Compactor:数据库性能的隐藏引擎
作者:Paul Dix / Nga Tran / 开发者
2023 年 3 月 27 日
导航至
本文最初发表于 InfoWorld,并经许可在此处重新发布。
Compactor 在单独的服务器上的后台处理关键的摄取后和查询前工作负载,从而为数据摄取实现低延迟,为查询实现高性能。
对大量数据的需求增加了对能够以尽可能低的延迟(又名高性能)处理数据摄取和查询的数据库的需求。为了满足这种需求,数据库设计已转向优先考虑在摄取和查询期间执行最少的工作,而其他任务则在后台作为摄取后和查询前执行。
本文将描述这些任务以及如何在完全不同的服务器中运行它们,以避免与处理数据加载和读取的服务器共享资源(CPU 和内存)。
摄取后和查询前的任务
在数据摄取完成之后和数据读取开始之前可以继续执行的任务将根据数据库的设计和功能而有所不同。在本文中,我们描述了这三个最常见的任务:数据文件合并、删除应用和数据去重。
数据文件合并
查询性能是大多数数据库的重要目标,良好的查询性能要求数据组织良好,例如排序和编码(又名压缩)或索引。由于 查询处理可以处理无需解码的编码数据,并且查询需要读取的 I/O 越少,运行速度越快,因此将大量数据编码到几个大文件中显然是有益的。在传统数据库中,将数据组织成大文件的过程是在加载时通过将摄取的数据与现有数据合并来执行的。数据组织期间还需要排序和编码或索引。因此,在本文的其余部分,我们将讨论与文件合并操作携手合作的排序、编码和索引操作。
快速摄取已变得越来越关键,对于处理大量和连续的传入数据以及近乎实时的查询至关重要。为了支持数据摄取和查询的快速性能,新摄取的数据不会在加载时与现有数据合并,而是存储在一个小文件(或仅支持内存数据的数据库中的小块内存)中。文件合并在后台作为摄取后和查询前任务执行。
LSM 树(日志结构合并树)技术的变体通常用于合并它们。使用此技术,存储新摄取数据的小文件应与其他现有数据文件一样进行组织(例如,排序和编码),但由于它是一小部分数据,因此对该文件进行排序和编码的过程微不足道。所有文件组织相同的原因将在下面的数据压缩部分中解释。
有关数据合并好处的示例,请参阅这篇关于数据分区的文章。
删除应用
同样,数据删除和更新过程需要重组数据并花费时间,特别是对于大型历史数据集。为了避免这种成本,当发出删除时,数据实际上并未被删除,而是将墓碑添加到系统中以“标记”数据为“软删除”。实际的删除称为“硬删除”,将在后台完成。
更新数据通常实现为删除后跟插入,因此,其过程和后台任务将是数据摄取和删除的任务。
数据去重
时间序列数据库(如 InfluxDB)接受多次摄取相同的数据,但随后应用去重以返回非重复结果。有关去重应用的具体示例,请参见关于 去重的这篇文章。与数据文件合并和删除过程一样,去重也需要重组数据,因此是在后台执行的理想任务。
数据压缩
摄取后和查询前的后台任务通常称为数据压缩,因为这些任务的输出通常包含较少的数据并且更压缩。严格来说,“压缩”是一个后台循环,用于查找适合压缩的数据,然后对其进行压缩。但是,由于存在如上所述的许多相关任务,并且由于这些任务通常涉及相同的数据集,因此压缩过程在同一查询计划中执行所有这些任务。此查询计划扫描数据,查找要删除和去重的行,然后根据需要对其进行编码和索引。
