客户案例精选:Index Exchange 如何使用 InfluxDB 平台实现 DevOps 实践现代化
作者:Caitlin Croft / 产品, 用例, 开发者
2021 年 5 月 18 日
导航至
在 InfluxData 工作最棒的事情之一就是能够了解全球 InfluxDB 社区。通过我们的 社区 Slack、社交媒体、团队成员以及线上/线下活动结识新用户总是很有趣。我最近认识了 David Ko,他是 Index Exchange 的 DevOps 工程师。Index Exchange 是一个全球数字媒体广告市场;我最近通过 Zoom 与 David 聊天,讨论他们在 Index Exchange 如何使用 InfluxDB。
Caitlin: 请您简单介绍一下您自己以及您在 Index Exchange 的职业生涯。
David: 我在 Index Exchange 工作了八年多,目前是一名运维工程师。在我的职业生涯中,我做了很多 DevOps、敏捷和站点可靠性工程方面的工作。在此期间,我接触过各种用于各种目的的工具。最近,我一直专注于监控 Index Exchange 收集的基础设施(应用程序和服务器)数据。
Index Exchange 于 2001 年在多伦多成立,此后已发展成为世界上最大的独立广告市场之一。从本质上讲,我们是一家以工程为先的公司,旨在实现数字广告的民主化,以便创作者、故事讲述者和新闻机构能够制作、资助并与世界分享他们的内容和服务。我们通过促进在线广告的展示来实现这一点。请访问我们的网站 了解更多。
例如,当我们访问任何网站时,网页顶部或侧面通常会有横幅广告。每次页面加载时,都会有一个请求查找要放置的广告。他们可能会访问我们的平台;对于每个广告请求,都会有一个自动拍卖,通常称为实时竞价。我们会询问我们的广告供应商是否要对该请求出价。我们收集任何请求的出价——出价最高者获胜,他们的广告将放置在网站上。每当有广告出价拍卖时,都会有大量数据流入和流出。其中一些数据包括
- 出价金额
- 中标者
- 供应商名称
- 广告投放网站的 URL
- 整个广告拍卖/竞价过程的持续时间
- 是否存在任何错误
Caitlin: Index Exchange 的监控随着时间的推移是如何演变的?
David: 我们并非一直都有监控工具;以前,我们主要依赖电子邮件警报。Index Exchange 决定退后一步,从战略上重新思考我们的监控方法。我们发现,在做出进一步更改之前,我们需要全面审视我们的监控解决方案。我们首先使用了一些开源工具。
我们最初实施了 Zabbix,它为我们提供了我们想要的大部分功能。我们能够从我们的服务、网络设备和服务器中获取指标。团队能够使用 Zabbix 设置警报。随着这种转变,Index Exchange 开始探索其他技术,包括 Docker 和 Kubernetes 用于我们的微服务。随着时间的推移,Zabbix 的不足之处变得显而易见;Zabbix 无法支持以期望的粒度收集指标;它不是从 Kubernetes 微服务收集指标的正确工具。
我们开始探索其他选择,并开始更多地了解时间序列数据库。一旦我们了解了有关 TSDB 的基础知识,我们就开始探索可用的选项,包括:OpenTSDB、Apache Cassandra、Prometheus 和 InfluxDB。我们最终选择了 InfluxDB,这个专门构建的时间序列数据库,因为它能够最好地处理指标的长期存储。
随着 Index Exchange 的团队开始更多地使用微服务和容器,Zabbix 不再是一个足够的监控工具变得清晰起来。Zabbix 的设计使得每个指标都与一个物理设备相关联,但这不适用于 Kubernetes。当使用容器时,很难预测哪个容器会一直运行。我们开始采用 Prometheus,虽然我们发现它易于设置和部署,但我们使用 InfluxDB 来存储任何超过 24 小时的指标。我们设置了一个从 Prometheus 到 InfluxDB 的远程存储系统——这样,Prometheus 和 K8s 只存储最多 24 小时的容器指标。这是我们支持 Kubernetes 中微服务的方法。
在使用 TICK Stack 之前,我们还使用 MySQL 数据库来支持 Zabbix 的存储需求。我们意识到这对于我们的需求来说是过度的。对于我们想要通过 Zabbix 完成的任务来说,这太多了——这大约是我们发现 InfluxDB 的时候。我们很快就比 Zabbix 更喜欢它,因为我们不必再处理 MySQL 了!与 Zabbix 的同等产品相比,我们喜欢 Telegraf 中的所有 Telegraf 输入、处理器和聚合器插件以及输出插件。它远不如 Telegraf 灵活或有用。
“我最近一直在使用 Telegraf,我绝对看到了服务器代理的强大功能和灵活性。现在我们可以使用很多不同的输入插件和输出插件,而无需自己制作。” David Ko,Index Exchange DevOps 工程师
Caitlin: 您为什么选择 InfluxData 的 InfluxDB 平台?
