Flux 窗口化和聚合
作者:Katy Farmer / 用例, 开发者, 产品
2019年1月9日
导航至
今天,我们来谈谈查询。具体来说,我们来谈谈 Flux 查询,这是 InfluxData 正在开发的新语言。您可以阅读我们为什么决定编写 Flux 以及查看 Flux 的技术预览。
如果您是 InfluxDB 用户,您可能正在使用 InfluxQL 编写查询,并且您可以继续编写,只要您愿意。但是,如果您正在寻找替代方案,或者您已经触及 InfluxQL 的某些边界,那么是时候开始学习 Flux 了。

在过去一年里,我一直在学习 InfluxQL,所以我并不一定热衷于给我的脑力负担增加另一种 DSL。毕竟,我们在 Influx 以开发者幸福感为荣,所以我想确保学习 Flux 是 a) 简单的,并且 b) 值得花时间学习的。
我将通过学习如何窗口化和聚合数据来测试这一点,我已经知道如何在 InfluxQL 中做到这一点(我们将在最后回顾完整的 InfluxQL 查询)。
数据
因为我非常时尚和酷炫,我将使用一个脚本将加密货币交易所信息路由到 InfluxDB 中。像大多数人一样,我想跟上加密货币的趋势,这样我就知道我是否应该后悔没有购买任何加密货币。
问题
我们可以获得很多关于加密货币的信息,但我只关心几件事
- 卖家要价是多少?
- 买家想付多少钱?
- 交易以什么价格发生?
本质上,我想知道实际交易价格与预期有多大差异。如果交易价格明显低于卖家支付的价格,那么整个加密货币的闹剧就结束了,我可以继续前进了。如果交易价格明显高于买家想要的价格,那么我当然理解加密货币热潮——我一直说加密货币是未来。
我们需要找出表示我们想要的结果的最佳方法。让我们用 Flux 来塑造数据。
解决方案
这是我在 Chronograf 的“原始数据”视图中收集的数据样本
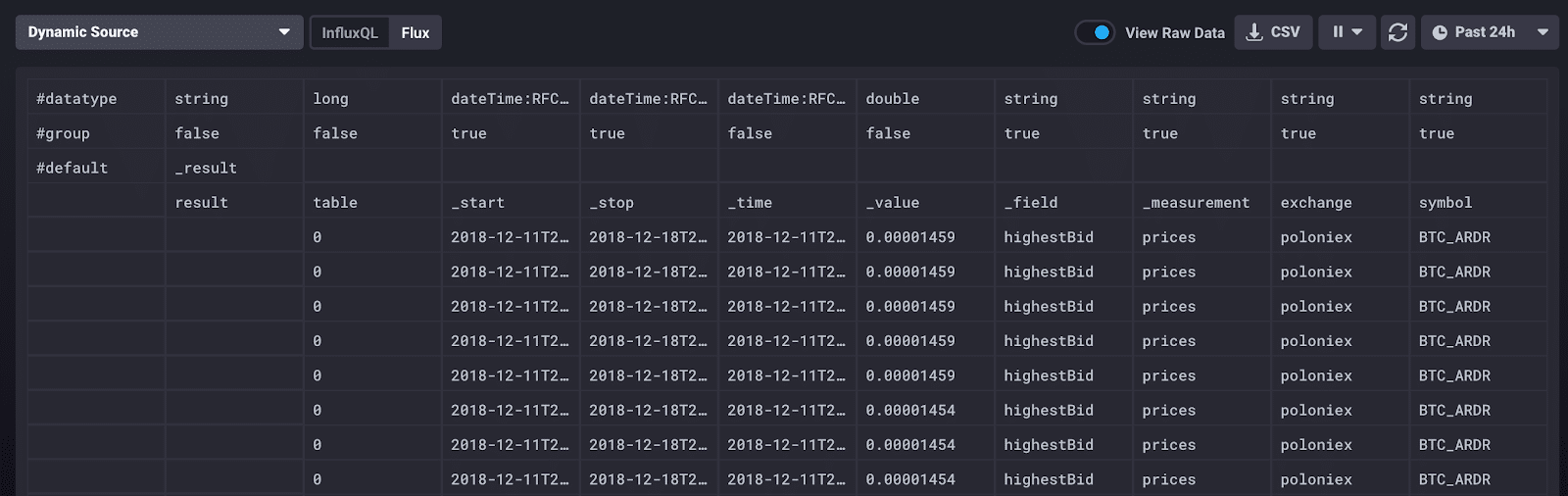
关于这些数据,重要的是要知道什么?顶行显示数据类型,这始终是值得知道的,但在原始数据视图中对于调试尤其有用。第二行“group”表示哪些数据是组键,组键是每行都具有相同值的列列表(稍后会详细介绍)。