图 1 显示了压缩两个文件的查询计划。数据库中的查询计划通常以自下而上的流式/流水线方式执行,图中的每个框代表一个执行运算符。首先,并发扫描每个文件的数据。然后应用墓碑来过滤已删除的数据。接下来,数据按主键(又名去重键)排序,生成一组列,然后再经过去重步骤,该步骤应用合并算法以消除主键上的重复项。然后,如果需要,对输出进行编码和索引,并将其存储回一个压缩文件中。当压缩数据存储后,可以更新存储在数据库目录中的文件 1 和文件 2 的元数据以指向新压缩的数据文件,然后可以安全地删除文件 1 和文件 2。在压缩文件后删除文件的任务通常由数据库的垃圾收集器执行,这超出了本文的范围。
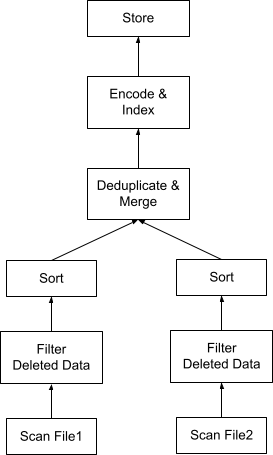
即使图 1 中的压缩计划在一个数据扫描中结合了所有三个任务,并避免了三次读取同一组数据,但过滤器和排序等计划运算符仍然不便宜。让我们看看是否可以进一步避免或优化这些运算符。
优化的压缩计划
图 2 显示了图 1 中计划的优化版本。有两个主要更改
- 运算符“过滤已删除数据”被推送到 Scan 运算符中。这是一种有效的 谓词下推 方法,可在扫描时过滤数据。
- 我们不再需要 Sort 运算符,因为输入数据文件在数据摄取期间已按主键排序。“去重和合并”运算符的实现是为了使其输出数据保持按与其输入相同的键排序。因此,如果需要,压缩数据也按主键排序以供将来压缩。
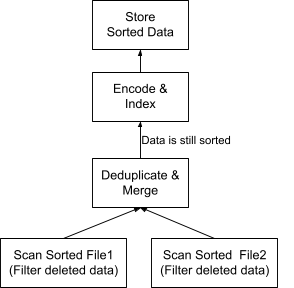
请注意,如果两个输入文件包含不同列的数据(这在某些数据库(如 InfluxDB)中很常见),我们将需要保持它们的排序顺序兼容,以避免重新排序。例如,假设主键包含列 a、b、c、d,但文件 1 仅包含列 a、c、d(以及其他不属于主键的列),并且按 a、c、d 排序。如果文件 2 的数据在文件 1 之后摄取,并且包含列 a、b、c、d,则其排序顺序必须与文件 1 的排序顺序 a、c、d 兼容。这意味着列 b 可以放在排序顺序中的任何位置,但 c 必须放在 a 之后,d 必须放在 c 之后。为了实现一致性,新列 b 可以始终作为排序顺序中的最后一列添加。因此,文件 2 的排序顺序将为 a、c、d、b。
保持数据排序的另一个原因是,在列式存储格式(如 Parquet 和 ORC)中,编码与排序数据配合良好。对于常见的 RLE 编码,基数越低(即,不同值的数量越少),编码效果越好。因此,将基数较低的列放在主键的排序顺序中首先不仅有助于在磁盘上压缩更多数据,而且更重要的是有助于查询计划更快地执行。这是因为数据在执行期间保持编码状态,如 关于物化策略的论文中所述。
压缩级别
为了避免昂贵的去重操作,我们希望以一种我们知道数据文件是否可能与其他文件共享重复数据的方式管理数据文件。这可以通过使用数据重叠技术来完成。为了简化本文其余部分的示例,我们将假设数据集是时间序列,其中数据重叠意味着它们的数据在时间上重叠。但是,重叠技术也可以在非时间序列数据上定义。
