Flux 0.7 技术预览
作者:Tim Hall / 用例, 开发者
2018 年 11 月 09 日
导航至
作为 InfluxDB 1.7 发布的一部分,我们提供了对 Flux 技术预览的集成访问。如果您一直没有关注我们的最新动态,Flux 是 InfluxData 新的功能数据脚本语言,旨在查询、分析和与数据交互。
您可能还记得我们最近一些关于构建 Flux 语言的协作努力背后的原因的博客
随着 Chronograf 1.7 的发布,现在可以使用用户界面来构建使用 Flux 的查询。这一切都很棒,但是如果您没有跟上 Flux 开发公告和语法,那么这篇文章将解释关键概念,并引导您开始使用 Flux 以及创建第一个查询所需的步骤。
启用 Flux
Flux 0.7 技术预览包含在 InfluxDB 1.7 中,但默认情况下处于禁用状态。通过将 flux-enabled 设置为 true,在 InfluxDB 配置文件的 [http] 部分下(通常:Linux 上为 /etc/influxdb/influxdb.conf,macOS 用户为 /usr/local/etc/influxdb.conf)启用 Flux。
[http]
flux-enabled = true关键概念
在深入研究语法之前,您应该了解一些新概念。
存储桶
存储桶是一个命名的位置,用于存储具有保留策略的数据。它类似于 InfluxDB v1.x “数据库”,但它是数据库和保留策略的组合。当使用多个保留策略时,每个保留策略都是其自己的存储桶。
Flux 的 from() 函数(定义 InfluxDB 数据源)需要 bucket 参数。对于技术预览,请使用以下存储桶命名约定,该约定将数据库名称和保留策略组合成单个存储桶名称
存储桶命名约定
// Pattern
from(bucket:"<database>/<retention-policy>")
// Example
from(bucket:"telegraf/autogen")数据表
Flux 以表格格式返回数据。这意味着在评估每个函数或操作后,都会返回包含数据的表或表集合。Flux 广泛使用管道转发运算符 (|>) 将操作链接在一起。管道转发运算符将这些表管道传输到下一个函数或操作,在其中对它们进行进一步处理或操作。
从 InfluxDB 查询数据
编写您的第一个 Flux 脚本并查看实际结果的最简单方法是使用 Chronograf 的数据浏览器。打开数据浏览器,然后在图形占位符上方的源下拉列表的右侧,选择 Flux 作为源类型。
这将修改用户界面以提供对 Schema、Script 和 Flux Functions 窗格的访问。Schema 窗格允许您通过测量、字段和标签来浏览您的数据模式。Script 窗格是您编写 Flux 脚本的地方,Flux Functions 窗格提供可用于 Flux 脚本的 Flux 函数列表。将鼠标悬停在函数上将显示有关使用该函数的有用信息。
要构建您的 Flux 脚本,请使用脚本向导,该向导允许您快速选择存储桶、测量、一个或多个字段以及一个函数来帮助您入门,或者只需单击脚本窗格即可。类型提前辅助功能在您构建查询时提供语法建议。
使用脚本向导可以减少创建新查询时的大量初始输入。
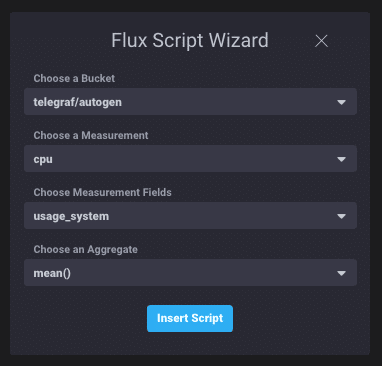
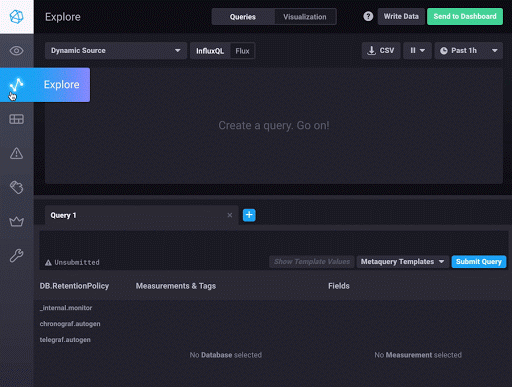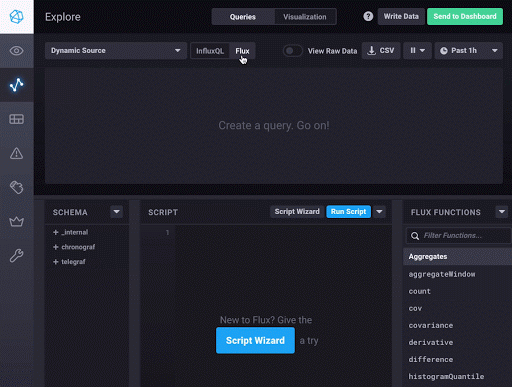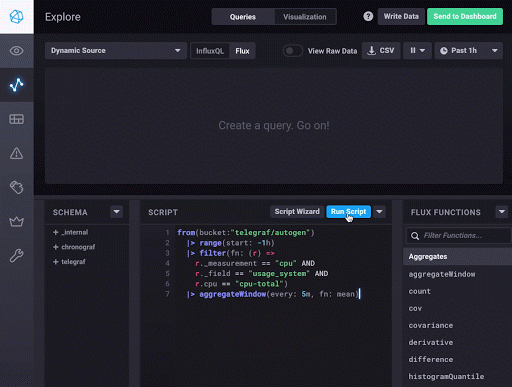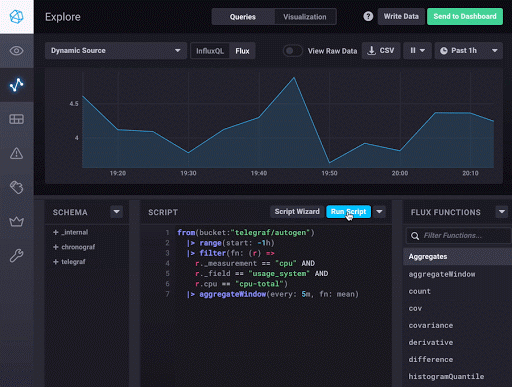
上面的选择将以下 Flux 查询传递到脚本编辑器中
from(bucket: "telegraf/autogen")
|> range(start: dashboardTime)
|> filter(fn: (r) => r._measurement == "cpu" and (r._field == "usage_system"))
|> window(every: autoInterval)
|> mean()
|> group(except: ["_time", "_start", "_stop", "_value"])完成!这仅仅是开始,应该让您体验 Flux 语言和基本概念。您可以在 Chronograf 中执行的酷炫操作之一是在可视化和 Flux 返回的原始数据表之间切换。这非常有用,可以让您了解 Flux 如何评估您用于构建查询的不同函数。
您可以继续使用 Flux Builder 中的各种面板探索 Flux。官方文档将为您提供当前可用函数的更完整列表以及其他示例。我们将在以后的博客文章中分解查询部分、以表格格式返回的结果以及如何利用 window() 和 group()。
但首先:通过下载 InfluxDB 1.7 和 Chronograf 1.7 的开源版本来亲身体验 Flux。
与往常一样,我们对社区反馈感兴趣。请访问 InfluxData 社区站点,提供有关 Flux 语言的反馈,以帮助我们改进。