还有一些 Flux 特有的列也需要理解。在表模式中,有四个通用列:“_time”(记录的时间戳)、“_start”(所有记录的包含性下限时间)、“_stop”(所有记录的排他性上限时间)和“_value”(记录的值)。在我们的例子中,开始时间是 48 小时前,停止时间是现在 - 48 小时。
其他列表示我为加密货币数据定义的模式:“exchange”和“symbol”是标签,而“_field”和“_measurement”表示该记录的特定字段和测量值。
为了开始编写我的查询,我阅读了这篇 Flux 指南,其中解释了 桶、管道前向运算符 和 表 的概念。本质上,每个 Flux 查询都需要三件事:数据源、时间范围和数据过滤器。
根据指南,我从这个查询开始
from(bucket: "crypto/autogen")
|> range(start: -48h)
|> filter(fn: (r) => r._measurement == "prices" and (r._field == "last" or r._field == "lowestAsk" or r._field == "highestBid"))
第一行是我的数据源,第二行是时间范围,后面的一切都是数据过滤器。
此查询要求我的数据库“crypto”提供与测量值“prices”相关的特定字段:过去 48 小时的最后一次成功交易价格(“last”)、卖家愿意接受的最低价格(“lowestAsk”)和买家愿意支付的最高价格(“highestBid”)。
这是一个好的开始,但结果令人难以承受。结果数据看起来与上面的示例相同——但 Chronograf 显示警告:“大型响应截断为前 103K 行。”

在可视化数据方面,我们不想做不必要的工作。市场上有如此多的加密货币,即使将数据限制在 48 小时内仍然太多,无法解析,当然也太多,无法可视化。说实话,我并不关心所有货币——尽管我喜欢狗狗币的想法,但比特币是潮流引领者。
让我们看看相同的数据,但仅针对比特币。
from(bucket: "crypto/autogen")
