERS} --override zookeeper.connect=$${KAFKA_ZOOKEEPER_CONNECT}"
]
depends_on:
- zookeeper
ports:
- "9092:9092"
environment:
LOG_DIR: "/tmp/logs"
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://:9092
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
influxdb:
container_name: influxdb
ports:
- '8086:8086'
image: 'docker.io/influxdb:2.2.0'在您的主目录中,创建一个名为 influxgarden_integration 的文件夹,并将该文件放入其中,命名为 docker-compose.yaml。
然后打开一个终端窗口并运行以下命令以在您的机器上执行 Apache Kafka
docker-compose -f '_YOUR_HOME_DIRECTORY_/influxgarden_integration/docker-compose.yaml' up输出应如下所示
['podman', '--version', '']
using podman version: 4.1.0
** excluding: set()
['podman', 'network', 'exists', 'kafka_default']
podman create --name=zookeeper --label io.podman.compose.config-hash=123 --label io.podman.compose.project=kafka --label io.podman.compose.version=0.0.1 --label com.docker.compose.project=kafka --label com.docker.compose.project.working_dir=/Users/mabulgu/github-repos/systemcraftsman/influxdb-kafka-demo/resources/kafka --label com.docker.compose.project.config_files=/Users/mabulgu/github-repos/systemcraftsman/influxdb-kafka-demo/resources/kafka/docker-compose.yaml --label com.docker.compose.container-number=1 --label com.docker.compose.service=zookeeper -e LOG_DIR=/tmp/logs --net kafka_default --network-alias zookeeper -p 2181:2181 quay.io/strimzi/kafka:0.28.0-kafka-3.1.0 sh -c bin/zookeeper-server-start.sh config/zookeeper.properties
9f3a20f17ab9c4ec2214649f3d92a70fd60790f7cc31d0b2493db83db78809aa
exit code: 0
['podman', 'network', 'exists', 'kafka_default']
podman create --name=kafka --label io.podman.compose.config-hash=123 --label io.podman.compose.project=kafka --label io.podman.compose.version=0.0.1 --label com.docker.compose.project=kafka --label com.docker.compose.project.working_dir=/Users/mabulgu/github-repos/systemcraftsman/influxdb-kafka-demo/resources/kafka --label com.docker.compose.project.config_files=/Users/mabulgu/github-repos/systemcraftsman/influxdb-kafka-demo/resources/kafka/docker-compose.yaml --label com.docker.compose.container-number=1 --label com.docker.compose.service=kafka -e LOG_DIR=/tmp/logs -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -e KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 --net kafka_default --network-alias kafka -p 9092:9092 quay.io/strimzi/kafka:0.28.0-kafka-3.1.0 sh -c bin/kafka-server-start.sh config/server.properties --override listeners=${KAFKA_LISTENERS} --override advertised.listeners=${KAFKA_ADVERTISED_LISTENERS} --override zookeeper.connect=${KAFKA_ZOOKEEPER_CONNECT}
d3a8b43e84b810d757da603301216a84c5f7a22c0ff09183f7d3a78bf347b4ea
exit code: 0
podman start -a zookeeper
podman start -a kafka
...output omitted...
