使用 Serverless 函数扩展 InfluxDB
作者:Nate Isley / 产品, 用例, 开发者, 公司
2020 年 6 月 4 日
导航至
数据摄取和数据分析是时间序列平台的阴阳两面。 有许多资源可以帮助您摄取数据。 典型的摄取方式包括基于代理、通过 CSV 导入、使用客户端库或通过第三方技术。 一旦您的时间序列数据到达,分析就完成了循环,并且通常会引导到额外的数据收集,依此类推。
InfluxDB 原生工具(如 Tasks、Dashboards 和 Flux)通常在平台内提供所需的洞察力,但某些用例需要扩展平台。 对于这些用例,InfluxDB 的统一 API 提供了一整套集成端点。 这种可扩展性是开发者喜爱 InfluxDB 的原因之一。
为了说明这一点,我提供了两个简单的示例,它们在 Amazon Web Services (AWS) 的函数即服务产品 - Lambda 上实现。 Serverless 函数(如 Lambda)几乎适用于任何架构,因为它们是解耦的工作单元,相对容易连接。
设置
我的示例包含一个 Flux Task,它综合监控 Web 应用程序的响应时间。 InfluxDB 收集数据并充当后端分析引擎,服务处理器使用该引擎来支持其业务流程。
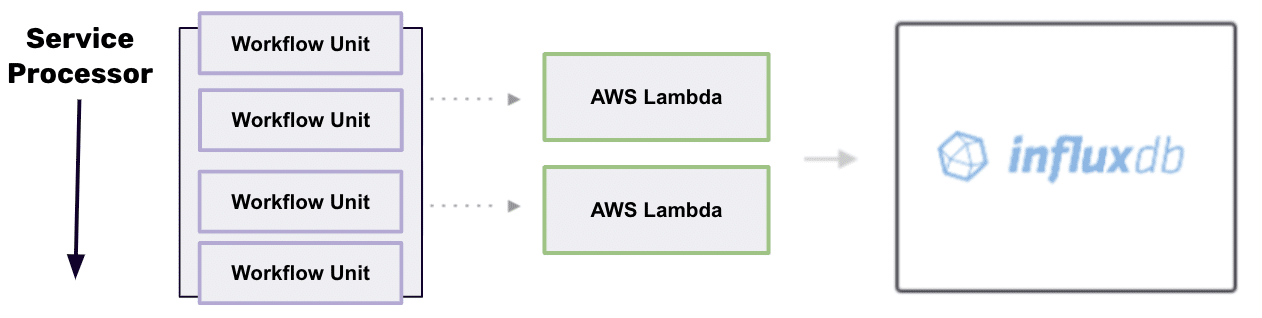
我复制了合成监控 Task 三次,使用了不同的 URL,并将结果存储在以被监控公司名称命名的存储桶中。 例如,我的一个任务监控 Uber 的响应时间,响应时间存储在名为“Uber”的存储桶中。 最终结果? 三个 InfluxDB 任务捕获网站性能,数据格式统一,仅通过存储桶名称区分。
使用 AWS Lambda 查询 InfluxDB
创建 Lambda 时的第一个决定是选择使用哪种语言。 为了更容易地完成开发,我使用了 NodeJS。 AWS 的 NodeJS 集成开发环境支持意味着第一个示例可以完全在浏览器中创建。
要继续操作,请注册一个免费的 AWS 账户并完成 Lambda 的入门步骤。 创建一个 hello world NodeJS Lambda,并将示例 1 复制/粘贴到控制台。 在 InfluxDB 方面,注册一个免费的 InfluxDB Cloud 账户,创建 Flux 任务,并获取您的 org-id 和令牌以插入到示例 1 的代码中