|> range(start: -48h)
|> filter(fn: (r) => r._measurement == "prices" and (r._field == "last" or r._field == "lowestAsk" or r._field == "highestBid"))
|> filter(fn: (r) => r.symbol == "USDT_BTC")这些结果更容易管理。现在我们可以更轻松地检查结果。浏览原始数据,我们可以看到此查询返回了三个单独的表(0-2):每个序列一个。
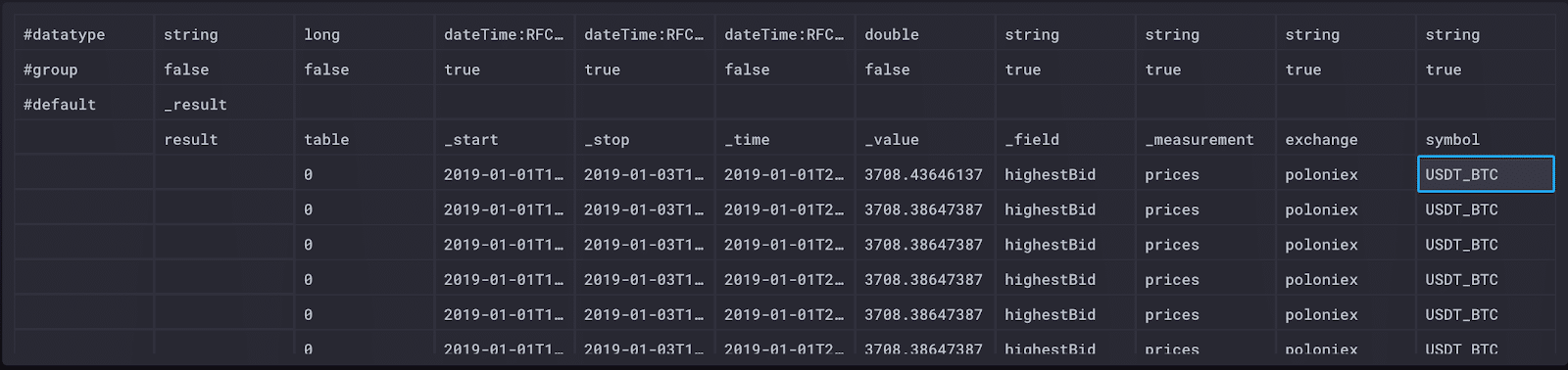
表 0 表示符号(比特币)、交易所(Poloniex)、测量值(价格)和字段(最高买价)的唯一组合。
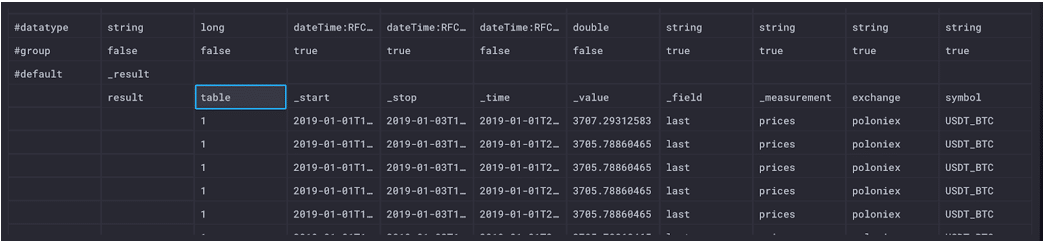
表 1 表示符号(比特币)、交易所(Poloniex)、测量值(价格)和字段(最后一次)的唯一组合。

表 2 表示符号(比特币)、交易所(Poloniex)、测量值(价格)和字段(最低卖价)的唯一组合。
在这种情况下,只有字段在变化,因此限制了序列的数量。以下是在 Chronograf 中折线图中的结果。
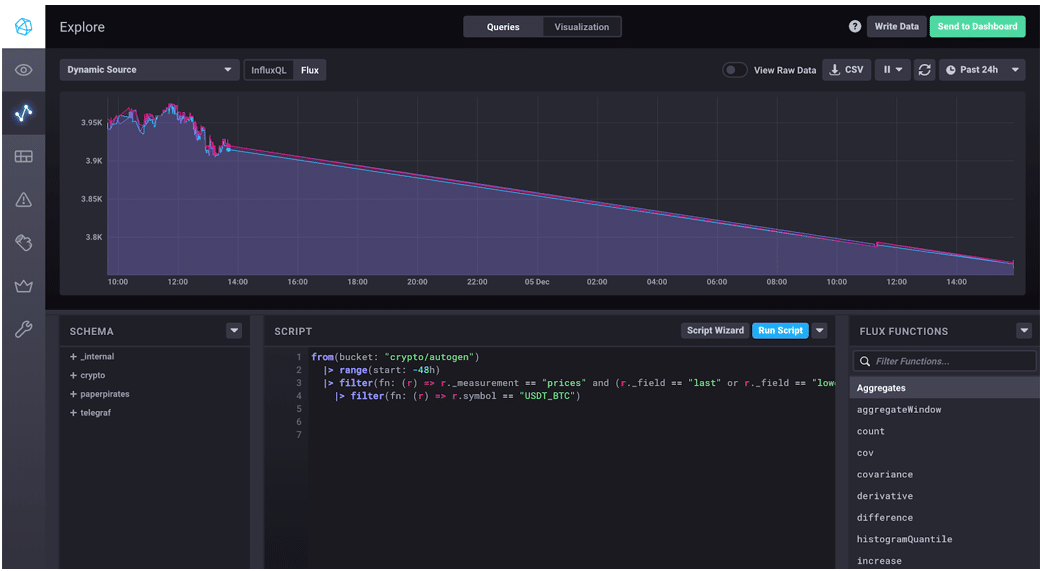
窗口化数据
我们不一定需要在结果中看到每个数据点,特别是当我们对趋势和随时间变化感兴趣时。在这种情况下,我们想要窗口化和聚合我们的数据,这意味着我们想要按时间窗口分割我们的输出,然后找到该窗口的平均值。首先,我跳到官方 Flux 文档的 window() 函数,添加了此 Flux 查询的最后一行。
from(bucket: "crypto/autogen")
|> range(start: -48h)
|> filter(fn: (r) => r._measurement == "prices" and (r._field == "last" or r._field == "lowestAsk" or r._field == "highestBid"))
