InfluxDB 的数据布局和模式设计最佳实践
作者: Anais Dotis-Georgiou / 产品, 用例, 开发者
2020 年 8 月 28 日
导航至
弄清楚 InfluxDB v2 的最佳数据布局对于优化 InfluxDB 使用的资源,以及提高摄取率和查询及任务的性能非常重要。您还需要考虑开发者和用户体验 (UX)。这篇文章将引导您完成为物联网应用程序示例开发模式的过程,并回答以下问题:
- InfluxDB v2 的模式设计和数据布局的一般建议是什么?
- 哪些因素会影响内存、CPU 和存储等计算资源?我该如何针对可用资源优化 InfluxDB?
- 我该如何减少资源使用量?
- 我该如何优化 InfluxDB 模式以提高查询和降采样性能?
- 在设计 InfluxDB 模式时,我还应该考虑哪些其他因素?
- 我的组织将如何与数据交互?用户体验设计如何影响模式?
- 安全和授权 考虑因素如何影响我的模式设计?
- 常见的模式设计错误有哪些?
TL;DR 模式设计和数据布局的一般建议
一般来说,您应该遵守以下建议:
- 在标签中编码元数据。测量 和 标签 是 索引的,而 字段值 不是 索引的。常用的查询元数据应存储在标签中。标签值是字符串,而字段值可以是字符串、浮点数、整数或布尔值。
- 限制序列数量或尝试减少 序列基数。
- 保持 存储桶 和 测量 名称简短明了。
- 避免在测量名称中编码数据。
- 当您需要为数据分配不同的保留策略或需要 身份验证令牌 时,将数据分隔到不同的存储桶中。
最小化您的 InfluxDB 实例
本节介绍影响运行 InfluxDB 实例所需资源的 InfluxDB 概念。我们将学习:
- 序列基数
- 如何计算序列基数
- 摄取率如何影响 InfluxDB 实例大小
- 降采样
序列基数
您应该努力减少 序列基数,以尽量减小 InfluxDB 实例大小和成本。序列基数是 存储桶、测量、标签集 和 字段键 组合在一个 组织 中的唯一数量。InfluxDB 使用名为 TSI 的时间序列索引。TSI 使 InfluxDB 能够处理极高的序列基数。TSI 通过将常用查询的数据拉入内存并将不常访问的数据移动到磁盘上来支持高摄取率。设计数据模式以减少序列基数需要一些预见性和规划。
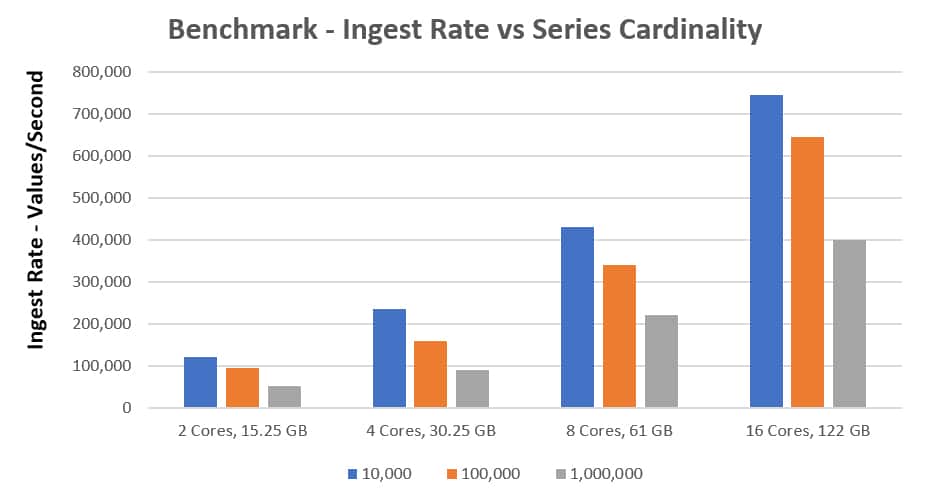
在上图中,蓝色、橙色和灰色线条代表不同的序列基数。例如,如果您在 r4.4xl 实例上运行 InfluxDB,序列基数为 10,000,则每秒可以摄取超过 700,000 个数据点。
计算基数
在我们考虑如何优化数据模式以减少序列基数之前,让我们计算一下植物监控应用程序 MyPlantFriend 的序列基数。MyPlantFriend 监控用户的植物环境(存储温度、湿度、水分和光照指标)。数据布局如下所示:
| 存储桶 | MyPlantFriend |
| 测量 | MyPlantFriend |
| 标签键 |
|
| 字段键 |
|
假设我们有两个用户和几种植物种类:
| 用户 | 植物种类 |
| cool_plant_lady | 兰花 |
| cool_plant_lady | 常见仙人掌 |
| succulexcellent | 梨果仙人掌 |
| succulexcellent | 芦荟 |
| succulexcellent | 玉树 |
我们看到我们有 2 个标签键。对于用户标签键,我们有 2 个标签值。对于植物种类标签键,我们有 5 个标签值。
我们有 1 个存储桶、1 个测量和 4 个字段键。
我们的序列基数将等于:

您的首要任务是避免失控的序列基数。当您将可能无限的数据加载到标签或测量中时,就会发生失控的序列基数。上面的示例是模式的完美示例,该模式很可能导致失控的序列基数。假设您的用户数量会增长,在标签中包含用户名是快速增加基数的一种方法。相反,将用户名保留为字段是明智的。失控序列基数的其他示例在本博客的最后一节中。
摄取率如何影响 InfluxDB