var https = require('https');
exports.handler = function(event, context) {
var queryForCount = "from(bucket: \"Pingpire\") |> range(start: -1h) |> filter(fn: (r) => r[\"_measurement\"] == \"PingService\") |> filter(fn: (r) => r[\"_field\"] == \"response_time_ms\") |> filter(fn: (r) => r[\"method\"] == \"GET\") |> count()"
// An object of options to indicate where to post
var post_options = {
host: 'us-west-2-1.aws.cloud2.influxdata.com',
path: '/api/v2/query?orgID=<your-ord-id>',
method: 'POST',
headers: {
'Content-Type': 'application/vnd.flux',
'Authorization': 'Token <your-user-token>'
}
};
// Set up the request
var post_req_uber = https.request(post_options, function(res) {
res.on('data', function(chunk) {
console.log('Response: ' + chunk);
context.succeed();
});
res.on('error', function(e) {
console.log("Got error: " + e.message);
context.done(null, 'FAILURE');
});
});
// post the data
post_req_uber.write(queryForCount);
post_req_uber.end();
}这是我在浏览器中测试 Lambda 时 AWS IDE 输出的屏幕截图
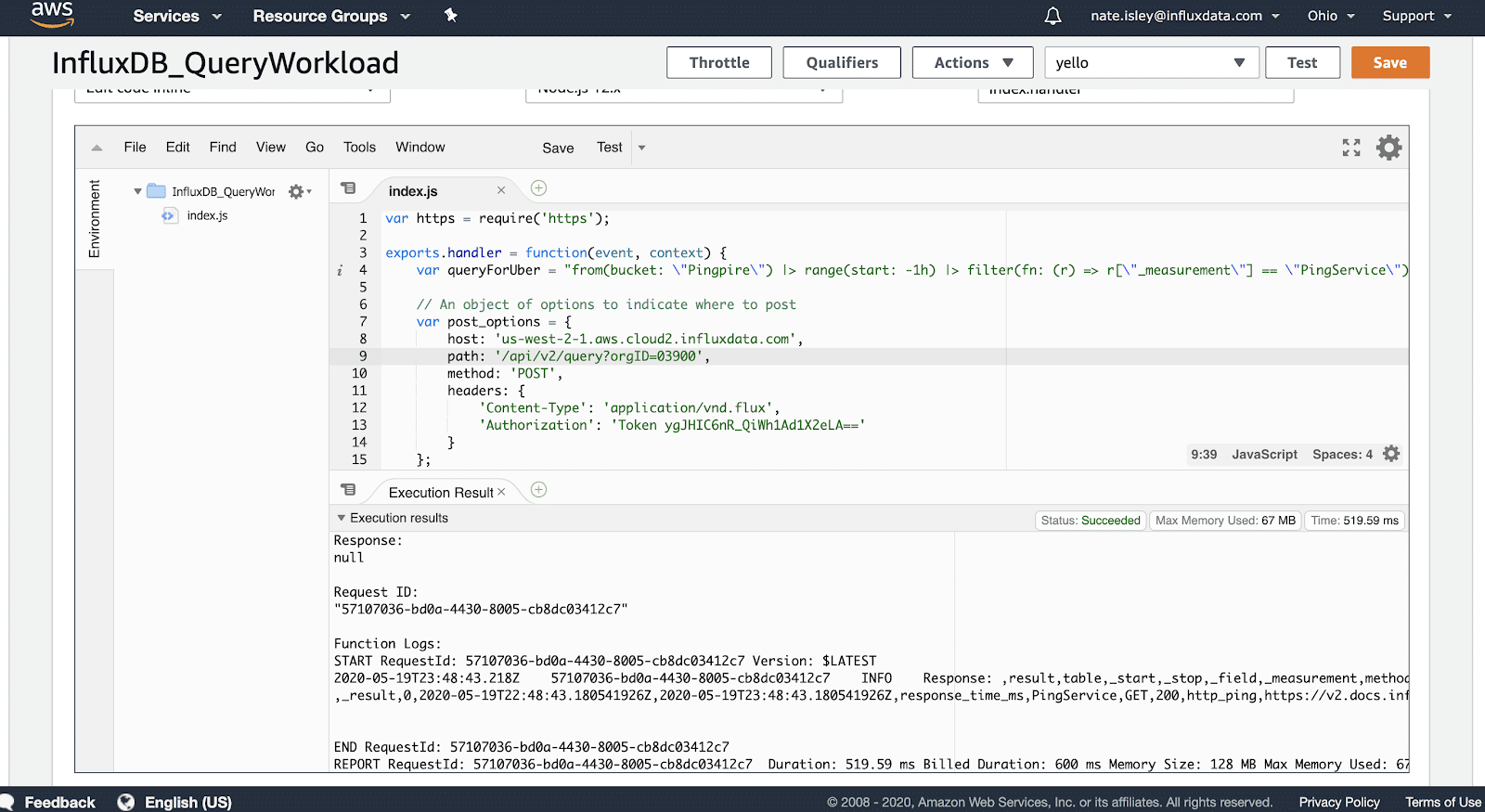
第一个示例是直接使用 NodeJS HTTPS POST 请求来演示直接使用 InfluxDB 的 API。 使用 API 功能强大且简单,但许多开发人员宁愿使用库而不是进行 HTTP 调用。 我的第二个示例通过 InfluxDB 客户端库调用 InfluxDB 以说明这种方法。
设置第二个示例需要更多的工作,因为基本的 AWS NodeJS 库是有限的。 要继续,您将需要 AWS 命令行界面 (CLI) 来添加节点包 - 按照 安装/使用 AWS CLI 的说明进行操作。
拥有 CLI 后,更新 lambda 函数的可用库/包,使用
>npm install @influxdata/influxdb-client在本地目录中。 您可以压缩该目录并使用 CLI 将其直接导入到 AWS Lambda,或者像我一样,使用 NodeJS IDE 的“上传 zip 文件”选项,在代码条目类型下。
一旦 Lambda 集成了 InfluxDB 客户端库,复制/粘贴示例 2 的代码
const { InfluxDB } = require('@influxdata/influxdb-client')
const token = '<your-user-token>'
const org = '<your-org-id'
const client = new InfluxDB({ url: 'https://us-west-2-1.aws.cloud2.influxdata.com', token: token })
const queryApi = client.getQueryApi(org)
exports.handler = function(event, context, callback) {
var customerJSON = JSON.parse(JSON.stringify(event));
var customers = [];
var x;
for (x in customerJSON) {
customers.push(customerJSON[x]);
}
var y = 0;
for (var i = 0; i < customers.length; i++) {
