构建一个简单的、纯 Rust、异步的 Apache Kafka 客户端
作者:Marco Neumann / 用例, 开发者
2022 年 3 月 17 日
导航至
本文最初发表于 The New Stack。
对于 InfluxDB IOx, InfluxDB 的未来核心,我们使用 Apache Kafka 对数据进行排序
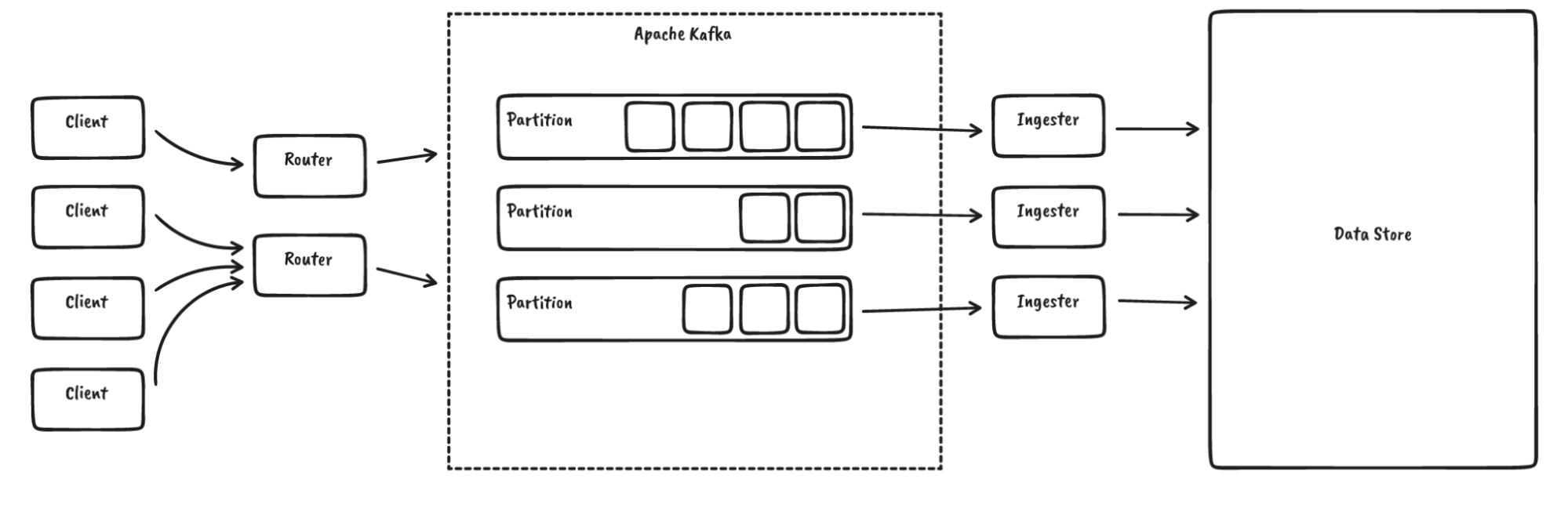
到目前为止,我们一直依赖于 rust-rdkafka,它为 librdkafka 提供了异步绑定,而 librdkafka 本身是用 C 语言编写的。那么我们为什么要替换它呢?以下是一些原因
- 复杂性: librdkafka 是一个复杂的库,具有我们不需要或不想要的大量功能,并且支持广泛的 Kafka 版本,而我们基本上只运行“最新版本”。由于 rust-rdkafka 也只公开了 librdkafka 功能的一小部分,我们认为这也可能适用于其他用户。
- 绑定: rust-rdkafka 试图将 librdkafka 硬塞进 Rust 异步生态系统中。这在某种程度上是可行的,但导致了一些问题,例如当从不同线程执行回调时,tokio 会感到困惑。绑定本身也存在一些限制。
- 缓冲/模块化: 我们对 librdkafka 中缓冲和批处理的工作方式控制有限。这是跨语言库固有的问题。
- 专业知识和洞察力: 错误和意外行为很难调试。我们对在生产中使用当前状态感到不安。
- 可行性: 我们只使用了 Kafka 功能的非常有限的子集(例如,没有事务),对于这个子集,Kafka 协议相当简单。对于这个子集,编写一个新的客户端实际上是可行的。
这就是为什么我们决定在 Rust 中启动一个简单、全新、完全异步的 Kafka 客户端: RSKafka。
这是一个快速使用示例。首先,我们设置一个客户端
let connection = "localhost:9093".to_owned();
let client = ClientBuilder::new(vec![connection]).build().await.unwrap();让我们创建一个主题
let topic = "my_topic";
let controller_client = client.controller_client().await.unwrap();
controller_client.create_topic(
topic,
2, // partitions
1, // replication factor