|> filter(fn: (r) => r.symbol == "USDT_BTC")
|> window(every: 1h)让我们看看这对我们的原始数据有什么改变。
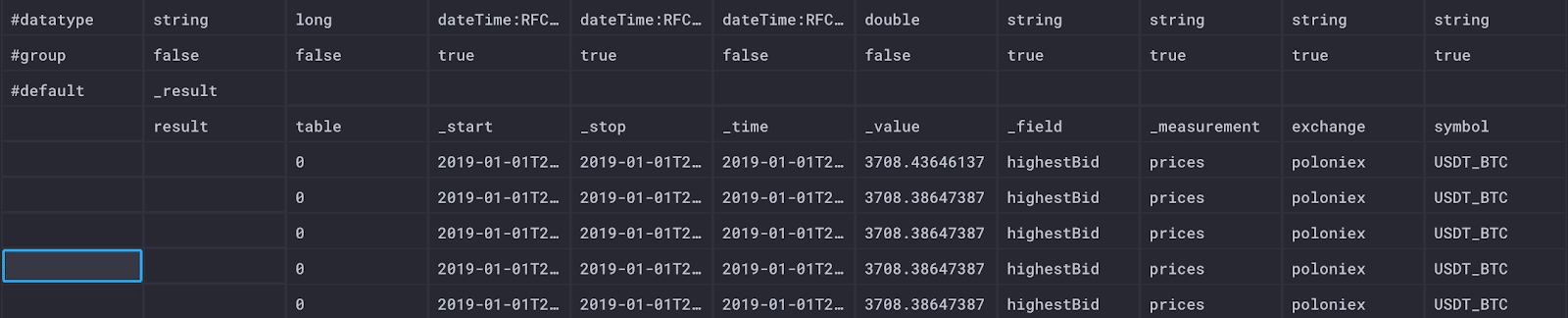

首先,虽然我们在上面的屏幕截图中看不到,但“_start”和“_stop”列已更改以反映时间范围。如果我分别悬停在“_start”和“_stop”上,我会看到以下时间戳。
2019-01-03T18:00:00Z 2019-01-03T19:00:00Z
之前我们的时间从 48 小时前开始,现在停止(不是现在,但你知道,now()),我们的开始和停止时间已更改以反映我们在查询中指定的时间窗口。
按照表列,我们有表 0-23。如果您认为这个数字应该更高,您是对的,但由于中断,我们丢失了一些数据。每个表代表每个唯一序列的每小时窗口(就像上面表下列出的组合一样)。
现在看看 Chronograf 中折线图的差异。
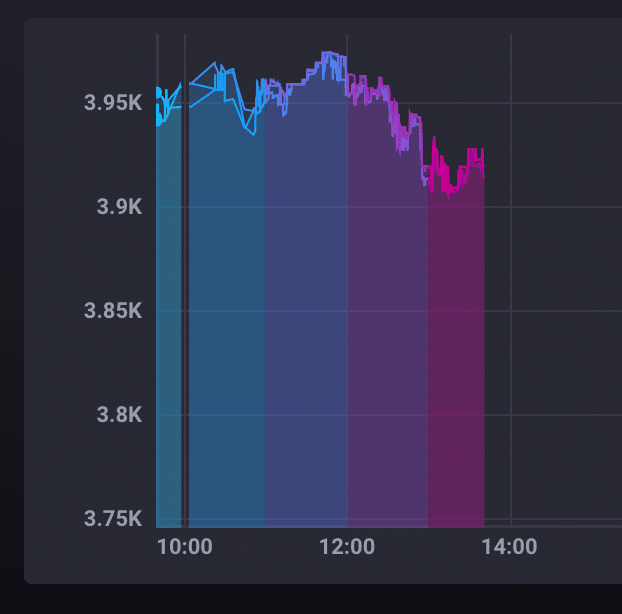
图表中的每种颜色代表不同的时间窗口;在我们的例子中,每种颜色代表一个小时的窗口。这种可视化特别帮助我理解了 Flux 输出。Flux 返回基于时间窗口的数据表——尽管我们看到它们并排可视化,但图中不同颜色部分的数据点完全位于不同的表中,因为它们是单独的时间序列。请记住,图表中的每个时间序列都有其自己独特的颜色,并且颜色突出显示每个序列的开始和停止时间。
聚合数据
聚合函数在 Flux 中与窗口化结合使用时略有不同。当我们将 mean() 之类的函数应用于当前查询时,该函数将应用于每个 1 小时窗口,从而将每个返回的表减少为包含平均值的单行。返回的表数保持不变,但表仅包含一行聚合。
from(bucket: "crypto/autogen")
|> range(start: -48h)
|> filter(fn: (r) => r._measurement == "prices" and (r._field == "last" or r._field == "lowestAsk" or r._field == "highestBid"))