var query = `from(bucket: "${customers[i]}" ) |> range(start: -10m) |> filter(fn: (r) => r.method == "GET" ) |> count(column: "_value")`;
console.log(query)
queryApi.queryRows(query, {
next(row, tableMeta) {
const o = tableMeta.toObject(row);
console.log(`Customer "${customers[y++]}" consumed ` + o._value + ` pings.`);
},
error(error) {
console.error(error)
console.log('\nFinished ERROR')
},
complete() {
console.log('\nFinished SUCCESS')
},
})
}
}正如您所见,使用客户端库与 API 访问没有太大的不同。 您仍然需要令牌、org-id 和查询,但原生库几乎总是使开发人员更有效率。
为了执行和测试此示例,回想一下我的 InfluxDB 有多个用于监控公司网站的任务,结果通过存储桶名称区分。 我的 Lambda 接收公司 JSON 列表,并循环遍历该列表以查询 InfluxDB 获取结果。 这是我的测试 JSON
{
"Company1": "Microsoft",
"Company2": "Uber",
"Company3": "Pingpire"
}这是第二个 Lambda 的 AWS IDE 输出的屏幕截图
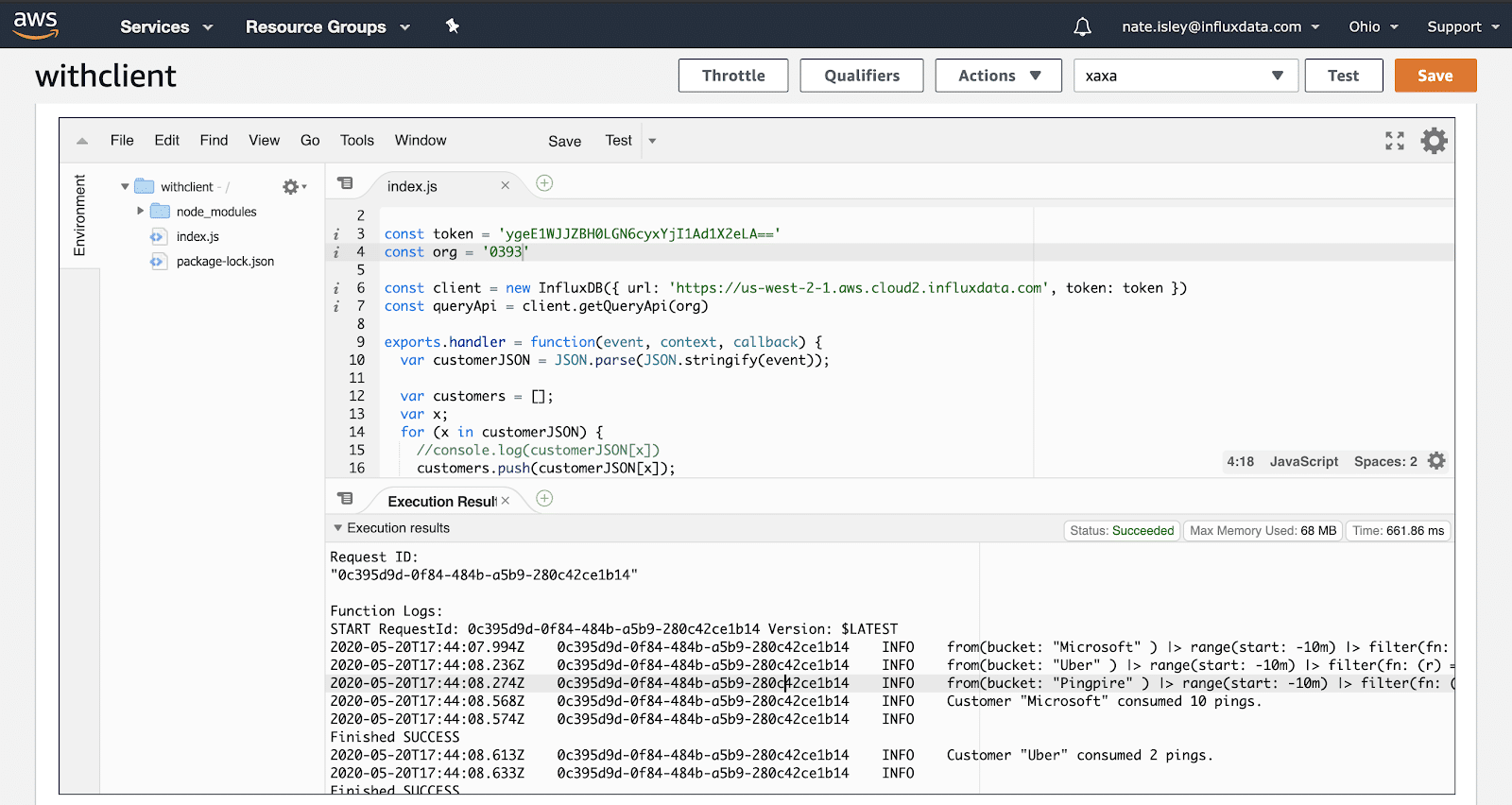
探索 serverless 集成仍在继续...
这些初始示例演示了使用 Lambda 扩展 InfluxDB 的便捷性。 在接下来的几周内,我将在此基础上进一步扩展,以探索 Serverless 与 InfluxDB 的结合使用。
正如我所提到的,请立即试用上述示例,方法是注册免费的 InfluxDB Cloud 和 AWS 账户。 与往常一样,如果您有疑问、反馈或想探索这些特定示例,请在我们的社区论坛或通过 Slack 联系我们!
