配置 Docker Telegraf 输入插件
作者:Anais Dotis-Georgiou / 产品, 用例, 开发者
2018 年 10 月 22 日
导航至
值得庆幸的是,使用 InfluxDB 监控我的容器出乎意料地容易。不幸的是,从容器数据中获取价值并非易事。理解如何管理和分配容器资源远非易事,而 DevOps 对我来说仍然很大程度上是神秘的。当我开始在本地监控一些容器时,我对 DevOps 的不理解变得更加突出。在这篇博文中,我将分享我更好地理解容器监控的旅程。
但首先,让我向您展示
- 我如何在 Docker 容器中配置反向代理和 nginx 服务器来提供静态 HTML
- 我如何使用 Telegraf 和 InfluxDB 在本地监控这些容器
- 这项练习引发的所有问题
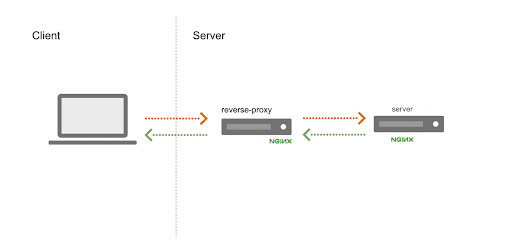
我如何在 Docker 容器中配置反向代理和 nginx 服务器来提供静态 HTML
我决定在我的本地机器上监控容器。我非常喜欢观看这个 教程,我向任何新的 Docker 用户推荐它。首先,我创建了两个镜像。第一个是 nginx 镜像,它提供静态 HTML 页面。第二个是 nginx 反向代理镜像,它使用内置 DNS 解析器将请求转发到所有静态应用容器,并采用轮询调度。为了构建这两个镜像,我创建了一个“app”目录和一个“proxy”目录。在我的“app”目录中,我创建了一个 dockerfile(一个包含构建 docker 镜像所需的所有命令的文件)和我的静态 HTML。dockerfile 看起来像这样
FROM nginx:alpine
COPY static.html /usr/share/nginx/html它包含 docker 构建 nginx 容器(特别是 alpine 版本)的指令。Static.html 被复制到 nginx 的静态 HTML 文件的默认目录中,以便它可以提供该站点。由于我只对了解使用 InfluxDB 监控我的容器是什么感觉感兴趣,所以我的 HTML 是令人痛苦的无聊的“Hello World”页面
<html>
<header><title>Monitoring Docker with InfluxDB</title></header>
<body>
Hello world
</body>
</html>为了构建 nginx 静态应用镜像,我使用命令 docker build -t "app" . -p 9000:80。此命令构建镜像并使用名称“app”标记它。它还将端口 9000 重新映射到 localhost 上的端口 80。
在我的 proxy 目录中,我也有一个 dockerfile,其中包含此镜像构建的指令。它看起来像
FROM nginx:alpine
COPY proxy.conf /etc/nginx/conf.d/这里我正在将我的代理配置文件复制到 nginx 的默认配置目录中。Proxy.conf 包含指定代理应在何处侦听请求以及 DNS 解析器应如何运行的指令
server {
listen 80;
resolver 127.0.0.11 valid=5s;
set $app_address http://app;
location / {
proxy_pass $app_address;
}
}具体来说,proxy.conf 告诉代理服务器在 localhost 上的端口 80 上侦听任何传入请求。我还包括内置 DNS 解析器的 IP 地址 (127.0.0.11),以便代理知道将请求转发到哪里。此 DNS 解析器包含所有正在运行的应用容器的所有 IP 地址。它将选择一个 IP 地址,然后在其余容器中执行轮询 DNS 负载均衡。通过设置 valid=5s,我们告诉代理将缓存时间更改为 5 秒。这样,代理将更快地发现对 DNS 服务器所做的任何更改。这对我很重要,因为我希望能够扩展几个容器,并立即在我的 InfluxDB 实例中看到更改的反映。如果我不将参数更改为 valid 变量,它将默认为 5 分钟。
在生产环境中,更长的缓存时间是有意义的,因为它有助于最大限度地减少 DNS 解析器上的负载。但是,我没有那种时间和耐心。更不用说我必须启动大量“app”容器才能看到较小的 valid 变量的负面影响。由于这个项目的目标不是试图对 DNS 服务器执行压力测试,也不是最大限度地利用我的资源,所以 5 秒的缓存时间效果很好(信不信由你,我有时尽量不破坏东西)。最后,将 proxy_pass 设置为变量 $app_address 强制代理尝试发现该 $app_address 变量中包含的信息。为此,它必须每次都在 DNS 解析器中查找它,以确保地址已更新。