David: 我们团队中的某个人一直关注监控趋势和现代工具和堆栈;他们开始注意到一个常见的流行话题是时间序列数据库。随着它们近年来变得越来越流行,这位团队成员注意到了这一点。他们开始四处询问,看看是否有人了解 TSDB。一旦他们了解了时间序列数据库,这个增长最快的数据库类别之一,他们就开始探索可用的选项。
我们喜欢 InfluxDB 有开源版本和企业版本,这意味着如果需要,可以获得支持。我们在实施 InfluxDB 期间有很多乐趣!几年前我们开始使用 InfluxDB OSS,最近开始使用 InfluxDB Enterprise。
Caitlin: Index Exchange 如何使用 InfluxDB?
David: Index Exchange 运维团队的期望是我们应该为其他工程和产品团队采用 DevOps 实践创建基础。当涉及到使用 InfluxDB 进行监控时,我们的团队会设置一个 InfluxDB 集群,用于存储实时数据。我们还使用 Kapacitor 设置有关 InfluxDB 集群中数据存储的警报。
我们开发了文档、指南和培训视频,以帮助团队理解 InfluxDB 平台。我们还有一个开放的 Slack 频道,用于处理任何问题、反馈等。我们会在团队理解工具并帮助改进他们可用的工具时提供帮助。团队可以 ping 我们以获得有关设置警报和自动化指标收集的帮助——我们随时提供帮助!我们大约 30 人的团队为整个工程团队提供支持;运维团队主要位于加拿大多伦多,工程团队位于多伦多、蒙特利尔和基奇纳-滑铁卢。我们在波士顿、旧金山、伦敦、巴黎、悉尼和其他地方也有非工程团队成员。
产品和工程团队的需求影响着我们的项目。但是,最近,我们开始与业务商业方面的团队成员合作。我们希望了解他们的分析师如何使用数据,并更好地了解他们的需求和要求。我们的分析师有时对了解同一机架上同一数据中心内的 CPU 使用率或特定服务器感兴趣。分析团队可能需要了解追溯到数月或数年的历史数据。目前,大量此类数据都驻留在 InfluxDB 中;我们有 Telegraf 代理收集指标,包括 CPU 内存。Telegraf 正在收集基本的服务器指标,包括 CPU、磁盘和其他数据。我们正在使用 Python 脚本将我们的数据写入 InfluxDB。
我们仍然在使用 Prometheus;我们还没有完全淘汰它。这需要一些时间。我们最终希望将 TICK Stack 用于所有事情。我们对 TICKscripts 已经非常熟悉了。很快我们将开始学习 Flux,并计划升级到 InfluxDB 2.0。它将比依赖 Prometheus 更有用。
除了收集每次广告出价/拍卖的指标外,我们还对了解其基础设施的状态感兴趣。有时它是一些基本信息,例如组件是否存活且正在工作。Index Exchange 了解诸如“完成此任务需要多长时间”之类的具体信息也很重要。另一个常见的问题是:在过去 10 分钟内,来自特定数据中心的指定错误发生了多少次。我们希望了解发生的错误数量和错误类型。通过能够量化过去 10 分钟内来自给定数据中心的错误数量,这有助于我们的团队理解和解决这些问题。通过使用 InfluxDB 的数据结构,每个数据中心都是一个 标签。错误类型也是一个标签。InfluxDB 每秒摄取大约 60,000 个指标!