5_000, // timeout (ms)
).await.unwrap();然后我们生产和消费一些数据
// get a client for writing to a partition
let partition_client = client
.partition_client(
topic.to_owned(),
0, // partition
)
.await
.unwrap();
// produce some data
let record = Record {
key: b"".to_vec(),
value: b"hello kafka".to_vec(),
headers: BTreeMap::from([
("foo".to_owned(), b"bar".to_vec()),
]),
timestamp: OffsetDateTime::now_utc(),
};
partition_client.produce(vec![record]).await.unwrap();
// consume data
let (records, high_watermark) = partition_client
.fetch_records(
0, // offset
1..1_000_000, // min..max bytes
1_000, // max wait time
)
.await
.unwrap();您可能想直接跳转到 源代码,但我也邀请您继续阅读,了解我们是如何构建它的,以及哪些实践可以普遍适用于客户端库。
Kafka 协议
在为协议编写新客户端时,第一个问题是:它有多复杂?这个问题应该(希望)由协议规范来解答。在 Kafka 的情况下,有一些文档,但没有一个完全涵盖整个协议
- Kafka 协议指南:概述了协议的工作原理,并详细描述了消息布局,但没有描述消息语义。
- Kafka 文档:提供了记录批次(例如实际有效负载)如何序列化的详细信息。
- Kafka 改进提案:这些是对协议为何以及如何演变的深入解释。有 800 多个提案,导航它们有点棘手。还要注意,在少数情况下,它们与实际实现略有不同步。
- librdkafka:查看其他实现的源代码可能会有所帮助。
- Wireshark:尤其是在追查错误或试图理解其他实现的作用时,只需查看发送和接收的包可能会有所帮助。幸运的是,Wireshark 带有原生 Kafka 协议支持。
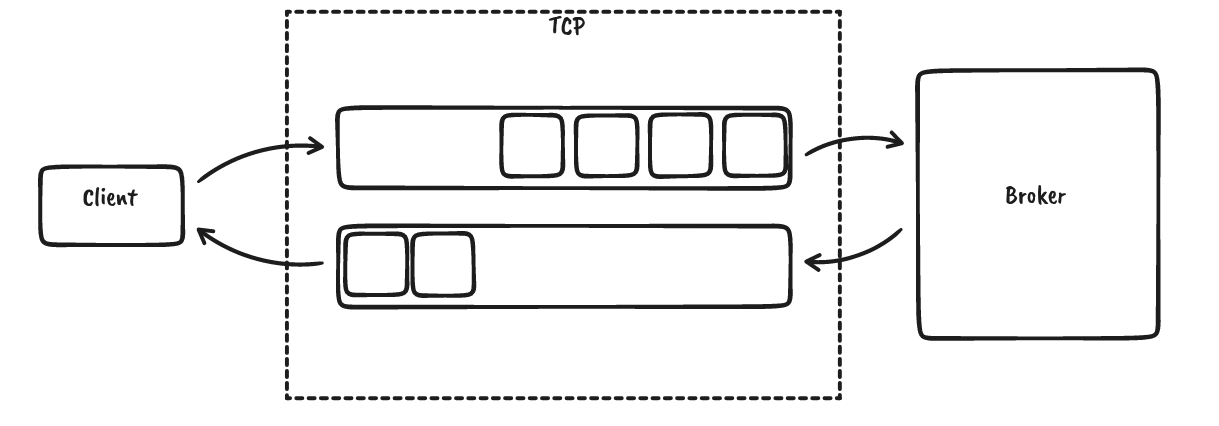