[2022-05-22 13:56:20,717] INFO [KafkaServer id=0] started (kafka.server.KafkaServer)
[2022-05-22 13:56:20,792] INFO [BrokerToControllerChannelManager broker=0 name=alterIsr]: Recorded new controller, from now on will use broker localhost:9092 (id: 0 rack: null) (kafka.server.BrokerToControllerRequestThread)
[2022-05-22 13:56:20,841] INFO [BrokerToControllerChannelManager broker=0 name=forwarding]: Recorded new controller, from now on will use broker localhost:9092 (id: 0 rack: null) (kafka.server.BrokerToControllerRequestThread)现在您需要打开一个新的终端窗口并运行以下命令来验证 Apache Kafka 和 Zookeeper 实例是否正在运行
docker ps9f3a20f17ab9 quay.io/strimzi/kafka:0.28.0-kafka-3.1.0 sh -c bin/zookeep... 3 minutes ago Up 3 minutes ago 0.0.0.0:2181->2181/tcp zookeeper
d3a8b43e84b8 quay.io/strimzi/kafka:0.28.0-kafka-3.1.0 sh -c bin/kafka-s... 3 minutes ago Up 3 minutes ago 0.0.0.0:9092->9092/tcp kafka前面的输出显示 Apache Kafka 集群工作正常。
运行 InfluxDB
在本教程中,您还将通过 Docker 在容器中运行 InfluxDB。
有关在其他平台上安装 InfluxDB 的更多信息,请参阅 此文档。
一旦您在 macOS 环境中的 Docker 守护程序上安装并启动了 Docker,您需要打开一个新的终端窗口并运行以下命令来启动 InfluxDB
docker run -d --name influxdb -p 8086:8086 docker.io/influxdb:2.2.0在您的 Web 浏览器中,导航到 localhost:8086 以验证安装

选择 Get Started 按钮并按照提示输入信息
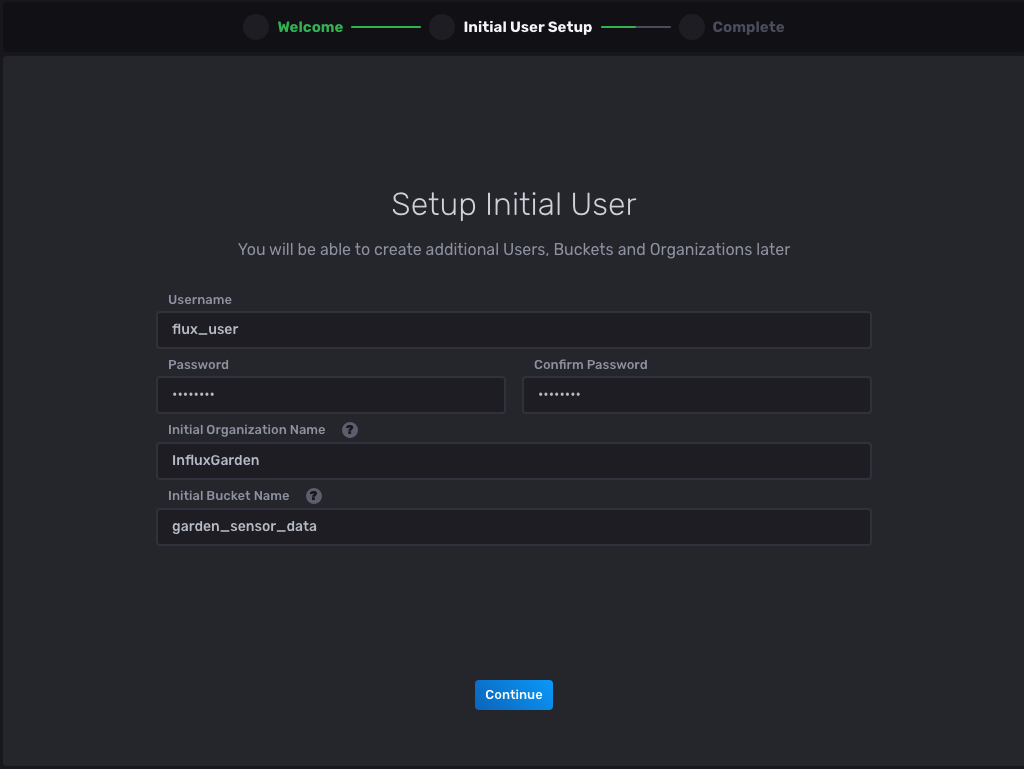
