深入 Flux 中的机器学习:朴素贝叶斯分类
作者: Rohan Sreerama / 产品, 用例, 开发者
2020年9月9日
导航至
机器学习 – 编写通过经验自动改进的算法的实践 – 如今已成为一个流行语,它暗示着某些超凡脱俗且处于技术前沿的事物。我在这里告诉你,虽然这可能是真的,但开始使用机器学习不必很难!
InfluxData 每年为实习生举办黑客马拉松。作为一名实习生,我的 3 人团队决定尝试实施一个 Slack 事件分类器,以改进计算团队的日常工作流程。虽然 Scikit(一个用于 Python 的机器学习库)可以轻松用于对 Slack 事件进行分类,但我们决定使用 Flux(InfluxData 的数据脚本和查询语言)从头开始编写一个分类器。有时它既有趣又令人沮丧,但总的来说,它令人振奋。我们选择 Flux 是因为它独特的数据密集型功能,使我们能够简洁地操作时间序列数据。
我们的目标:使用 Flux 编写的朴素贝叶斯分类器对数据进行分类。
什么是朴素贝叶斯分类器?
朴素贝叶斯分类器是一系列简单的概率分类器,它们基于应用 贝叶斯定理,并在特征之间具有强(朴素)独立性假设。概率分类器是一种分类器,它能够预测给定输入的观察结果,预测一组类别的概率分布,而不仅仅是输出观察结果应属于的最有可能的类别。在像朴素贝叶斯这样的概率分类器经过训练后,通过确定具有最高概率的类别来进行预测。

我们开始了学习和使用函数式编程语言 Flux 编写代码的艰巨任务,这在 2 天内完成。
关于 Flux 的几件事
- 函数式编程是不同的!Flux 利用了这一点,消除了典型的代码结构,并使用其自己的特殊函数,这些函数可以有效地执行数据密集型任务。
map(fn: (r) => ({ _value: r._value * r._value}))
Flux map 函数 遍历每个记录,应用指定的操作。
- 数据处理主要以表格形式完成。换句话说,您在函数中传入和返回大量数据表,这使得执行复杂的计算非常直观和友好。以 Flux reduce 函数 为例 - 它使用 reducer 函数计算整个列的聚合数据
reduce(
fn: (r, accumulator) => ({ sum: r._value + accumulator.sum }),
identity: {sum: 0.0}
)考虑到这一点,让我们进入正题!
我们的演示做什么
我们在 GitHub 上为您提供的朴素贝叶斯分类器实现目前预测以下内容
P(Class | Field) (给定字段的类别的概率)
我们的数据集利用了关于动物园动物的二进制信息。例如,我们有一头水牛,它有许多字段,如脊椎骨、羽毛、蛋等。这些字段中的每一个都根据它们在动物中的存在(0 或 1)被分配一个二进制真或假。
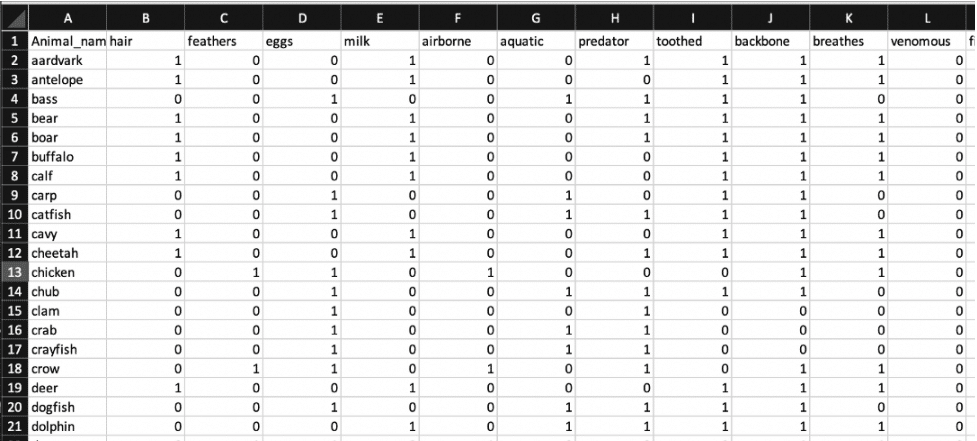
我们目前的实现基于单个输入字段 aquatic 进行预测。我们的分类器预测动物是否是 airborne。我们使用 Python 脚本将数据写入 InfluxDB bucket。这样做时,'airborne' 被设置为 Pandas DataFrame 中的 tag 以将其初始化为 Class,其余属性默认为 InfluxDB field 类型。
以下 Flux 代码是我们朴素贝叶斯函数的开始。它允许您定义预测类别、bucket、预测字段和度量。然后,它会过滤您的数据集以将其划分为训练数据和测试数据。
naiveBayes = (myClass, myBucket, myField, myMeasurement) => {
training_data =
from(bucket: myBucket)
|> range(start: 2020-01-02T00:00:00Z, stop: 2020-01-06T23:00:00Z) // data for 3 days
