使用 Telegraf Operator 扩展 Kubernetes 监控
作者:Wojciech Kocjan / 使用案例, 产品, 开发者
2021年12月03日
导航至
本文最初发布于 The New Stack。
监控是云计算的关键方面。在任何时候,您都需要知道什么是有效的,什么是无效的,并有能力对给定环境中发生的变化做出响应。有效的监控始于从整个生态系统收集性能数据并以有用的方式呈现它的能力。因此,跨生态系统管理监控数据越容易,这些监控解决方案就越有效,生态系统效率也就越高。
Kubernetes 是云计算的主力,它提供的自动化功能是一项变革。然而,不受控制的自动化有可能产生问题,因此有必要监控这些自动化过程。Prometheus 是一种流行的 Kubernetes 环境监控解决方案。
然而,并非所有应用程序都完全在 Kubernetes 中运行。如果您想使用 Prometheus 从包括自定义应用程序服务器、遗留系统和技术在内的多个环境汇总指标数据,您最终将编写大量自定义代码才能访问和摄取这些指标。
Telegraf Operator,一种环境不可知的 Prometheus 替代方案,应运而生。
什么是 Telegraf Operator?
首先,我们应该区分 Telegraf 和 Telegraf Operator。
Telegraf 是一款开源服务器代理,旨在从堆栈、传感器和系统收集指标。
另一方面,Telegraf Operator 是一款旨在在 Kubernetes 集群中创建和管理单个 Telegraf 实例的应用程序。本质上,它充当控制平面,用于管理部署在整个 Kubernetes 集群中的各个 Telegraf 实例。Telegraf Operator 是一个独立的应用程序,它与 Telegraf 分开部署。
Telegraf Operator 的注意事项
在基本层面上,Telegraf Operator 从 Kubernetes 集群中具有公开端点的应用程序抓取指标。
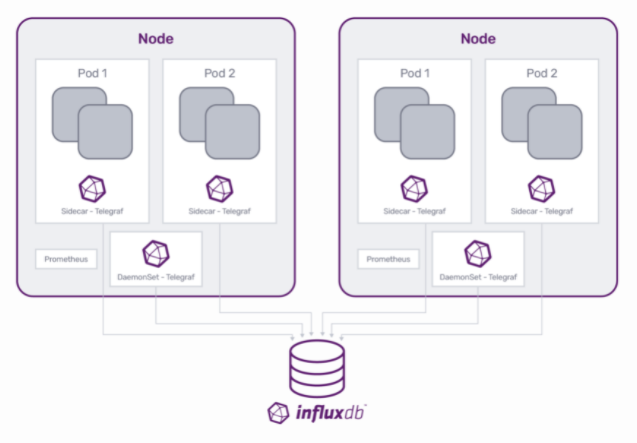
部署监控代理主要有两种机制,DaemonSet 和 sidecar。根据您想要监控的具体内容,您应该使用的机制有所不同。对于 InfluxDB,我们建议
- DaemonSet 用于节点、Pod 和容器指标。
- Sidecar 监控用于暴露大量指标的微服务。
在 DaemonSet 场景中,Telegraf 在每个单独的节点上运行,并收集节点自身的基础设施指标。
相比之下,在 sidecar 部署中,容器化的 Telegraf 实例与应用程序容器共享 Pod,并从该应用程序的公开端点抓取数据。
Sidecar 部署
但是 sidecar Telegraf 容器从哪里来呢?这就是 Telegraf Operator 发挥作用的地方。
Telegraf Operator 在 Pod 级别工作,因此您可以将其与 Kubernetes 环境中创建 Pod 对象的任何事物一起使用。当某些东西(部署、StatefulSet、DaemonSet、Job 或 CronJob)发出创建新 Pod 的请求时,Telegraf Operator 会拦截该请求,使用 Kubernetes 中的 mutating webhooks 功能,并有机会对其应用更改。
Telegraf Operator 读取请求中的 Pod 注释,如果注释指示添加 Telegraf sidecar,则 Telegraf Operator 会将该实例作为 Pod 中的附加容器添加。换句话说,Telegraf Operator 查看新 Pod 的容器列表,如果注释指示这样做,则向列表添加另一个容器。
一旦 Telegraf sidecar 容器到位,它就可以开始抓取数据并将指标推送到数据库,例如 InfluxDB。
使用 sidecar 部署进行 Kubernetes 监控有几个优点。Sidecar 监控代理允许您定义自定义指标和特定应用程序的监控,而不会影响其他工作负载共享的整体监控框架。这种方法使端点暴露保持可管理。随着应用程序暴露更多端点,sidecar 方法有助于更好的可扩展性,因为该 Telegraf 实例仅抓取其 Pod 中应用程序的数据。
Telegraf Operator 适合您吗?