现在选择 Continue,您应该被重定向到下一页以完成设置
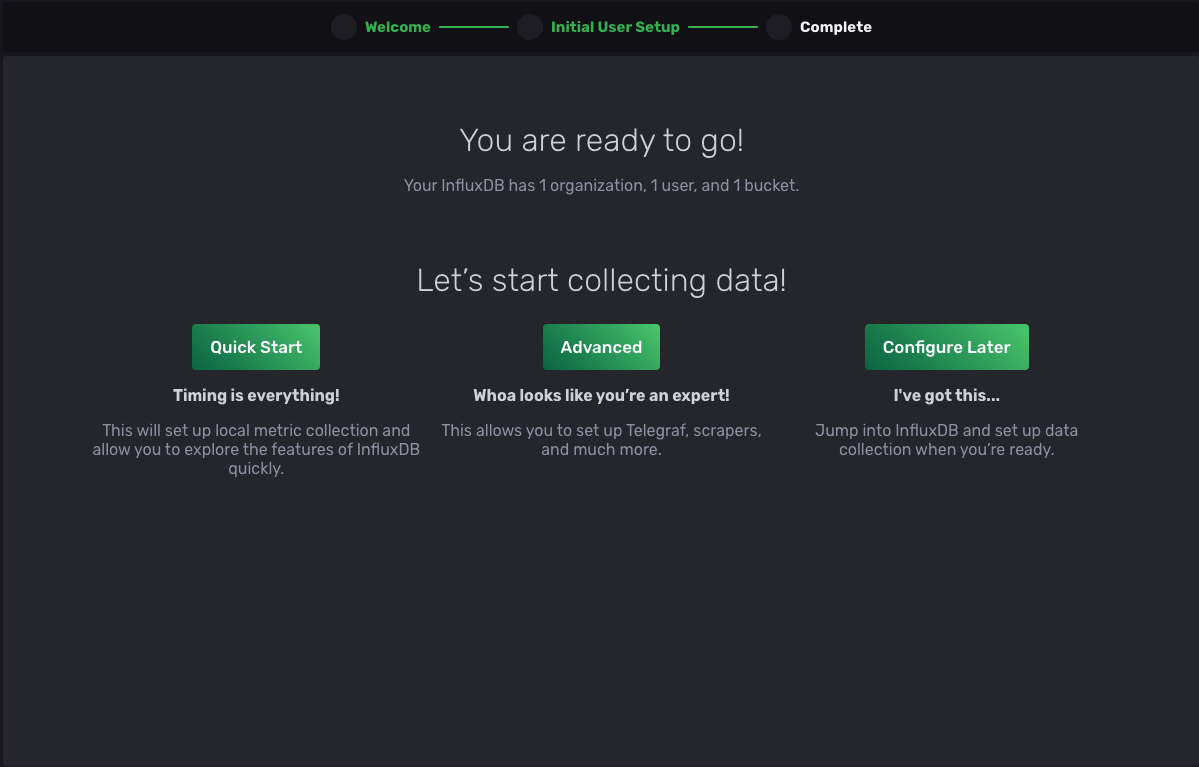
完成后,选择 Advanced,您将被重定向到 Load Data 页面,并选择 Buckets 选项卡。请注意,bucket garden_sensor_data 在列表中可用,并保持页面打开,因为您稍后在本教程中需要它。
安装、配置和运行 Telegraf
要在 macOS 上安装 Telegraf,请打开一个新的终端窗口并运行以下命令
brew install telegraf如先决条件中所述,您需要安装 Homebrew 才能完成此步骤。有关其他平台上其他安装选项,您可以参阅 此文档。
安装 Telegraf 后,您需要对其进行配置,以便集成 InfluxDB 和 Apache Kafka。
导航回您之前导航到的 InfluxDB Load Data 页面,然后单击 Telegraf > InfluxDB Output Plugin
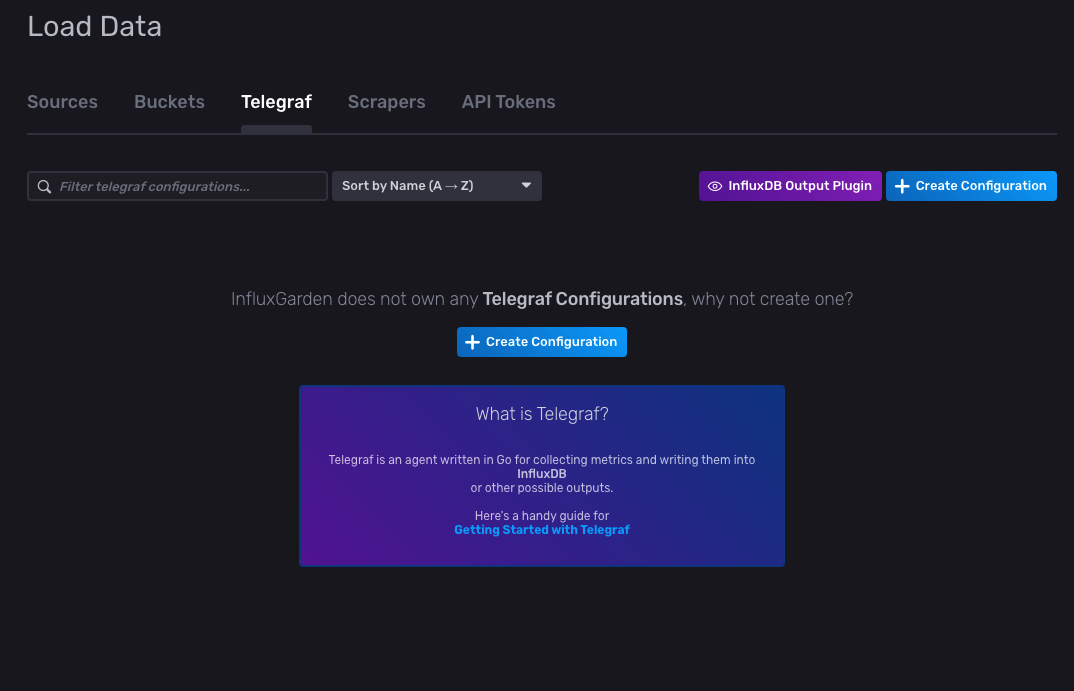
选择 InfluxDB Output Plugin 后,应打开一个配置弹出窗口,向您显示输出配置
[[outputs.influxdb_v2]]
## The URLs of the InfluxDB cluster nodes.
##
## Multiple URLs can be specified for a single cluster, only ONE of the
## urls will be written to each interval.
## ex: urls = ["https://us-west-2-1.aws.cloud2.influxdata.com"]
urls = ["https://:8086"]
## API token for authentication.
token = "$INFLUX_TOKEN"
## Organization is the name of the organization you wish to write to; must exist.
organization = "InfluxGarden"
## Destination bucket to write into.
bucket = "garden_sensor_data"
## The value of this tag will be used to determine the bucket. If this
## tag is not set the 'bucket' option is used as the default.
# bucket_tag = ""
## If true, the bucket tag will not be added to the metric.
