使用 Telegraf 和 InfluxDB 仪表板进行 COVID-19 跟踪
作者:社区 / 产品, 用例, 开发者
2021年8月10日
导航至
本文由 InfluxData 2021 年夏季实习生 Bar Weiner、Sara Ghodsi、Brandii Warden、Alex Krantz 和 Beth Legesse 撰写。
在今年的年度实习生黑客马拉松活动中,我们决定对来自全国各地的实时时间序列 COVID-19 数据进行建模和监控。由于新的变种正在被发现并在所有 50 个州以惊人的速度传播,COVID-19 仍然对公众构成重大风险,特别是对于未接种疫苗的个人或计划在美国境内旅行的人。
项目描述
我们创建了一个平台,使围绕 COVID-19 数据的关键信息更易于访问,包括特定地点的疫苗接种率和阳性病例数。
我们最初的想法是从头开始创建一个 React 应用程序,并使用 Giraffe 在我们的自定义应用程序上可视化数据。然而,在花了半天时间规划我们想要的所有功能、制定计划并获得导师的反馈后,我们认为使用 InfluxDB Cloud 免费服务来查询和可视化我们的数据,同时测试新的 UI 功能,更现实和直接。
为了开始我们的流程,我们找到了许多不同的公共 COVID-19 API。由于每个 API 都有独特的数据点集,我们选择了符合我们目标的 API。然后,我们尝试从 API 端点下载 JSON 或 CSV 文件,其中包含我们需要的数据,并将它们输入到 InfluxDB 中进行分析和可视化。在努力格式化文件以符合 Influx 规范后,我们意识到使用 Telegraf 系统地且可重复地摄取数据会更有效。
以下是我们使用的 API 端点列表
- https://disease.sh/v3/covid-19/jhucsse/counties
- https://disease.sh/v3/covid-19/nyt/states?lastdays=30
- https://disease.sh/v3/covid-19/states