配置难题的最后一部分是 docker-compose.yml 和 docker-telegraf.conf。docker-compose.yml 包括
---
version: '2'
services:
app:
build: app
proxy:
build: proxy
ports:
- "80:80"这个 yml 仅仅指定将有两个服务正在运行:app 和 proxy。它还包含相对路径和构建指令。
我如何使用 Telegraf 和 InfluxDB 在本地监控这些容器
Telegraf 是 InfluxData 的开源指标和事件收集代理。它是插件驱动的,所以我需要包含一个带有适当的输入和输出插件的配置文件,以便从我的 Docker 容器中收集指标。我正在使用 Docker 输入插件 和默认的 InfluxDB 输出插件。为了生成我的配置文件 docker-telegraf.conf,我在我的项目目录中运行 telegraf --input-filter docker --output-filter influxdb config > docker_telegraf.conf。我将这些容器指标发送到默认的“telegraf”数据库。但是,您可以通过更改配置文件中的第 95 行来创建一个名称由您选择的新数据库
## The target database for metrics; will be created as needed.
database = "<database of your wildest imagination>"我保留了 文档 中描述的 Docker 输入的默认路径和数据库配置设置。具体来说,我的配置文件的输入部分看起来像这样
[[inputs.docker]]
## Docker Endpoint
## To use TCP, set endpoint = "tcp://[ip]:[port]"
## To use environment variables (ie, docker-machine), set endpoint = "ENV"
endpoint = "unix:///var/run/docker.sock"
## Set to true to collect Swarm metrics(desired_replicas, running_replicas)
gather_services = false
## Only collect metrics for these containers, collect all if empty
container_names = []
## Containers to include and exclude. Globs accepted.
## Note that an empty array for both will include all containers
container_name_include = []
container_name_exclude = []
## Container states to include and exclude. Globs accepted.
## When empty only containers in the "running" state will be captured.
# container_state_include = []
# container_state_exclude = []
## Timeout for docker list, info, and stats commands
timeout = "5s"
## Whether to report for each container per-device blkio (8:0, 8:1...) and
## network (eth0, eth1, ...) stats or not
perdevice = true
## Whether to report for each container total blkio and network stats or not
total = false
## Which environment variables should we use as a tag
##tag_env = ["JAVA_HOME", "HEAP_SIZE"]