# exclude_bucket_tag = false
## Timeout for HTTP messages.
# timeout = "5s"
## Additional HTTP headers
# http_headers = {"X-Special-Header" = "Special-Value"}
## HTTP Proxy override, if unset values the standard proxy environment
## variables are consulted to determine which proxy, if any, should be used.
# http_proxy = "http://corporate.proxy:3128"
## HTTP User-Agent
# user_agent = "telegraf"
## Content-Encoding for write request body, can be set to "gzip" to
## compress body or "identity" to apply no encoding.
# content_encoding = "gzip"
## Enable or disable uint support for writing uints influxdb 2.0.
# influx_uint_support = false
## Optional TLS Config for use on HTTP connections.
# tls_ca = "/etc/telegraf/ca.pem"
# tls_cert = "/etc/telegraf/cert.pem"
# tls_key = "/etc/telegraf/key.pem"
## Use TLS but skip chain & host verification
# insecure_skip_verify = false请注意,组织和 bucket 名称已在配置中设置。
在 influxgarden_integration 目录中创建一个名为 telegraf.conf 的文件,并将前面的配置复制到其中。通过在配置文件中添加 outputs 注释,您正在将 Telegraf 与 InfluxDB 集成。
要从源获取数据并通过 Telegraf 将其发送到 InfluxDB,您还需要在同一配置文件中添加输入配置。
将以下输入配置附加到您创建的 telegraf.conf 文件
[[inputs.kafka_consumer]]
## Kafka brokers.
brokers = ["localhost:9092"]
## Topics to consume.
topics = ["garden_sensor_data"]