|> filter(fn: (r) => r.symbol == "USDT_BTC")
|> window(every: 1h)
|> mean()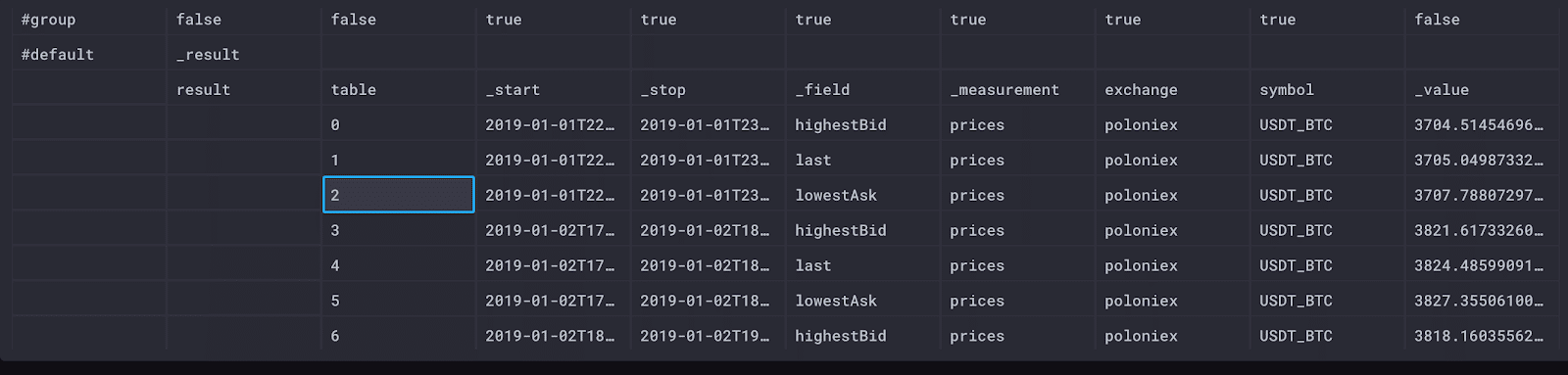
我们的原始数据视图显示,每个表是每小时每个字段的单行数据,这很好,因为这意味着 mean() 确实完成了我们期望的事情。我们表中的列是不同的:我们不再有“_time”列,因为此数据摘要没有单独的时间戳。
我必须研究的一个领域是 mean() 的默认值。当我们没有指定我们要平均什么时,它默认为“_value”。每个 Flux 表都包含一个“_value”列,当我们执行像 mean 这样的聚合时,我们会转换那里列出的值。
现在我们有了我们需要的所有平均值,我们希望我们的数据返回到更少的表中。在 Flux 中,我们可以使用 group() 函数取消窗口化数据以组合相关值。
from(bucket: "crypto/autogen")
|> range(start: -48h)
|> filter(fn: (r) => r._measurement == "prices" and (r._field == "last" or r._field == "lowestAsk" or r._field == "highestBid"))
|> filter(fn: (r) => r.symbol == "USDT_BTC")
|> window(every: 1h)
|> mean()
|> group(columns: ["_time", "_start", "_stop, "_value"], mode: "except")我们又回到了 3 个表(0-2),它们为我们提供了已完成交易价格、卖家的最低卖价和买家的最高买价的每小时平均值。
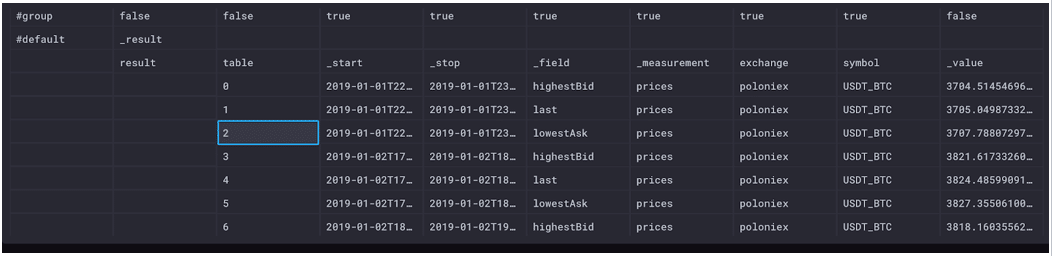