- https://raw.githubusercontent.com/owid/covid-19-data/master/public/data/vaccinations/us_state_vaccinations.csv
进展顺利之处
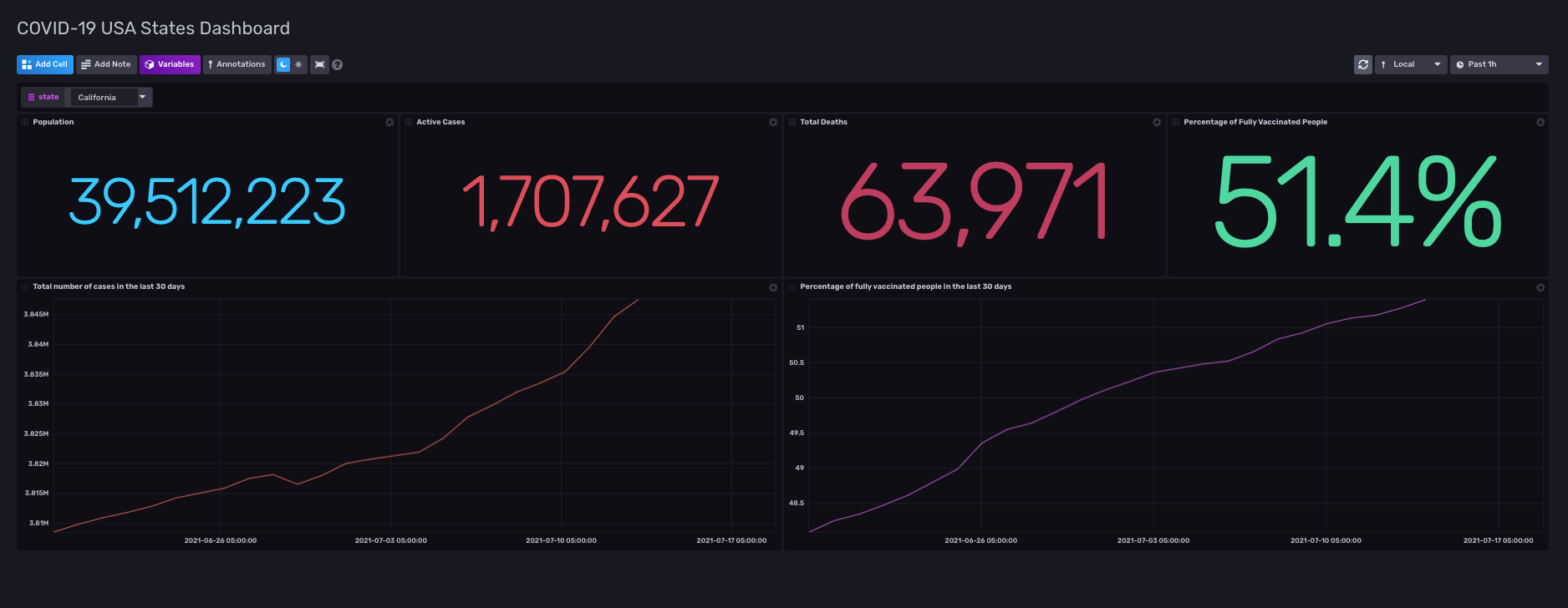
我们为我们的图表和地图创建了三个仪表板。一个仪表板包含 COVID-19 病例和死亡人数的统计数据,以及完全接种疫苗的人口百分比。我们还包括了过去 30 天的总病例数和疫苗接种率的两个图表。还有一个用于更改州的选择,我们使用变量填充了该选择。如果您从下拉列表中选择另一个州,统计数据将更改以显示您选择的州的相应数据。
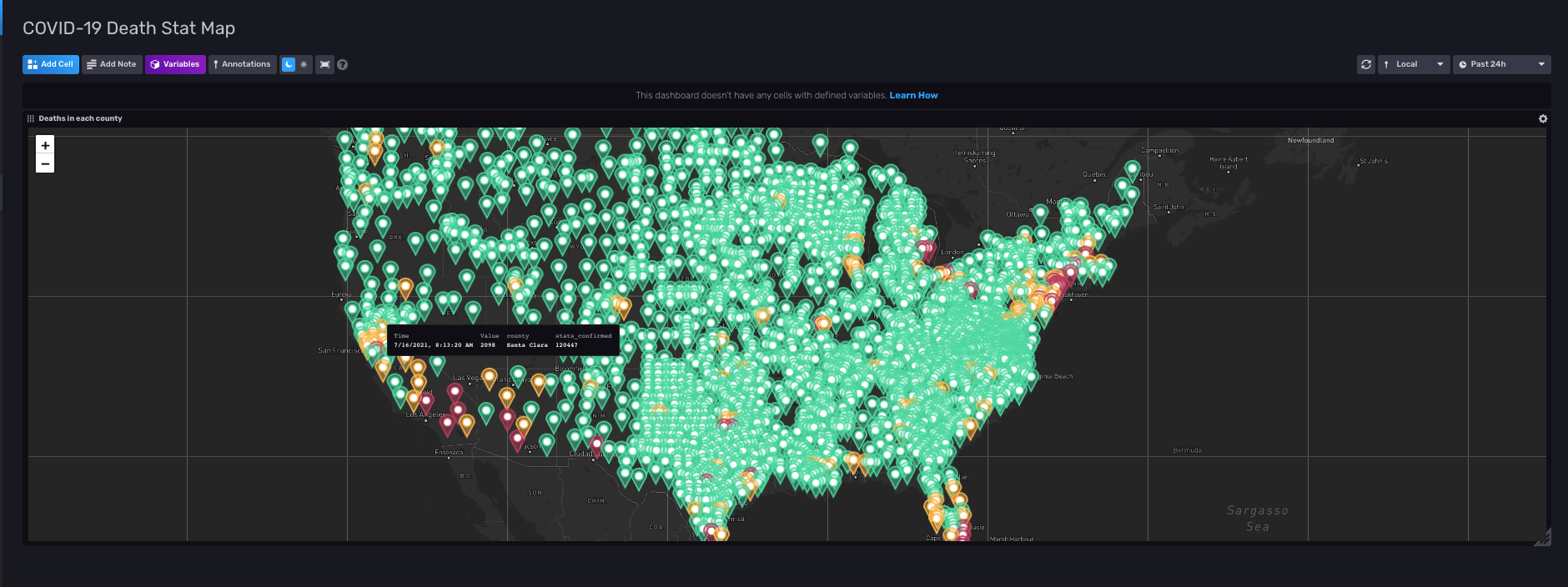
我们的第二个仪表板在美国地图上显示了每个县的死亡人数。我们还包括了每个县的已确诊病例数。地图上的每个点都有一个阈值,用于检查死亡人数是高还是低,并根据该阈值,我们将县的颜色设置为绿色、黄色或红色。此地图对于识别美国各地的疾病中心非常实用。颜色为红色的县报告的死亡人数超过 2000 人,这意味着 COVID-19 在该地区非常普遍。