## When set this tag will be added to all metrics with the topic as the value.
# topic_tag = ""
## Optional Client id
# client_id = "Telegraf"
## Set the minimal supported Kafka version. Setting this enables the use of new
## Kafka features and APIs. Must be 0.10.2.0 or greater.
## ex: version = "1.1.0"
# version = ""
## Optional TLS Config
# tls_ca = "/etc/telegraf/ca.pem"
# tls_cert = "/etc/telegraf/cert.pem"
# tls_key = "/etc/telegraf/key.pem"
## Use TLS but skip chain & host verification
# insecure_skip_verify = false
## SASL authentication credentials. These settings should typically be used
## with TLS encryption enabled
# sasl_username = "kafka"
# sasl_password = "secret"
## Optional SASL:
## one of: OAUTHBEARER, PLAIN, SCRAM-SHA-256, SCRAM-SHA-512, GSSAPI
## (defaults to PLAIN)
# sasl_mechanism = ""
## used if sasl_mechanism is GSSAPI (experimental)
# sasl_gssapi_service_name = ""
# ## One of: KRB5_USER_AUTH and KRB5_KEYTAB_AUTH
# sasl_gssapi_auth_type = "KRB5_USER_AUTH"
# sasl_gssapi_kerberos_config_path = "/"
# sasl_gssapi_realm = "realm"
# sasl_gssapi_key_tab_path = ""
# sasl_gssapi_disable_pafxfast = false
## used if sasl_mechanism is OAUTHBEARER (experimental)
# sasl_access_token = ""
## SASL protocol version. When connecting to Azure EventHub set to 0.
# sasl_version = 1
## Name of the consumer group.
# consumer_group = "telegraf_metrics_consumers"
## Compression codec represents the various compression codecs recognized by
## Kafka in messages.