## docker labels to include and exclude as tags. Globs accepted.
## Note that an empty array for both will include all labels as tags
docker_label_include = []
docker_label_exclude = []
## Optional TLS Config
# tls_ca = "/etc/telegraf/ca.pem"
# tls_cert = "/etc/telegraf/cert.pem"
# tls_key = "/etc/telegraf/key.pem"
## Use TLS but skip chain & host verification
# insecure_skip_verify = false接下来,我想检查代理是否正在工作。我可以扩展我正在运行的应用容器的数量,以确保代理正在工作。我使用 docker-compose up --scale app=3 启动 3 个应用容器。接下来,我访问 https://。刷新几次后,我看到以下输出
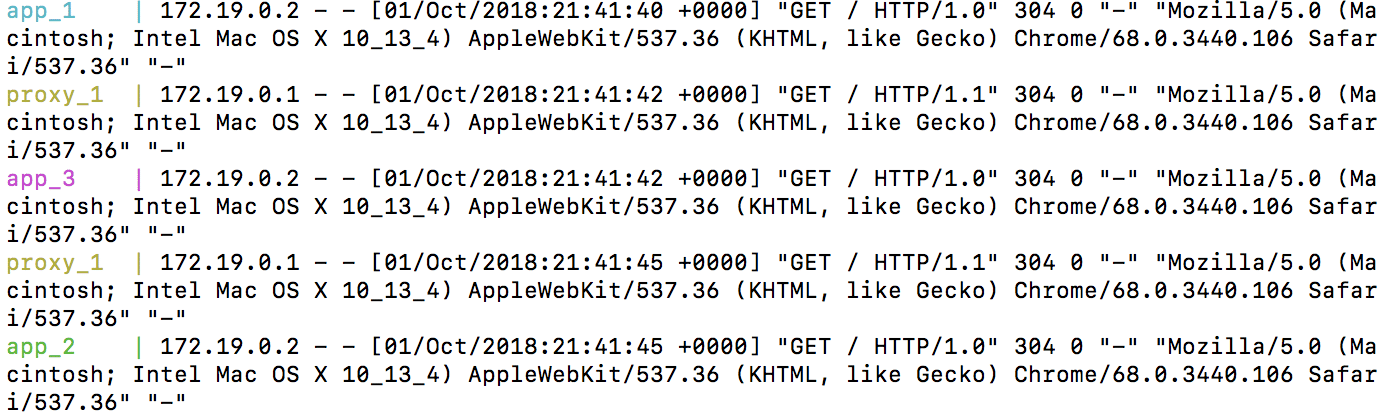
耶!代理成功工作了。请求被定向到每个容器。
这个代理测试还将使我能够看到 Telegraf 是否成功地从我的容器中收集指标。我访问 https://:8888 以调出 Chronograf,InfluxData 的开源数据可视化和警报管理平台。在名为“telegraf”的默认数据库中,我现在可以看到我的所有 docker 指标。我运行这个查询...
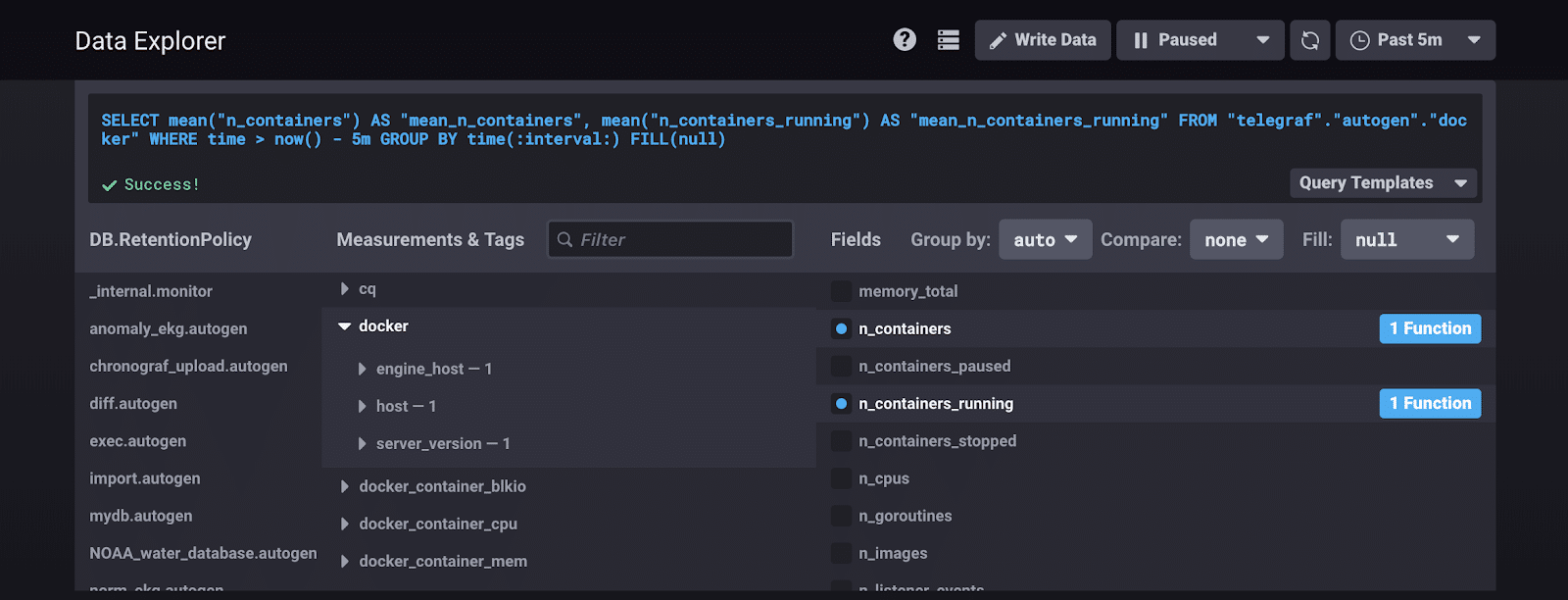
...来监控容器总数和正在运行的容器数。我得到这个预期的结果
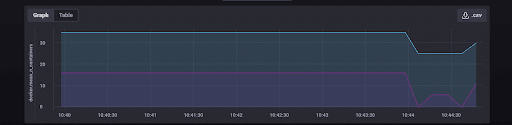
哇!Telegraf 正在将容器指标发送到 InfluxDB。我的配置成功了。我可以开箱即用地收集以下指标
- 已用文件描述符的数量