这个问题的答案实际上取决于您的生态系统以及您想要监控的内容。有很多不同的选项和可能性。我们在这里概述了一些。
替换 Prometheus
Telegraf 可以充当 Prometheus 服务器,因此您想要使用 Prometheus 收集的任何指标也可以使用 Telegraf Operator 收集。因此,可以简单地用 Telegraf Operator 替换 Prometheus。在这种情况下,您需要用 Telegraf sidecar 容器替换 Prometheus exporters,将 Telegraf Operator 期望的注释添加到您的 Pod 规范中,并将您的数据存储从 Prometheus 服务器切换到 InfluxDB。
然而,如果完全移除 Prometheus 监控的想法似乎太具破坏性,那么有很多方法可以使用 Telegraf 和 Telegraf Operator 来增强或补充您当前的 Prometheus 监控,以获取遗留和自定义应用程序指标。
替换 Prometheus 的一部分
如果您想要更大的灵活性和可访问性来处理各种指标,一种选择是将 Prometheus 服务器配置为直接写入 Telegraf。您可以通过 Prometheus Remote Write Telegraf 插件 来做到这一点。您可以配置插件将收集的指标发送到您想要的任何数据库,例如 InfluxDB。此设置允许您将指标从 Prometheus 服务器直接发送到 InfluxDB,或者,根据您的配置,您甚至可以将指标发送到多个位置。如果您想进行双写或为您的指标数据创建备份系统方案,这将很有帮助。
Telegraf 也可以充当 Prometheus 服务器,因此另一种选择是用 Telegraf 替换您的 Prometheus 服务器。您可以保留 Prometheus exporters,因为 Telegraf 能够摄取这些数据。一旦 Telegraf 收集到这些数据,您就可以灵活地将其发送到任何您想要的地方。
并行运行 Telegraf 和 Prometheus
另一种选择是并行运行 Prometheus 和 Telegraf。这两个应用程序的功能相同,都是抓取 Prometheus exporters 呈现的数据。您可以配置这两个服务来抓取数据,然后在必要时对这些数据进行并排比较。
这种设置的另一种可能性是使用 Telegraf 实例将数据写入 Kubernetes 环境外部的某个位置,并将 Prometheus 服务器用于 Kubernetes 环境内的任何需求。
全局数据收集
除了这些 sidecar 使用案例之外,您还可以同时使用 Telegraf Operator 运行 DaemonSet 监控,这样您就可以获得关于实际 Pod 和节点的指标。这样做可以将整个生态系统的指标数据保存在一个地方,为生态系统的每个方面提供集中监控。
如果 Kubernetes 只是您的系统运行的几个环境之一,那么 Telegraf Operator 可能是更合适的选择。如上所述,如果您正在使用 Kubernetes 并且想要从非 Kubernetes 环境收集指标,事情会变得更加复杂。您必须为您想要从中获取指标的每种类型的技术编写自定义 exporter,然后配置它,以便 Prometheus 服务器可以抓取这些指标。
相比之下,Telegraf 有数百个可用的插件,不仅可以从 Kubernetes 收集指标,还可以从外部环境收集指标。
在 Kubernetes 中安装 Telegraf Operator
telegraf-operator 在集群中自己的命名空间中启动一个 Pod。安装 telegraf-operator 非常简单,您可以通过 kubectl 完成,如下所示
kubectl apply -f telegraf-operator.yml
(您可以在 deploy 目录 中找到 yml 文件的示例。)
您还可以使用其他工具(例如 Helm 或 Jsonnet)来安装 telegraf-operator。
helm upgrade --install my-release influxdata/telegraf-operator
安装完成后,Telegraf Operator 会监视使用一组特定的 Pod 注释 部署的 Pod,如上所述。使用 Telegraf Operator 的优势在于,您只需在创建 Pod 注释时定义 Telegraf 的输入插件配置。然后,Telegraf Operator 会为整个集群设置配置,因此您的用户在部署应用程序时无需担心配置指标目标。
开始抓取指标
安装 Telegraf Operator 后,您只需注释应用程序容器的 Pod 即可开始抓取您的应用程序或指标端点。