## 0 : None
## 1 : Gzip
## 2 : Snappy
## 3 : LZ4
## 4 : ZSTD
# compression_codec = 0
## Initial offset position; one of "oldest" or "newest".
# offset = "oldest"
## Consumer group partition assignment strategy; one of "range", "roundrobin" or "sticky".
# balance_strategy = "range"
## Maximum length of a message to consume, in bytes (default 0/unlimited);
## larger messages are dropped
max_message_len = 1000000
## Maximum messages to read from the broker that have not been written by an
## output. For best throughput set based on the number of metrics within
## each message and the size of the output's metric_batch_size.
##
## For example, if each message from the queue contains 10 metrics and the
## output metric_batch_size is 1000, setting this to 100 will ensure that a
## full batch is collected and the write is triggered immediately without
## waiting until the next flush_interval.
# max_undelivered_messages = 1000
## Data format to consume.
## Each data format has its own unique set of configuration options, read
## more about them here:
## https://github.com/influxdata/telegraf/blob/master/docs/DATA_FORMATS_INPUT.md
data_format = "json"
请注意,brokers 字段是 localhost:9092,这是您的 Apache Kafka broker 地址。
topics 字段是 garden_sensor_data,这意味着任何生成到此 topic 中的消息都将被 Telegraf 捕获。您还应该注意,由于 InfluxGarden 需要一个处理其 JSON 传感器数据的系统,因此 data_format 设置为 json。有关受支持数据格式的更多信息,您可以阅读 Telegraf GitHub 页面上的“输入数据格式”。
现在您已经配置了 Telegraf,它已准备好运行。在运行 telegraf 命令之前,您必须定义 $INFLUX_TOKEN,它在您的输出配置中。