序列基数仅讲述了 InfluxDB 实例的维度和性能故事的一半。最小化序列基数应该是您战略规划工作的一部分,以尽量减少成本和 InfluxDB 大小,但您必须在序列摄取率中上下文化序列基数。序列摄取频率在您的整体实例大小中起着重要作用。
例如,想象一下,如果我在 MyPlantFriend 测量中添加了一些用户指标,如设备 ID 和电子邮件地址。此信息不应在我们每次写入新的环境指标时都写入数据库。每次写入温度指标时都写入相同的电子邮件地址是冗余的。实际上,我们可能只想在用户注册时写入该数据一次。因此,将此用户数据写入不同的存储桶是有意义的。但是,此示例特定于 MyPlantFriend 物联网应用程序,我们假设字段彼此无关。请阅读“InfluxDB 模式设计的最终考虑因素”部分,以了解 UX 如何影响模式设计。
将我们的数据集(用户数据和 MyPlantFriend 指标)写入单独的存储桶具有以下优势:
- 我们可以在注册时写入数据一次,并减少摄取量
- 存储桶位于 InfluxDB 模式中的组织层次结构的顶层,并且具有与其关联的保留策略——每个数据点持续存在的时间。将数据分隔到不同的存储桶中使我们能够为数据分配不同的保留策略。例如,用户数据存储桶将具有无限保留策略。而 MyPlantFriend 存储桶将具有较短的保留策略,因为传感器指标以高频率收集,并且保留历史数据并不重要。
- 我们可以优化我们的常见查询和 降采样 任务 以提高性能。我们将在以下部分描述实例大小、模式设计和查询性能之间的关系。
降采样
与我们如何将数据区分到不同的存储桶以应用单独的保留策略类似,我们还必须考虑我们希望如何 降采样 我们的数据。降采样是使用任务将您的数据从高精度形式聚合为低精度形式的过程。例如,MyPlantFriend 的降采样任务可能如下所示:
- 将每小时温度和光照指标降采样为每周的最小值和最大值。
- 将每小时土壤湿度和湿度指标降采样为每日平均值。
与保留策略结合使用,降采样允许您减小 InfluxDB 的实例大小,因为针对降采样数据的查询扫描、处理和传输的数据更少。当您可以承受丢失高精度数据或当您的查询可以使用降采样聚合精确回答时,您应该执行降采样。使用保留策略来删除旧的高精度数据。这将为您节省存储空间并提高查询性能。
优化您的模式以提高资源利用率
了解何时应用降采样相当简单,但是优化您的 InfluxDB 模式以提高降采样任务性能并减少资源使用量并非易事。更深入地思考降采样会将我们引向新的模式设计。请记住,存储桶、测量和标签已索引,而字段值未索引。因此,按存储桶、测量和标签过滤的查询和任务比按字段过滤的查询和任务性能更高。由于我们预见到以不同速率降采样 MyPlantFriend 字段(空气温度、土壤湿度、湿度和光照),因此将字段分散到不同的测量中具有以下优势:
- 查询更简单(如果您打算创建 模板 或在组织之间回收查询,这将特别有用)。
- 在一个测量中查询 4 个字段的 Flux 查询示例
from(bucket: "MyPlantFriend")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "MyPlantFriend")
|> filter(fn: (r) => r["_field"] == "light")
|> max()- 将字段拆分到单独的测量后,Flux 查询示例
from(bucket: "MyPlantFriend")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "light")
|> max()- 后一个查询更简单、性能更高,并减少了内存使用量。
优化模式设计以提高查询和任务性能的重要性与您的任务数量和频率成正比。在验证您没有失控的序列基数问题后,您需要找到一个平衡点,即最小化序列基数、通过降采样和保留策略减少实例大小,以及优化模式设计以提高查询和任务性能。
InfluxDB 模式设计的最终考虑因素