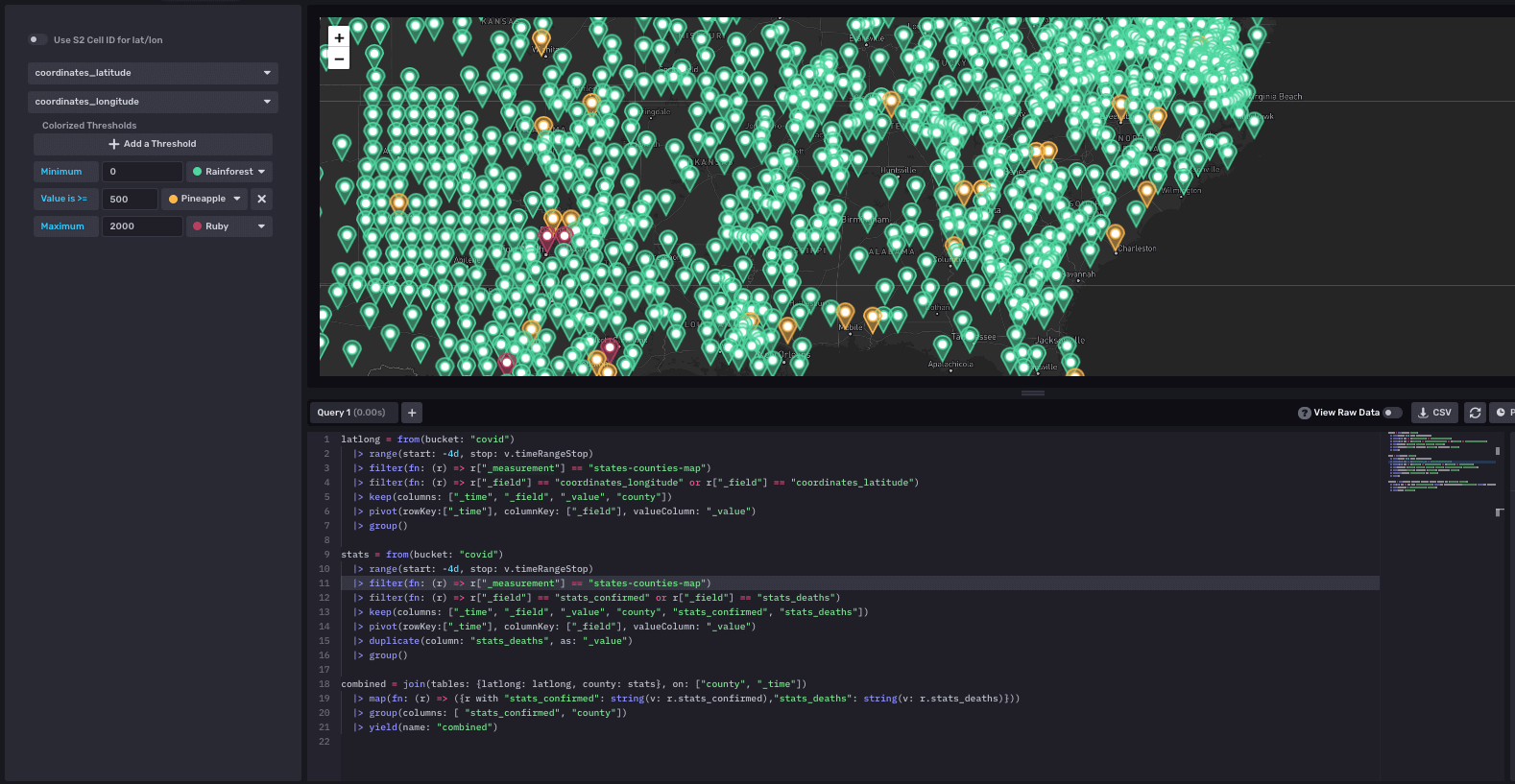
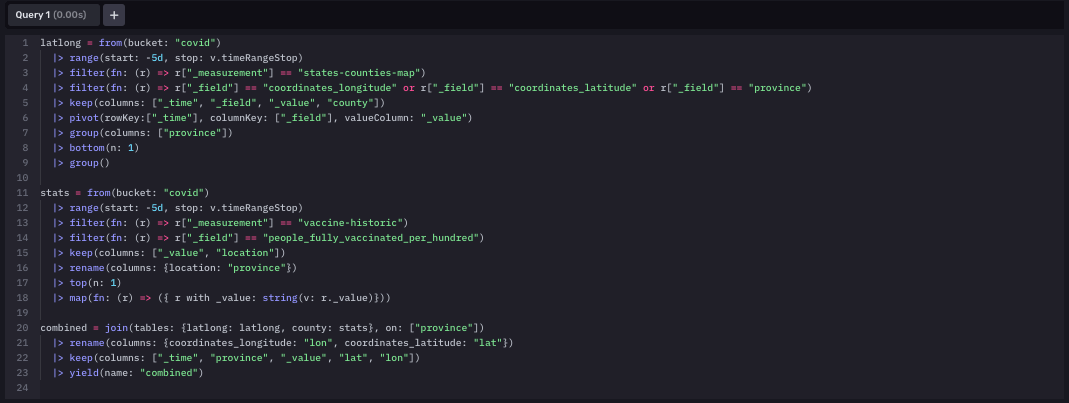
此地图的查询是我们编写的所有查询中最复杂的。为了使地图显示点,我们必须将每个县的纬度和经度与死亡人数和已确诊病例数的值配对。我们不得不使用 join 函数来连接多个数据集,以实现此目的,并将数据与其对应的坐标对齐。
最后一个仪表板在另一张地图上显示了每个州的疫苗接种率。此地图还设置了阈值,根据每个州的疫苗接种率为每个州分配不同的颜色。如果一个州超过 50% 的人口完全接种了疫苗,则显示为绿色。如果疫苗接种率在 40% 到 50% 之间,则该州为黄色,低于 40%,我们将其指定为红色。当一个人决定前往另一个州时,此阈值最有用:他们可以在地图上查找该州,看看旅行是否安全。