Kafka 每个客户端/broker 连接使用单个 TCP 连接。这很好,因为我们可以依靠操作系统为我们提供消息排序、反压、连接级重试和某种形式的错误处理。然后,数据使用 32 位有符号整数大小进行帧化,后跟有效负载
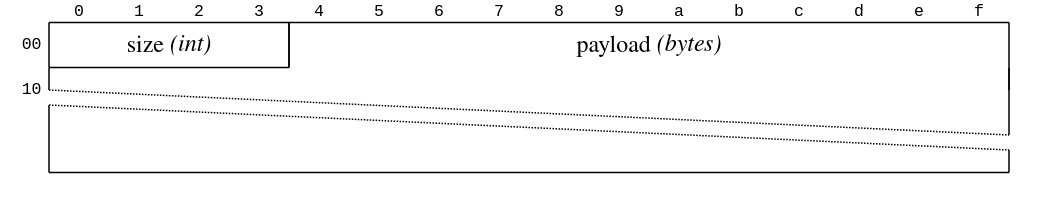
网络工程师可能会想,“哪种类型的 32 位整数?” 实际上,Kafka 在 协议文档的专用部分 中声明了其协议原语,用于这种特定类型
“表示介于 -231 和 231-1 之间的整数。值使用网络字节顺序(大端)的四个字节进行编码。”(隐含地假设有符号整数编码为二进制补码。)
有效负载本身是一个简单的请求-响应模型,带有标头和正文。这是请求
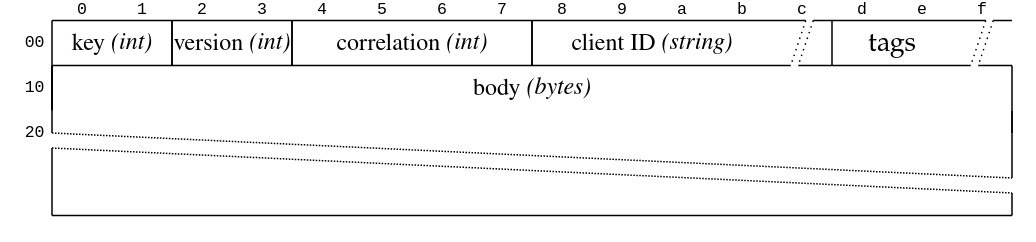
这是响应

请求从客户端发送到 broker,broker 只会发送其接收到的请求的响应。没有服务器发起的传输。关联 ID 将响应映射到请求。数据可以流水线传输;例如,即使我们正在等待响应,我们也可以发送更多请求,但服务器不会进行消息重新排序,即使关联 ID 允许这样做
上面显示的请求标头中的其他重要字段是 API 密钥和版本。(客户端 ID 只是一个字符串,标签是一种扩展机制。)版本特定于 API 密钥,并使用名为 ApiVersion 的特殊消息进行协商,该消息指示 broker 支持的版本范围(每个 API 密钥一个)。然后,客户端从这些范围中选择它支持的最高版本。对于新版本,字段会被添加和删除,数据类型会被更改,但某些字段的语义也可能发生变化。这与其他协议(如 protocol buffers)有点不同。RSKafka 试图成为一个好公民,并支持这种协商形式,即使它没有实现所有已知的版本。相反,我们只为我们所需的功能实现了一组足够的版本。
虽然实现一个新协议看起来工作量很大,但一般来说,您几乎总是可以使用一些工具来实现协议客户端——支持以大端和小端编码读取和写入整数的标准库,用于特定任务的辅助库(如 CRC 计算),解析器框架(如 nom (RSKafka 未使用)),传输相关的 crates(如 rustls)等等。
测试
协议实现的测试可以而且应该在多个层面上进行。让我带您了解一下。
序列化往返
当序列化和反序列化数据类型(例如前面提到的原始类型)时,检查是否可以成功存储和读取许多不同的值会很有帮助。一种快速便捷的方法是 proptest
proptest! {
#[test]
fn roundtrip_in16(orig: Int16) {
let mut data = vec[]!;
orig.write(&mut data).unwrap();