避免重新压缩良好压缩文件的策略之一是为文件定义级别。级别 0 表示新摄取的小文件,级别 1 表示压缩的、非重叠的文件。图 3 显示了在第一轮和第二轮压缩之前和之后的文件及其级别的示例。在任何压缩之前,所有文件均为级别 0,并且它们可能以任意方式在时间上重叠。在第一次压缩之后,许多小的级别 0 文件已被压缩为两个大的、非重叠的级别 1 文件。与此同时(请记住这是一个后台进程),加载了更多小的级别 0 文件,这些文件启动了第二轮压缩,将新摄取的级别 0 文件压缩到第二个级别 1 文件中。鉴于我们始终保持级别 1 文件非重叠的策略,如果级别 1 文件不与任何新摄取的级别 0 文件重叠,我们不需要重新压缩级别 1 文件。
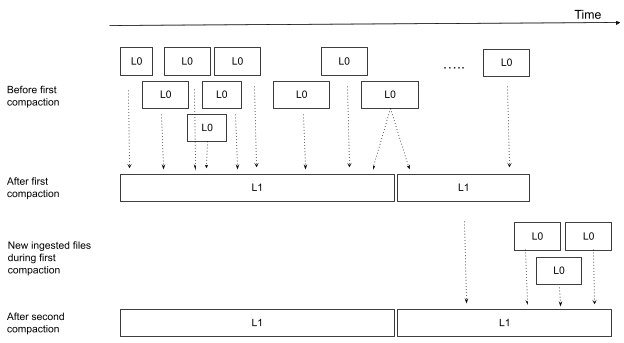
如果我们想添加不同的文件大小级别,则可以添加更多压缩级别(2、3、4 等)。请注意,虽然不同级别的文件可能重叠,但不应有任何文件与同一级别的其他文件重叠。
我们应该尽量避免去重,因为去重运算符很昂贵。当主键包含许多需要保持排序的列时,去重尤其昂贵。构建快速且内存高效的多列排序至关重要。一些常用的技术在此处 part 1 和 part 2 中描述。
数据查询
支持数据压缩的系统需要知道如何处理压缩和尚未压缩的数据的混合。图 4 说明了查询需要读取的三个文件。文件 1 和文件 2 是级别 1 文件。文件 3 是与文件 2 重叠的级别 0 文件。

图 5 说明了扫描这三个文件的查询计划。由于文件 2 和文件 3 重叠,因此它们需要通过“去重和合并”运算符。文件 1 不与任何文件重叠,仅需要与去重的输出联合。然后,所有联合的数据将通过查询计划必须处理的常用运算符。正如我们所看到的,在查询前处理期间压缩和生成更多非重叠文件,查询必须执行的去重工作就越少。
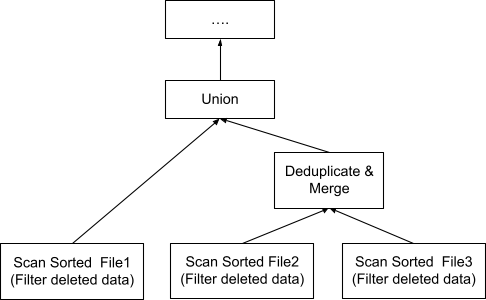
隔离和隐藏的 Compactor
由于数据压缩仅包括摄取后和查询前后台任务,因此我们可以使用完全隐藏和隔离的服务器(称为 Compactor)来执行它们。更具体地说,可以使用三组各自的服务器来处理数据摄取、查询和压缩:integer、querier 和 compactor,它们根本不共享资源。它们只需要连接到相同的目录和存储(通常是基于云的对象存储),并遵循相同的协议来读取、写入和组织数据。
由于 Compactor 不与其他数据库服务器共享资源,因此可以实现它来并发处理许多表(甚至表的许多分区)。此外,如果有许多表和数据文件要压缩,则可以配置多个 Compactor 以独立并行压缩这些不同的表或分区。
此外,如果压缩操作所需的资源远少于数据摄取或查询,那么分离服务器将提高系统效率。也就是说,系统可以利用多个数据摄取器和查询器分别并行处理大量数据摄取工作负载和查询,而只需要一个压缩器来处理所有后台的摄取后和查询前的工作。 同样地,如果压缩需要更多资源,则可以配置由多个压缩器、一个数据摄取器和一个查询器组成的系统来满足需求。
数据库中一个众所周知的挑战是如何管理服务器(数据摄取器、查询器和压缩器)的资源,以最大程度地利用资源(CPU 和内存),同时避免发生内存溢出事件。 这是一个很大的主题,值得单独写一篇博客文章。
压缩是一项关键的后台任务,它可以实现低延迟的数据摄取和高性能的查询。 共享的、基于云的对象存储的使用使得数据库系统能够利用多个服务器来独立处理数据摄取、查询和压缩工作负载。 有关此类系统实现的更多信息,请查看 InfluxDB IOx。 设计系统所需的其他相关技术可以在我们关于分片和分区的配套文章中找到。