Index Exchange 的数据中心是裸机环境;我们基本上拥有自己的私有云解决方案。我们为我们的内部基础设施解决方案感到自豪。它为我们提供了期望的自主权,这对于数据安全尤其重要。我们保留了每次广告交易的记录,而不仅仅是赢得的广告出价的数据——每个出价都有数据,导致使用和处理了数 TB 的数据。轻松达到 TB 级,甚至 PB 级的数据正在被使用和处理。我在这里转述一下,但几年前有一个关于一年内处理的广告流量数据量超过银河系中星星数量的演示。
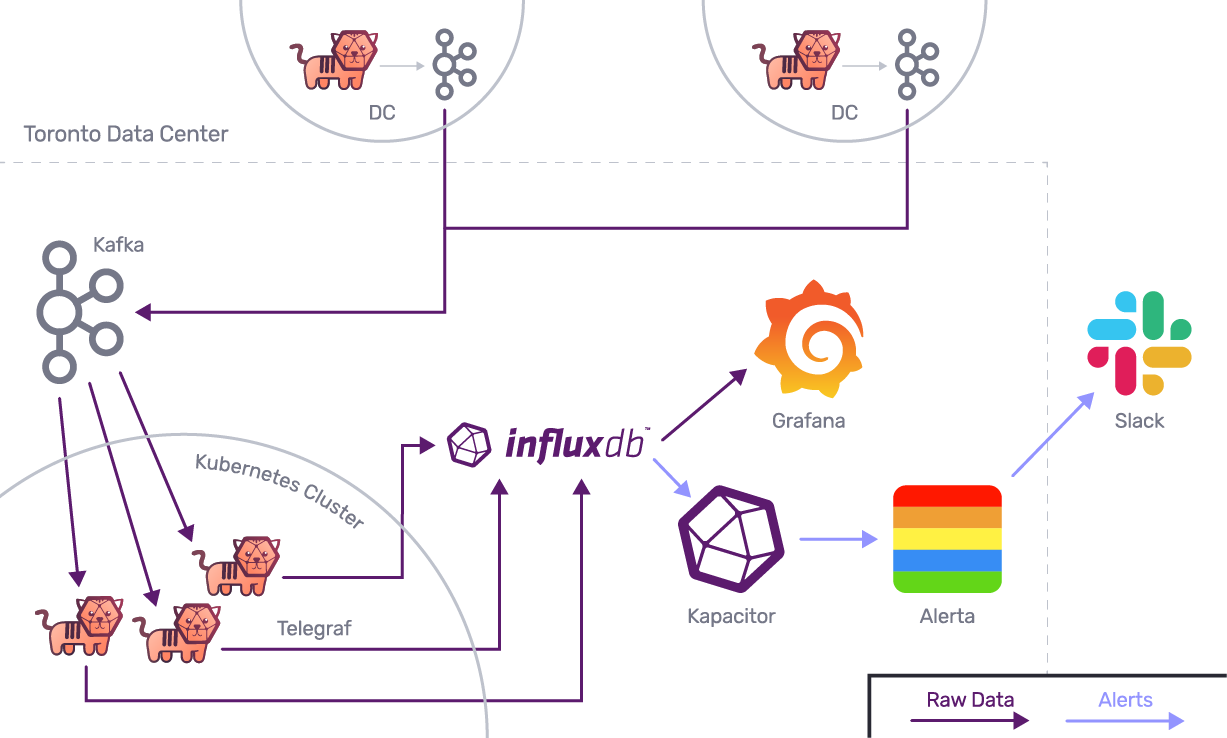
- 此架构图仅代表我们的两个远程数据中心。
- Index Exchange 在全球共有八个数据中心。
- 所有数据中心的数据流都是相同的。
Caitlin: 请您介绍一下 Index Exchange 的数据可视化和警报。
David: 我们仍在确定最适合我们数据的可视化方法。我们在有限的范围内使用 Chronograf 和 Grafana。由于我们正在使用大量的 TICKscripts,因此使用 Chronograf 探索我们的数据非常棒。使用 Chronograf 可视化和分析已存储在 InfluxDB 中的数据非常酷。我们还在 Grafana 中有很多团队使用的图表。因此,目前,Chronograf 和 Grafana 的组合对我们来说很有效。
我们目前正在使用 Kapacitor 进行警报和数据计算。随着我们对 TICKscripts 的了解越来越多,我们开始探索一些更复杂的任务,这些任务您不想使用连续查询来完成。我们仍处于确定最佳实践的早期阶段,但我们希望确保我们不仅仅是以老式的 DevOps 方式做事!