let restored = Int16::read(&mut Cursor::new(data)).unwrap();
assert_eq!(orig, restored);
}
}序列化快照
虽然往返测试确保我们可以读取我们写入的数据,但它不能确保任何规范合规性。例如,我们可能误读了协议定义并使用了完全错误的序列化格式。二进制快照是我们知道是对特定数据结构进行编码的字节序列。这些可以从协议规范中获取(如果列在那里),或者通过观察其他客户端的行为来获取,例如使用 Wireshark
当规范不清楚或令人困惑时,快照也可以帮助您理解协议。(或者,如果没有规范可用,在这种情况下,我们谈论的是 逆向工程。)我们在几个地方使用这些快照,反序列化数据,对照真实情况检查结果结构,然后进行额外的往返测试,以确保我们也写入了正确的字节序列。
集成测试
在开发新的协议客户端时,尽早进行某种形式的集成测试以仔细检查是否正确理解了协议文档是有意义的。我们针对 Apache Kafka 以及 Redpanda 执行了一系列操作,例如创建分区以及生产和消费数据;两者都相当容易地集成到我们的 CircleCI 管道中。我们还使用 rdkafka 生产和消费消息,以交叉检查其他客户端是否可以使用 RSKafka 生成的有效负载。幸运的是,这两种服务器实现都相当挑剔,并拒绝任何乱码。Apache Kafka 甚至在服务器控制台上打印出有用的回溯信息。请注意,并非每个协议都是这种情况。
单元测试
集成测试很少会触发客户端需要处理的所有边缘情况。为此,并为了加快测试速度,重要的是也要在没有任何外部依赖项的情况下测试客户端的各个部分。我们正在通过抽象客户端的一些内部部分来改进该领域的测试覆盖率,以便可以针对模拟甚至作为独立的函数进行测试。
模糊测试
对于每个新的协议解析器,强烈建议实现某种形式的模糊测试。即使您可能不希望您的 Kafka 集群攻击您,但来自网络的乱码字节或对协议的误解仍然可能导致意外的 panic。令人惊叹的 cargo-fuzz 使模糊测试变得非常简单
fuzz_target!(|data: &[u8]| {
RecordBatchBody::read(&mut Cursor::new(data)).ok();
});专注于没有太多长度标记或 CRC(循环冗余校验)字段的数据结构很有帮助,因为模糊器很难通过这些检查。您可能想知道没有不安全代码的解析器如何 panic?我们发现并修复了两件事
- 内存不足 (OOM): 某些数据类型被序列化为长度标记,后跟实际有效负载。当读取长度然后预分配缓冲区而不考虑分配了多少数据或还剩多少数据要读取时,您很容易耗尽内存。对于 Rust 来说,这将中止进程,从而导致整个服务器崩溃。