您可以通过导航回 Load Data 页面并选择 API Tokens 来获取令牌。单击 flux_user’s Token 链接,它应该打开一个弹出窗口,向您显示您创建的 flux_user 用户的令牌
复制令牌并导航回您的终端窗口。出于安全原因,不要直接在 telegraf.conf 文件中定义它,而是将其设置为计算机上的环境变量。然后运行以下命令,将 _YOUR_INFLUXDB_TOKEN_ 替换为您的令牌
export INFLUX_TOKEN=_YOUR_INFLUXDB_TOKEN_在同一终端窗口中,运行以下命令以执行 Telegraf。确保在此命令中正确设置 _YOUR_HOME_DIRECTORY_
telegraf --config _YOUR_HOME_DIRECTORY_/influxgarden_integration/telegraf.conf输出应如下所示
2022-05-21T19:38:37Z I! Starting Telegraf 1.22.4
2022-05-21T19:38:37Z I! Loaded inputs: kafka_consumer
2022-05-21T19:38:37Z I! Loaded aggregators:
2022-05-21T19:38:37Z I! Loaded processors:
2022-05-21T19:38:37Z I! Loaded outputs: influxdb_v2
2022-05-21T19:38:37Z I! Tags enabled: host=_YOUR_HOSTNAME_
2022-05-21T19:38:37Z I! [agent] Config: Interval:10s, Quiet:false, Hostname:"_YOUR_HOSTNAME_", Flush Interval:10s运行 Garden Sensor Gateway 应用程序
InfluxGarden 共享一个 Python 应用程序,该应用程序模拟一个传感器,该传感器向 garden_sensor_data Kafka topic 生成各种传感器数据。此传感器数据包括湿度、温度、土壤和风的信息,这些是 InfluxGarden 需要的传感器数据类型。
要下载生产者应用程序,请从此 GitHub 页面 复制文件内容,并将其保存在 influxgarden_integration 目录中,命名为 garden_sensor_gateway.py。
在运行传感器应用程序之前,请确保 Kafka 集群、InfluxDB 和 Telegraf 实例仍在运行。然后运行以下命令以执行应用程序
python3 garden_sensor_gateway.py当您运行该应用程序时,它会以五秒间隔向 Kafka 发送随机生成的传感器数据。在几个五秒间隔后,输出应如下所示
Sensor data is sent: {"temperature": 33.6, "humidity": 49.1, "wind": 1.1, "soil": 0.6}
Sensor data is sent: {"temperature": 0.9, "humidity": 81.6, "wind": 6.4, "soil": 23.3}
Sensor data is sent: {"temperature": 30.6, "humidity": 10.2, "wind": 4.0, "soil": 80.3}