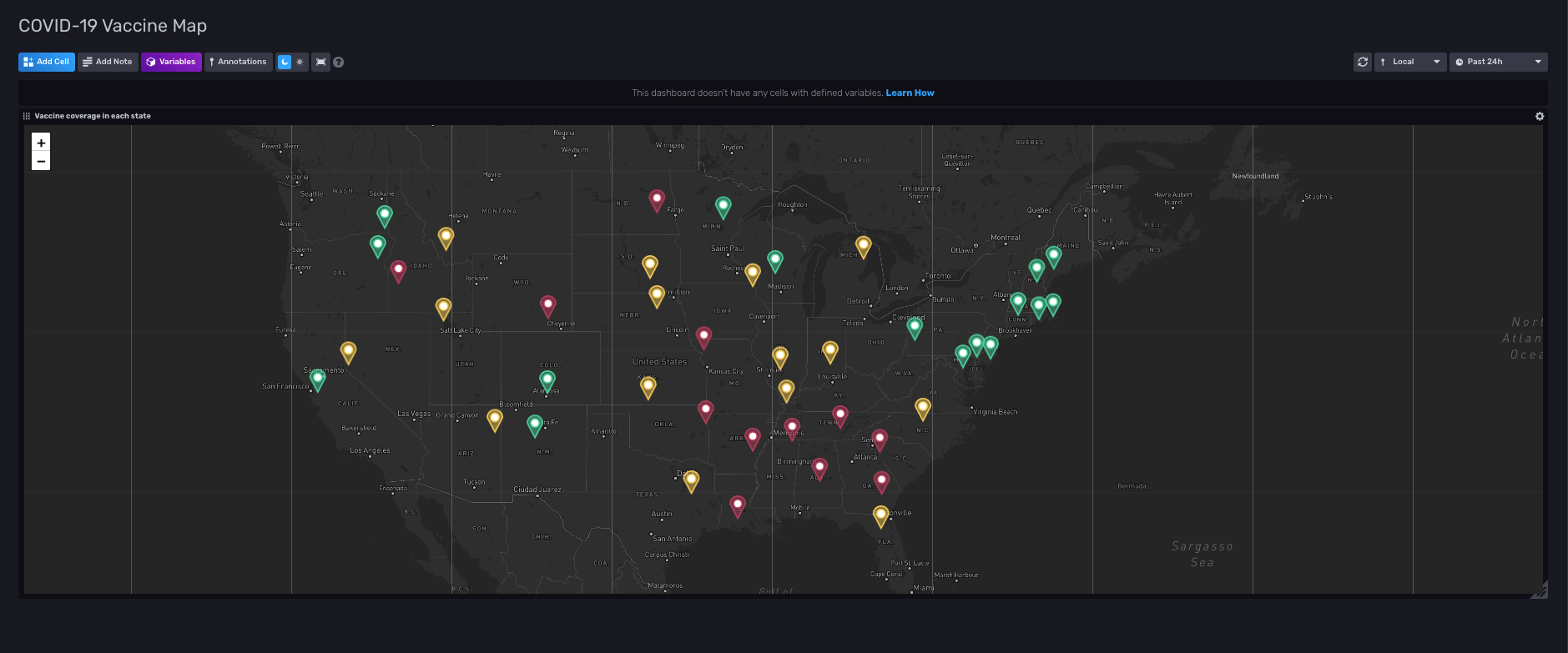
我们的疫苗接种地图的查询与另一张地图非常相似。不同之处在于我们在每个查询中访问的数据。
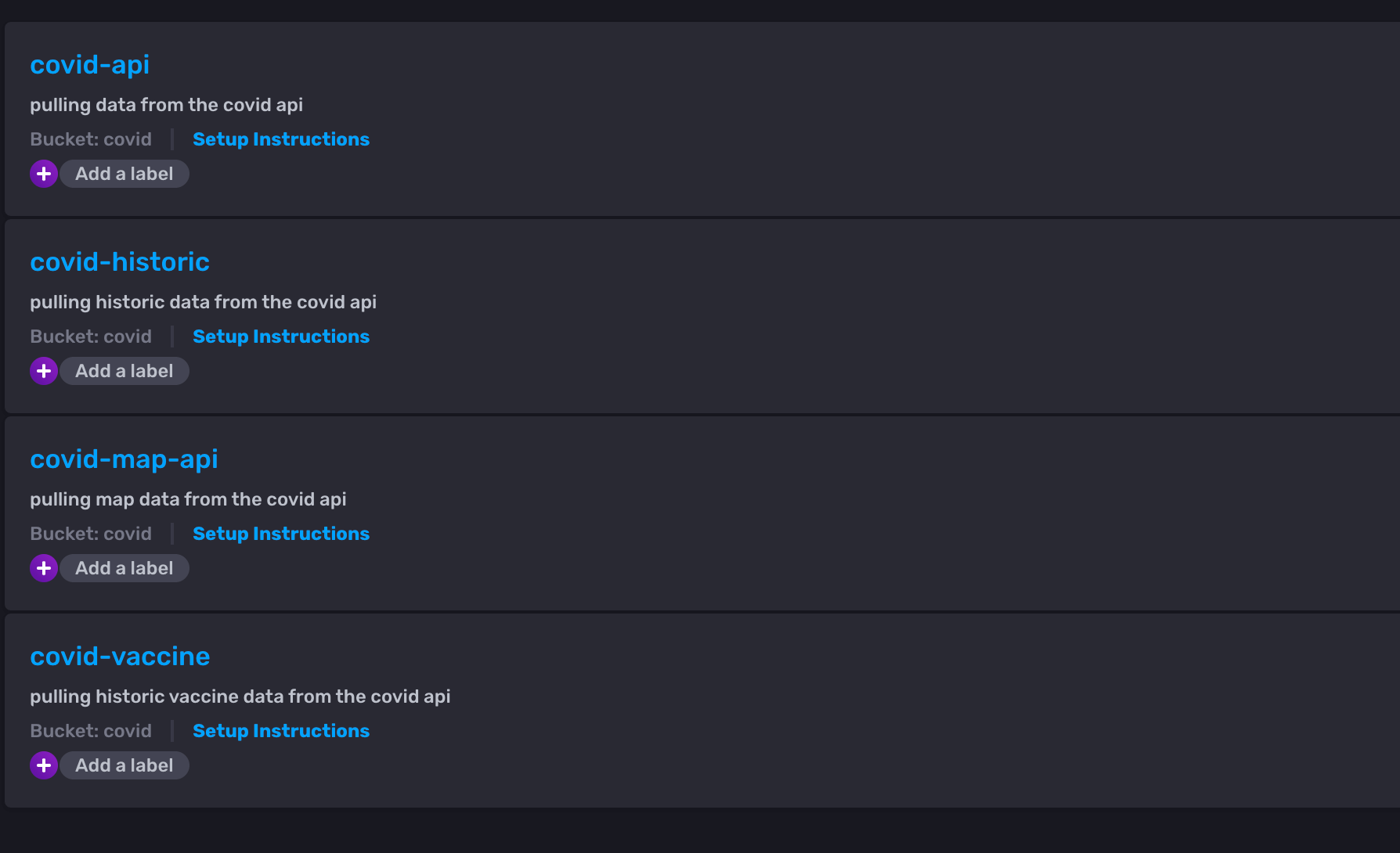
为了将数据拉入我们的 covid bucket,我们设置了四个不同的 Telegraf 配置。每个配置都有其独特用途,因为我们找到了不同的 API 端点,这些端点返回了我们想要从中摄取的数据类型。每个仪表板都需要不同的配置和数据点,因此我们需要从各种 API 中找到丰富的数据,以进行我们期望的监控和分析。
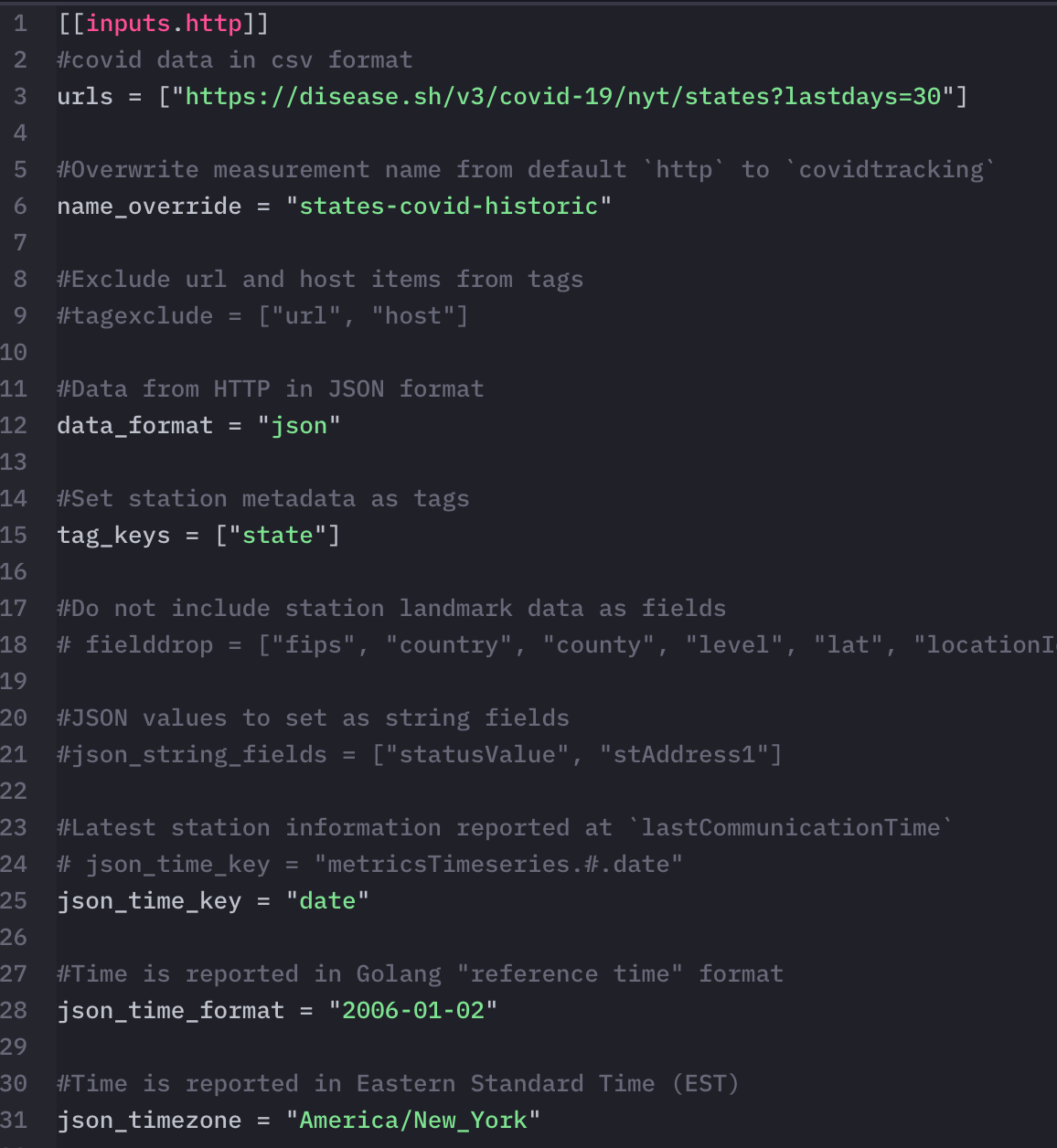
例如,covid-historic telegraf 从 API 中提取数据,该 API 返回过去 30 天的 COVID-19 统计数据。然后,我们将数据存储在 states-covid-historic measurement 中,并在 COVID-19 美国各州仪表板上的第一个图表的查询中使用它。