- 溢出: 某些整数类型在反序列化时需要位移。粗心大意地这样做可能会导致溢出。请注意,在发布模式下编译时,通常不会检查这些溢出。
模块化
我们的目标之一是让用户选择他们希望如何管理消费期间的预取或写入 Kafka 时的批处理。为了使用最大大小和linger 时间(如下所示)在批次中累积记录,只需要
// construct batch producer
let producer = BatchProducerBuilder::new(partition_client)
.with_linger(Duration::from_secs(2))
.build(RecordAggregator::new(
1024, // maximum bytes
));
// produce data (from multiple threads / places)
let offset: i64 = producer.produce(record).await.unwrap();在设计批处理机制时,我们想到的另一个用例是自定义聚合算法。例如,如果不是由 RSKafka 将多个记录合并到一个批次中,而是用户可以提供自己的聚合器,会怎么样?这在 IOx 中很有用。在那里,我们可以重用字符串字典而不是在每个记录中对其进行编码,从而提高性能并减少大小消耗。我们通过 traits 提供了一个很好的扩展点来实现这一点
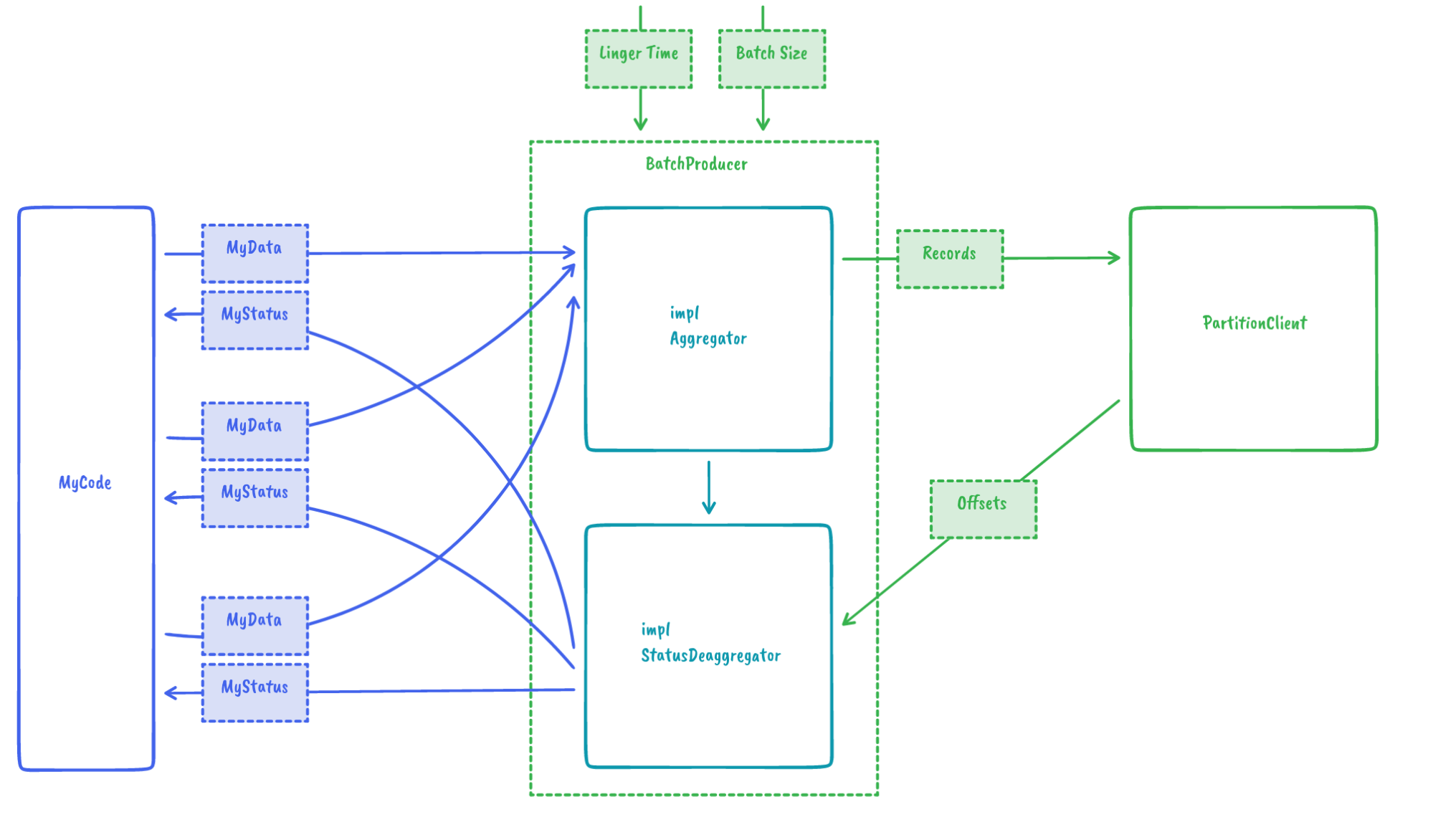
然后,这将导致以下简单的用户代码
// construct batch producer
let producer = BatchProducerBuilder::new(partition_client)
.with_linger(Duration::from_secs(2))
.build(MyAggrgator::new(...));
// produce data (from multiple threads / places)
let status: MyStatus = producer.produce(my_data).await.unwrap();贡献
目前,RSKafka 特意保持 минималистичный – 它不支持任何形式的事务处理。虽然我们没有任何大规模扩展自身功能的计划,但我们愿意接受社区贡献,并期待有趣的用例。在 https://github.com/influxdata/rskafka 与您相见。