对 group() 的调用以几种重要方式转换了我们的数据。还记得我说过我们会回到组键吗?就是这样!通过分组数据,我们定义了组键。当我们按“_field”和“_measurement”(当我们排除“_time”、“_start”、“_stop”和“_value”时剩下的列)分组时,我们将组键定义为 [_field, _measurement]。在上面的屏幕截图中,“_field”和“_measurement”都在组行中列出 true。在实践中,这意味着我们的查询结果为“_field”和“_measurement”的每个唯一组合输出一个表。
分组数据并定义组键的这个过程表示取消窗口化我们的数据。
关于 group() 的注意事项 自社区开始使用 Flux 以来,group() 函数的语法已更改。group() 的原始语法如下所示
|> group(by: ["_field", "_measurement"])这是重新分组的数据在我们的 Chronograf 可视化中的样子。
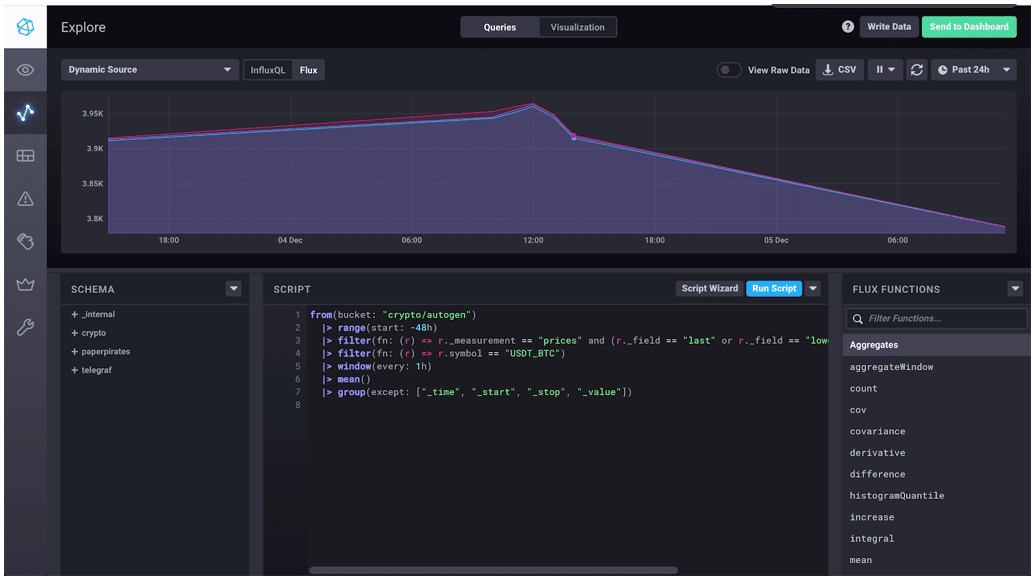
此 Chronograf 可视化为我们提供了一种轻松查看过去两天比特币市场趋势的方法。如果我有更多数据,我可以进行完整的历史分析,以真正了解我是否错失了加密货币机会。
更好的查询
我们编写的 Flux 查询完全符合我的要求,但有点长。当我进一步研究时,我找到了一个辅助函数,它可以隐藏一些更令人困惑的逻辑。
from(bucket: "crypto/autogen")
|> range(start: -48h)
|> filter(fn: (r) => r._measurement == "prices" and (r._field == "last" or r._field == "lowestAsk" or r._field == "highestBid"))
|> filter(fn: (r) => r.symbol == "USDT_BTC")
|> aggregateWindow(every: 1h, fn:mean)aggregateWindow() 函数包括窗口化和取消窗口化数据,这样我们在编写查询时就不必担心数据的格式。我喜欢一个好的辅助函数,特别是当从名称和语法中清楚地知道它在做什么时。返回的数据看起来完全相同,我们节省了几行代码。