进展不顺利之处
在我们的黑客马拉松冲刺期间,我们遇到了许多挑战,但我们做得好的地方是彼此沟通,意识到我们尚不知道什么,并有效地寻求帮助以完成我们的目标。
在自动化 Telegraf 时,我们在使用免费 Cloud2 帐户拉取大量数据集(如美国每个县的 COVID-19 统计数据)时,面临着固有的基数和查询写入限制问题。一度,我们不得不研究如何降低基数,甚至在此过程中删除我们的 bucket:即使我们降低了基数使用量,我们的 bucket 也需要几个小时才能重置,这在我们紧张的开发过程中是无法节省的。
我们还遇到了数据显示问题,尤其是在地图格式中。为此,我们不得不退后一步,查看我们的数据,并决定最好在尝试对其编写查询并将其馈送到可视化之前重构数据。在导师的帮助下,我们更接近这个目标,最终,我们通过编写 Flux 脚本来配置我们的仪表板和整理我们的数据来实现它。对于我们整个团队来说,编写 Flux 并跨不同的产品产品工作以更全面地了解公司及其业务,真是一次很酷的体验。
最终想法
在未来,我们希望在实习期的剩余时间里继续导入数据,以便拥有一个可以分析的数据仓库。此外,一些改进将使项目更加完整,例如添加使用阈值检查的警报,并增加 bucket 保留策略,以便我们可以查看历史数据,因为我们目前只能查看过去 30 天的数据。添加警报可能会非常有用,因为它允许您获得关于您所在县或州当前疫苗接种状态的通知。
如果我们重复这个项目,我们将预处理我们的数据,通过删除无关数据并将位置数据与每个县或州预先关联,使其更容易使用。在导入数据之前组合数据将防止我们在 InfluxDB 中处理不相关的数据,从而缩短我们的查询时间并多次达到基数限制。它还将极大地简化我们的 Telegraf 配置,因为我们不需要围绕别人的数据结构工作。
指向我们模板的链接
我们从我们的项目中创建了一个模板。您可以在社区模板存储库中看到它:https://github.com/influxdata/community-templates/tree/master/covid19-usa-states