- CPU 数量
- 容器数量
- 正在运行的容器数量
- 已停止的容器数量
- 已暂停的容器数量
- 镜像数量
- goroutine 数量
- 侦听器事件的数量
- 总内存
但我可以使用更多。如果我使用 devicemapper 存储驱动程序配置 docker,那么我可以访问大约 5 倍的指标。如果我配置 HEALTHCHECK,我可以报告我的容器的健康状况,或者我可以监控整个 Docker Swarm。有很多指标。
这项练习引发的所有问题
我想问一些棘手的问题,领导一次成功的数据调查,并找到技术罪魁祸首。但是,当我查看所有可用的指标时,我开始感到不知所措。我不知道该如何处理它们。我意识到我对 DevOps 监控、测试和警报一窍不通。我想问一些深入的问题,但首先,我必须找到这些基本问题的答案
- Docker 默认如何分配资源?
- 我可以为一个进程分配一定数量的 GHz 吗?(剧透:哈哈哈...不能)
- 在本地监控 Docker 如何才能实用?
- 最重要的 10 个指标是什么?这是一个相关的问题吗?这些问题中有好的问题吗?
- 监控 Docker 容器与监控 Kubernetes 相比如何?
- Docker Swarm 与 Kubernetes 相比如何?
- DevOps 工程师运行哪种类型的测试来确定容器资源的阈值?
- DevOps 测试过程是什么样的?
- DevOps 工程师在什么时候决定自动化扩展?
- 我如何使用 InfluxDB 监控容器内的应用程序?
我希望这篇博文能帮助您开始监控您的 Docker 容器。我知道它帮助我找到了我知识中的空白。我期待着尝试回答这些问题,并分享我更好地理解容器监控的探索之旅。如果您发现任何令人困惑的地方或随时向我寻求帮助,请告诉我。您可以访问 InfluxData 的 社区网站 或在 Twitter 上 @InfluxDB 联系我们。最后,我为您提供这个脑筋急转弯。
 <figcaption> 我为您的视觉享受而画的变色龙 </figcaption>
<figcaption> 我为您的视觉享受而画的变色龙 </figcaption>