总结
我们已经编写了我们想要的 Flux 查询——现在让我们将其与用 InfluxQL 编写的相同查询进行比较。
SELECT
mean("highestBid") AS "mean_highestBid",
mean("last") AS "mean_last",
mean("lowestAsk") AS "mean_lowestAsk"
FROM
"crypto"."autogen"."prices"
WHERE
time > now() - 48h
AND
"symbol"='USDT_BTC'
GROUP BY
time(1h)
FILL(none)这个 InfluxQL 查询仍然是可读的,特别是如果您精通 SQL。鉴于我们的查询不是很复杂,Flux 和 InfluxQL 中的查询最终非常相似。我特别喜欢在 Flux 中使用相对时间范围,因为它更简洁,而不会失去可读性。
Flux - 优点
可读性是我选择的编程语言的重要组成部分,Flux 在这方面获得了 A。我喜欢能够解析查询,即使我不是 Flux 专家。Flux 的函数式特性让我可以根据需要不断转换返回的数据,这在我们处理大型数据集时尤其方便。
此外,由于技术预览已经发布,我可以向其他用户询问他们在 社区站点 上遇到的问题和解决方案。
Flux - 缺点
对我来说,真的只有一个缺点,那就是理解返回的数据的形状。我花了一段时间才理解返回数据中的表是如何形成的,以及为什么它们作为表返回。话虽如此,我不认为这是 Flux 的缺陷,而是我在事先阅读的概念概述中的缺陷。理解表结构对于编写好的 Flux 查询至关重要,因此我们需要确保有更多资源可用于解释这些概念。
结论
我们做到了!我们编写了一个有用的 Flux 查询,使我们能够比较比特币的要价和售价。好消息是,我认为我没有任何加密货币资金也没关系。可能吧。除非价值再次上涨。虽然我们可能没有对加密货币得出任何有意义的结论,但使用 Flux 探索我的数据使我能够轻松地进行有意义的比较。