这是带有 Telegraf 配置数据的 DaemonSet 部署 YAML 文件的示例
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: my-application
namespace: default
spec:
selector:
matchLabels:
app: my-application
template:
metadata:
labels:
app: my-application
annotations:
telegraf.influxdata.com/class: app
telegraf.influxdata.com/port: "8080"
telegraf.influxdata.com/path: /v1/metrics
telegraf.influxdata.com/interval: 5s
telegraf.influxdata.com/scheme: http
telegraf.influxdata.com/internal: "true"
spec:
containers:
- name: my-application
image: my-application:latest这是带有 Telegraf 配置数据的 Redis 的 StatefulSet 部署 YAML 文件的示例
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: redis
namespace: test
spec:
selector:
matchLabels:
app: redis
serviceName: redis
template:
metadata:
labels:
app: redis
annotations:
telegraf.influxdata.com/inputs: |+
[[inputs.redis]]
servers = ["tcp://:6379"]
telegraf.influxdata.com/class: app
spec:
containers:
- name: redis
image: redis:alpine配置 Telegraf Operator
如上所述,telegraf-operator 读取 Pod 注释以确定是否注入 Telegraf sidecar 以及应用什么配置。
使用 telegraf.influxdata.com/inputs 注释来传递 Telegraf 配置语句。您可以通过这种方式传递 200 多个 Telegraf 插件中任何一个的配置。对于基于 Prometheus 的指标,添加 telegraf.influxdata.com/port 以及任何其他注释,例如 telegraf.influxdata.com/path 或 telegraf.influxdata.com/interval,并且 telegraf-operator 会为 inputs.prometheus 生成部分配置。
telegraf.influxdata.com/class 注释指定 Pod 的监控类别。Kubernetes secret 定义了类别,telegraf-operator 读取这些类别,然后将其合并到 Telegraf 的最终配置中。
类别通常指定数据应发送到的输出,例如
apiVersion: v1
kind: Secret
...
spec:
stringData:
app: |+
[[outputs.influxdb]]
urls = ["http://influxdb.influxdb:8086"]
[[outputs.file]]
files = ["stdout"]
[global_tags]
hostname = "$HOSTNAME"
nodename = "$NODENAME"
type = "app"Pod 级别注释文档 描述了所有支持的注释。全局配置 – 类别文档 定义了类别。
从 1.3.0 版本开始,telegraf-operator 支持热重载配置。这也需要 Telegraf 1.19 版本。借助新功能,更改全局配置会触发所有 Telegraf sidecar 的配置更新,并由 telegraf 进程重新加载,而无需手动重启任何 Pod。热重载文档 中提供了更多详细信息。
贡献 Telegraf Operator
在 InfluxData,我们热爱开源,因此如果您有兴趣为 Telegraf Operator 插件做出贡献,我们很乐意收到您的来信。您可以在 Slack 上联系我们,或查看我们的 GitHub 仓库 以获取更多信息。