Sensor data is sent: {"temperature": 8.1, "humidity": 92.9, "wind": 10.0, "soil": 0.9}
Sensor data is sent: {"temperature": 35.1, "humidity": 71.5, "wind": 4.9, "soil": 56.5}
Sensor data is sent: {"temperature": 48.7, "humidity": 22.7, "wind": 1.2, "soil": 38.2}
...output omitted...要查看实际数据,请导航回您的 InfluxDB Web 界面。从左侧菜单中,单击 Explore,这将打开 Data Explorer 页面
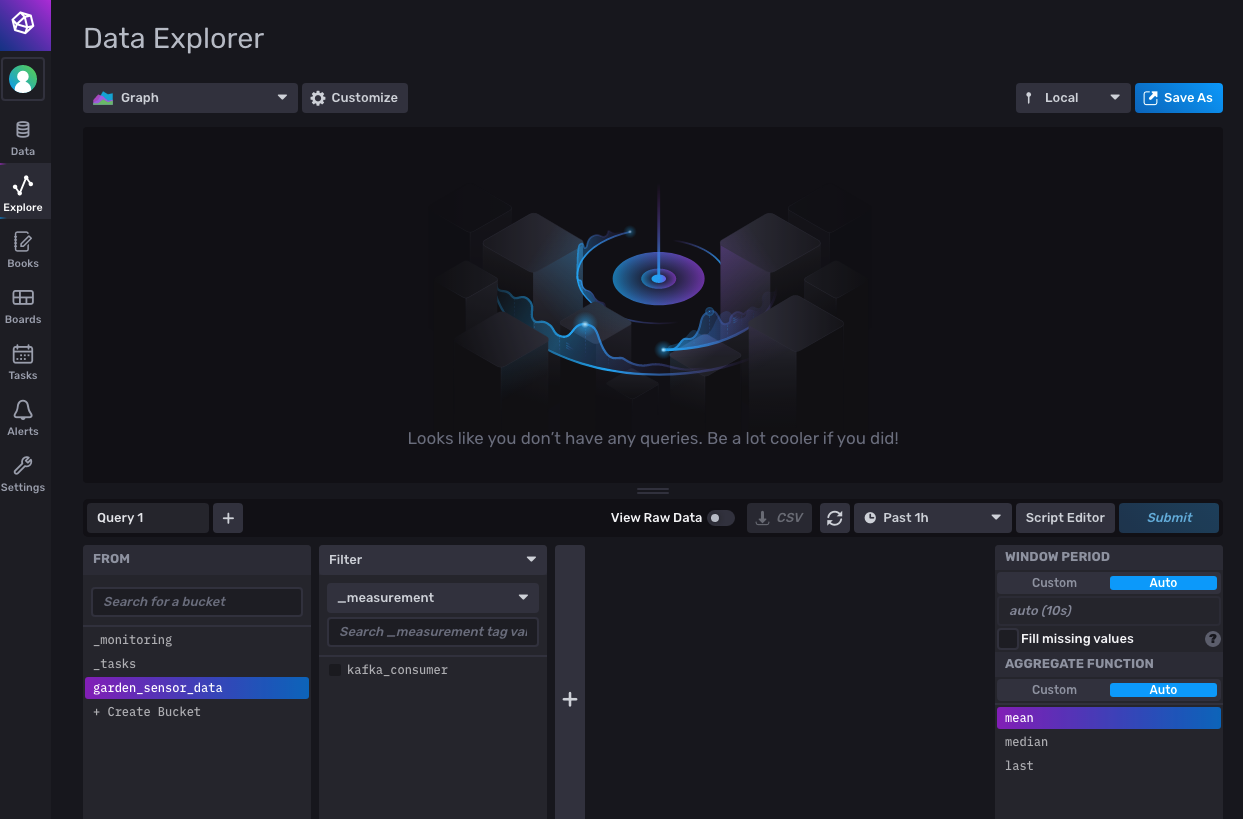
在页面底部,您应该看到 garden_sensor_data bucket 已被选中。单击旁边的 kafka_consumer 过滤器复选框;然后单击右侧的 Submit 按钮以运行所有字段的查询。这应该打开一个图形,显示传感器数据的变化
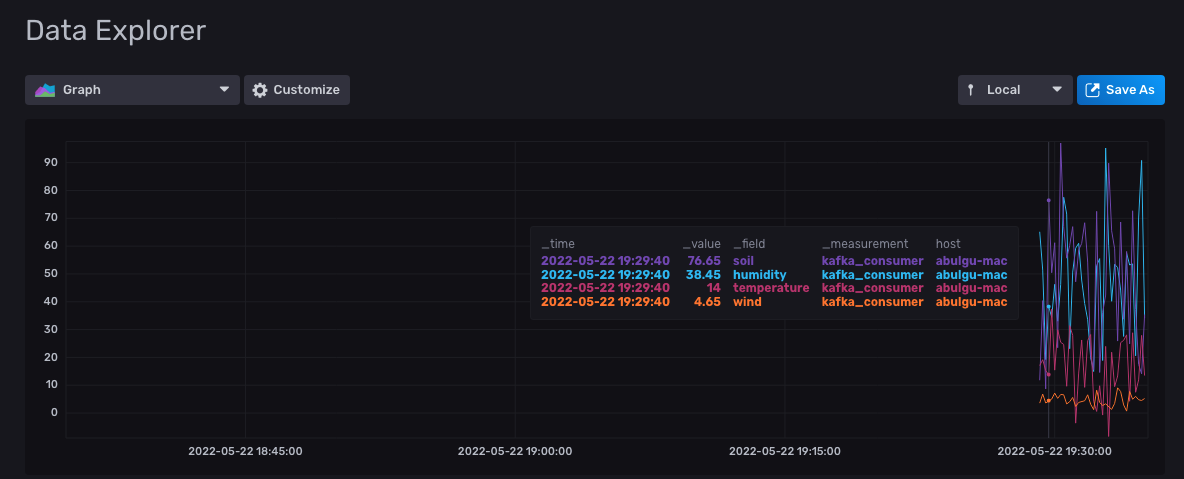
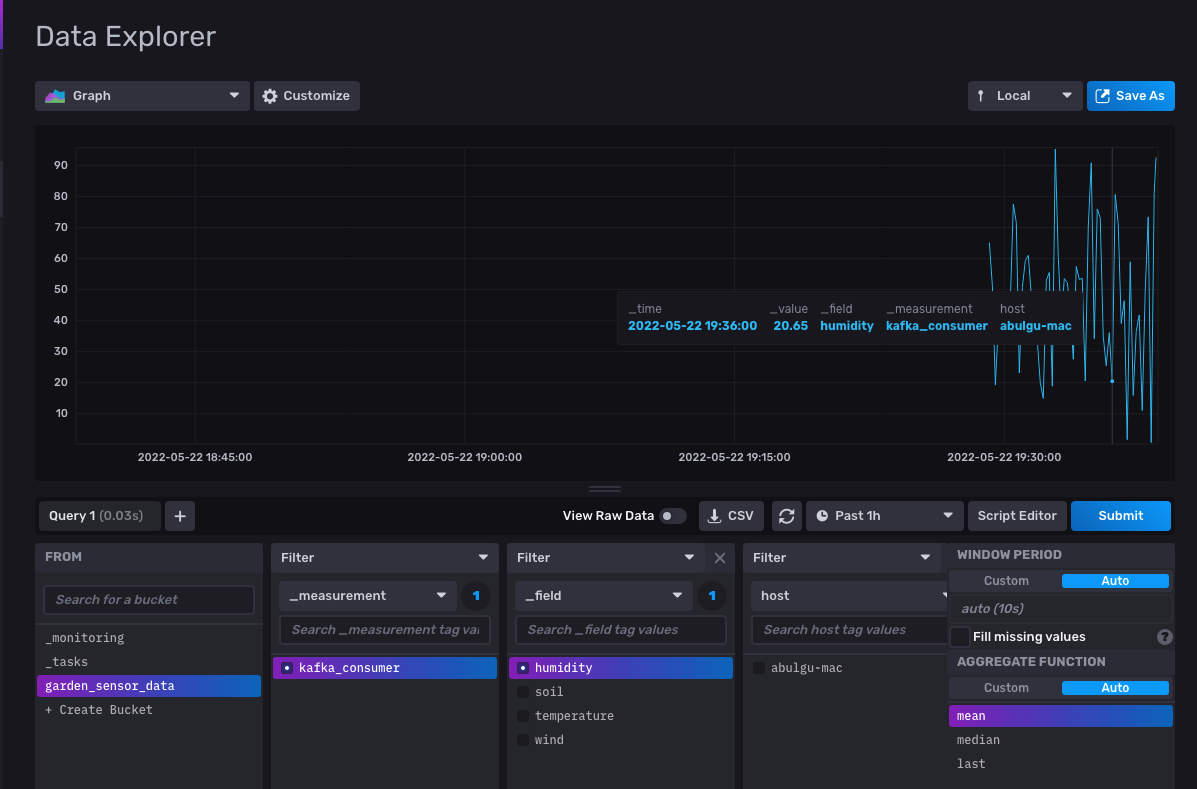
要监控特定的传感器数据变化,您可以单击 _field 过滤器上的一个字段复选框。然后选择一个传感器数据字段(在本例中为 humidity)并单击 Submit 以过滤结果
除了 Graph,您还可以从下拉菜单中选择其他 InfluxDB 数据可视化功能
结论
在本教程中,您已成功使用 Telegraf 将来自 Apache Kafka 的实时传感器数据流式传输到 InfluxDB。
InfluxDB 为监控、应用程序指标、IoT 传感器数据和实时分析提供存储和时间序列数据检索。它可以与 Apache Kafka 轻松集成,使用 Telegraf 发送或接收指标或事件数据,用于处理和监控。
您可以在 此 GitHub 存储库 中找到本教程的资源。
其他资源
既然您正在使用 InfluxDB 存储您的时间序列数据,那么您还可以利用许多其他功能来最大程度地发挥数据的价值。如果您对可以采取的后续步骤感兴趣,请查看以下资源
-
InfluxDB University - 从入门到高级的免费课程,涵盖与 InfluxDB 相关的各种主题
-
时间序列数据分析 - 了解如何分析您的时间序列数据
-
时间序列数据预测 - 了解如何从您的数据中进行预测和推断
-
警报和任务 - 了解如何使用 InfluxDB 创建警报和执行自动化任务
-
Node-RED 教程 - 了解如何将 Node-RED 与 InfluxDB 结合使用,以处理时间序列数据并对其执行自动化操作
关于作者
Aykut Bulgu 是 Red Hat 的服务内容架构师,曾担任软件工程师、顾问和培训师十五年。他参与过许多企业项目(主要是 Java),并使用过许多开源项目,包括 JBoss 中间件。目前,他与 Apache Kafka、Camel 和 Strimzi 等开源项目合作,创建基础扎实的课程。他喜欢传播系统工艺文化,并为 Software Craftsmanship Turkey 社区共同组织活动。
网站:https://www.systemcraftsman.com/
Twitter: https://twitter.com/systemcraftsman