|> filter(fn: (r) => r["_measurement"] == "zoo-data" and r["_field"] == myField)
|> group()
test_data =
from(bucket: myBucket)
|> range(start: 2020-01-01T00:00:00Z, stop: 2020-01-01T23:00:00Z) // data for 1 day
|> filter(fn: (r) => r["_measurement"] == "zoo-data" and r["_field"] == myField)
|> group()
...我们可以预测以下内容
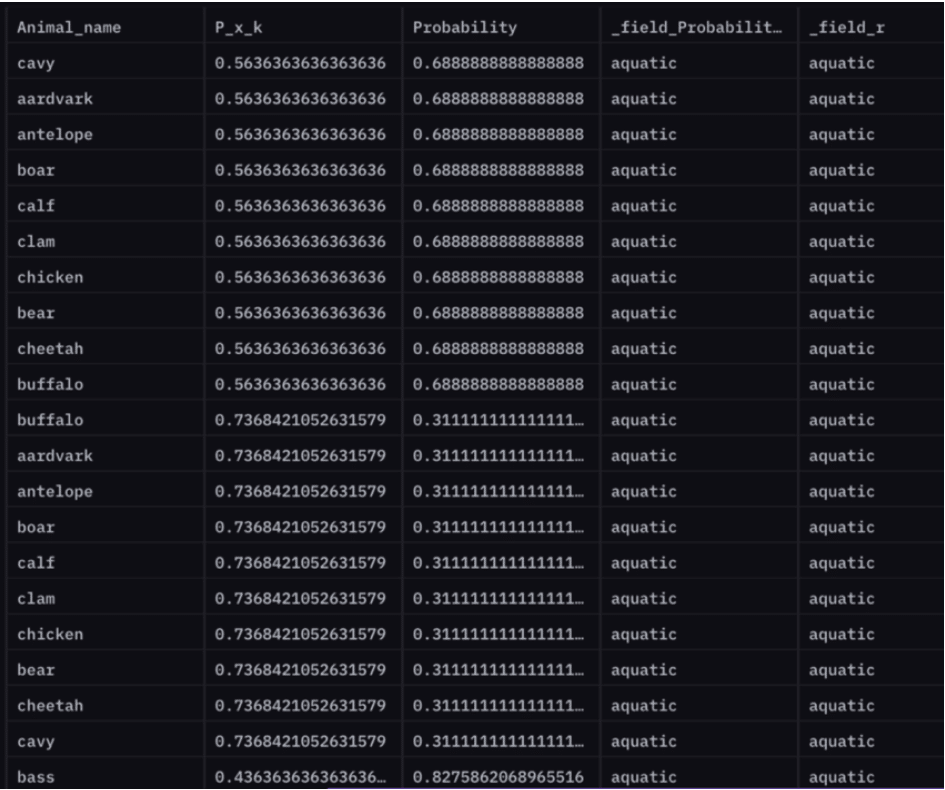
P(airborne | aquatic) (给定动物是否是 airborne,前提是它是否是水生的概率)
例如,如果羚羊不是水生的,则它是 airborne 的概率为 69%。
P(antelope airborne | !aquatic) = 0.688
这一切是如何运作的?
我们基本上是根据时间划分了我们的数据集?– 3 天用于训练,1 天用于测试。在进行一些数据准备之后,我们创建了一个概率表,该表仅使用我们的训练数据计算得出。此时,我们的模型已训练并准备好进行测试。最后,在 predictOverall() 中,我们对该表以及我们的测试数据执行内连接,以计算包含动物特征预测的总体概率表。
...
// calculated probabilities for training data
Probability_table = join(tables: {P_k_x_class: P_k_x_class, P_value_x: P_value_x},
on: ["_value", "_field"], method: "inner")
|> map(fn: (r) =>
({r with Probability: r.P_x_k * r.p_k / r.p_x}))
// predictions for test data computed
predictOverall = (tables=<-) => {
r = tables
|> keep(columns: ["_value", "Animal_name", "_field"])
output = join(tables: {Probability_table: Probability_table, r: r},
on: ["_value"], method: "inner")
return output
}
test_data |> predictOverall() |> yield(name: "MAIN")
...未来,我们计划支持多个预测字段,并利用 密度函数 的强大功能来进行更有趣的预测。此外,我们希望将此生产扩展到能够将训练好的模型外部保存在 SQL 表中。该项目很快将加入 InfluxData Flux 开源贡献库,敬请关注!
您可以零 Flux 经验运行此演示!还在等什么?立即开始使用 Flux 中的机器学习。
非常感谢 Adam Anthony 和 Anais Dotis-Georgiou 在此项目期间提供的宝贵指导和支持。以及对 Magic 团队的喜爱:Mansi Gandhi、Rose Parker 和我。请务必关注 InfluxData 博客 以获取更多精彩演示!
相关链接
- InfluxDB: https://github.com/influxdata/influxdb
- 机器学习数据集: https://archive.ics.uci.edu/ml/datasets.php
- 更多精彩演示: https://influxdb.org.cn/blog/

{kind=link}