思考序列基数、数据摄取率和查询性能对实例大小的影响只是周全的数据模式设计的一部分。您还需要考虑您的用户和开发者如何与您的时间序列数据交互,以优化您的 InfluxDB 模式以获得开发者体验。
MyPlantFriend 字段实际上彼此无关。我预计用户不需要将字段相互比较或跨字段执行数学运算。这支持了将字段分离到测量中的建议。让我们将 MyPlantFriend UX 与人类健康应用程序的 UX 进行对比,以突出显示 UX 如何影响模式设计。人类有一套标准的生物健康指标。对于人类健康应用程序,我会在一个测量中写入血氧水平、心率和体温,因为我预见到需要比较指标的组合来评估人类健康。虽然您可以将人类健康应用程序的字段分离到不同的测量中,但您很可能必须使用 joins() 来执行 跨测量或存储桶的数学运算,这在计算上成本更高。
相比之下,将 MyPlantFriend 应用程序的字段分离到不同的测量中是一个很好的策略,因为 joins() 最有可能不会被使用或很少使用。MyPlantFriend 的这种模式更改将使开发者能够轻松编写查询,并为用户提供他们感兴趣的数据。
此外,如果您正在创建应用程序并使用 API,您需要通过将与每个用户关联的数据写入单独的存储桶来解决 安全和授权 问题。InfluxDB 身份验证令牌 确保用户和数据之间的安全交互。令牌属于组织,并标识组织内的 InfluxDB 权限。您可以将令牌范围限定为单个存储桶。
最终模式建议
在考虑失控的基数、降采样和保留策略以及查询性能优化后,我提出以下模式设计:
| 存储桶(保留策略 = 2 周) | WetMetrics |
| 测量 | airt_temp |
| 测量 | 光照 |
| 字段 | 空气温度 |
| 字段 | 光照 |
| 存储桶(保留策略 = 2 天) | DryMetrics |
| 测量 | 湿度 |
| 测量 | 土壤湿度 |
| 字段 | 湿度 |
| 字段 | 土壤湿度 |
| 存储桶(保留策略 = 无限) | UserData |
| 测量 | user_data |
| 标签 | 区域 |
| 字段 | 用户名 |
| 字段 | 植物种类 |
请记住,最终模式是根据以下特定于 MyPlantFriend 物联网应用程序的假设得出的:
- 用户名和植物种类应转换为字段,以避免失控的序列基数。
- 干湿指标需要不同的降采样和保留策略,这使得它们可以拆分为单独的存储桶。
- 字段彼此无关,并且跨测量和/或存储桶执行数学运算的情况将非常罕见。如果字段相关,则应将其包含在同一测量中。
- 添加了区域标签,以提供良好标签的示例。可能的区域数量是限定范围的,因此不会导致失控的基数。
导致失控基数的常见模式设计错误
错误 1:将日志消息作为标签。解决方案 1:由于可能存在无限的基数(例如,日志可能包含唯一的时间戳、UUID 等),因此我们不建议任何人将日志存储为标签。您可以将日志的属性存储为标签,只要基数不是无限的即可。例如,您可以提取日志级别(错误、信息、调试)或日志消息中的一些关键字段。将日志存储为字段是可以的,但与其他解决方案相比,搜索效率较低(基本上是表扫描)。
错误 2:测量过多。这通常发生在人们从键值存储迁移时 - 或将 InfluxDB 视为键值存储时。例如,如果您要将系统统计信息写入 InfluxDB 实例,您可能会倾向于像这样写入数据:Cpu.server-5.us-west.usage_user value=20.0 解决方案 2:而是像这样将该信息编码为标签:cpu, host=server-5, region = us-west, usage_user=20.0
错误 3:将 ID(例如 eventid、orderid 或 userid)作为标签。如果标签值未限定范围,则这是可能导致无限基数的另一个示例。解决方案 3:而是将这些指标作为字段。
我希望本教程能帮助您了解如何最好地设计 InfluxDB 模式。与往常一样,如果您遇到障碍,请在我们的 社区网站 或 Slack 频道上分享它们。我们很乐意获得您的反馈并帮助您解决遇到的任何问题。