我们还在使用 Slack 和 Alerta。我们所有的 TICKscripts 都传递给 Alerta,然后再传递给 Slack,因为我们希望鸟瞰各种来源、各种级别的所有正在进行的警报。
能够为团队提供我们当前数据的可视化效果,以了解我们所处的位置并了解如何更好地优化我们的运营,这真是太棒了。这些图表还揭示了我们数据中的差距以及我们可以解决的痛点。
Caitlin: Index Exchange 的 DevOps 团队下一步计划是什么?
David: 我们希望探索新技术和方法;例如,我们正在更多地了解 Google 站点可靠性工程的实践。他们的一种技术是创建服务级别指标 (SLI) 和服务级别目标 (SLO)——我们希望将这些方法融入到我们的 InfluxDB 实践中。SLI 只是通知团队他们的服务运行状况。SLI 通常是良好事件与总事件之间的比率。通过将没有错误的请求数量除以请求总数,组织可以确定他们的 SLI。SLO 是您希望该百分比保持在的阈值。Index Exchange 计算这些 SLI 并将其存储在 InfluxDB 中。我们通过使用 TICKscripts 设置警报创建了 SLO。
随着时间的推移,我们希望改进我们的警报。目前,我们只在 CPU 使用率等指标上设置了基本警报。如果特定数据中心组的 CPU 使用率的移动平均值高于某个阈值,我们会收到通知。这种警报意味着收入将受到影响,因为我们的广告服务器无法足够有效地处理拍卖。未来,我们希望拥有更高级的警报。例如,平均而言,广告拍卖大约需要 100 毫秒——因此,如果我们注意到它们的超时时间为 150 毫秒,我们希望能够主动修复延迟的根本原因。
我们有兴趣了解更多关于 InfluxDB 2.0 的信息,并正在考虑升级。参加 InfluxDays North America 2020 非常棒,因为我了解了新概念,包括 InfluxDB IOx。作为 InfluxDB 2.0 的新后端,它听起来非常有趣!我们已经遇到了高基数问题,因此我很想看看 InfluxData 如何应对非常高基数的常见问题。我绝对很期待 InfluxDB 的未来,以及我们如何在 Index Exchange 实施最新的 InfluxDB 版本!
Caitlin: 您有什么 InfluxDB 使用技巧和窍门可以分享吗?
David: 我们最近的 InfluxDB 集群中发生了一次级联故障,因为我们所有其他数据库的复制因子都设置为 3,但我们的节点大小实际上是 4。当我们开始向 InfluxDB 投入更多数据时,一切都很好。但是,我们最终向集群推送了足够的数据,导致了级联故障。我们对 InfluxDB 不够熟悉,无法理解发生了什么。我们与 InfluxData 的支持团队进行了沟通,很快了解到复制因子实际上比我们意识到的更重要,并且建议的复制因子数量是经过优化的。???? 如果您是第一次配置 InfluxDB 集群,我绝对建议尽可能多地利用 InfluxData 的支持团队!是的,文档中有很多内容,但有些信息可能不清楚,并且可能会错误地做出假设。最好让 InfluxData 的支持工程师最初帮助您完成整个过程。
我还建议通读 InfluxData 的文档,以了解他们的建议,并考虑什么最适合您和您的组织。当您进行容量规划、设计数据模式时,您应该考虑 InfluxDB 最佳实践,同时考虑什么最适合您的组织和您的需求。
Caitlin: InfluxDB 如何影响了您的职业生涯?
David: 在实施过程中,我越来越深入地了解 DevOps 实践,尤其是在监控和理解基础设施指标方面。虽然我早就知道带时间戳的数据的概念,但没有什么比推出 InfluxDB 更能让我真正感到舒适和熟悉它们了!
如果您有兴趣分享您的 InfluxDB 故事,请点击此处。
