借助 ctrlX CORE 和 InfluxDB 构建下一代智能 PLC
作者:Jay Clifford / 开发者
2024 年 2 月 28 日
导航至
本文最初发表于 IIoT World,并在此获得许可转载。
自 20 世纪 60 年代最初创建以来,可编程逻辑控制器 (PLC) 在工业自动化中发挥了不可或缺的作用。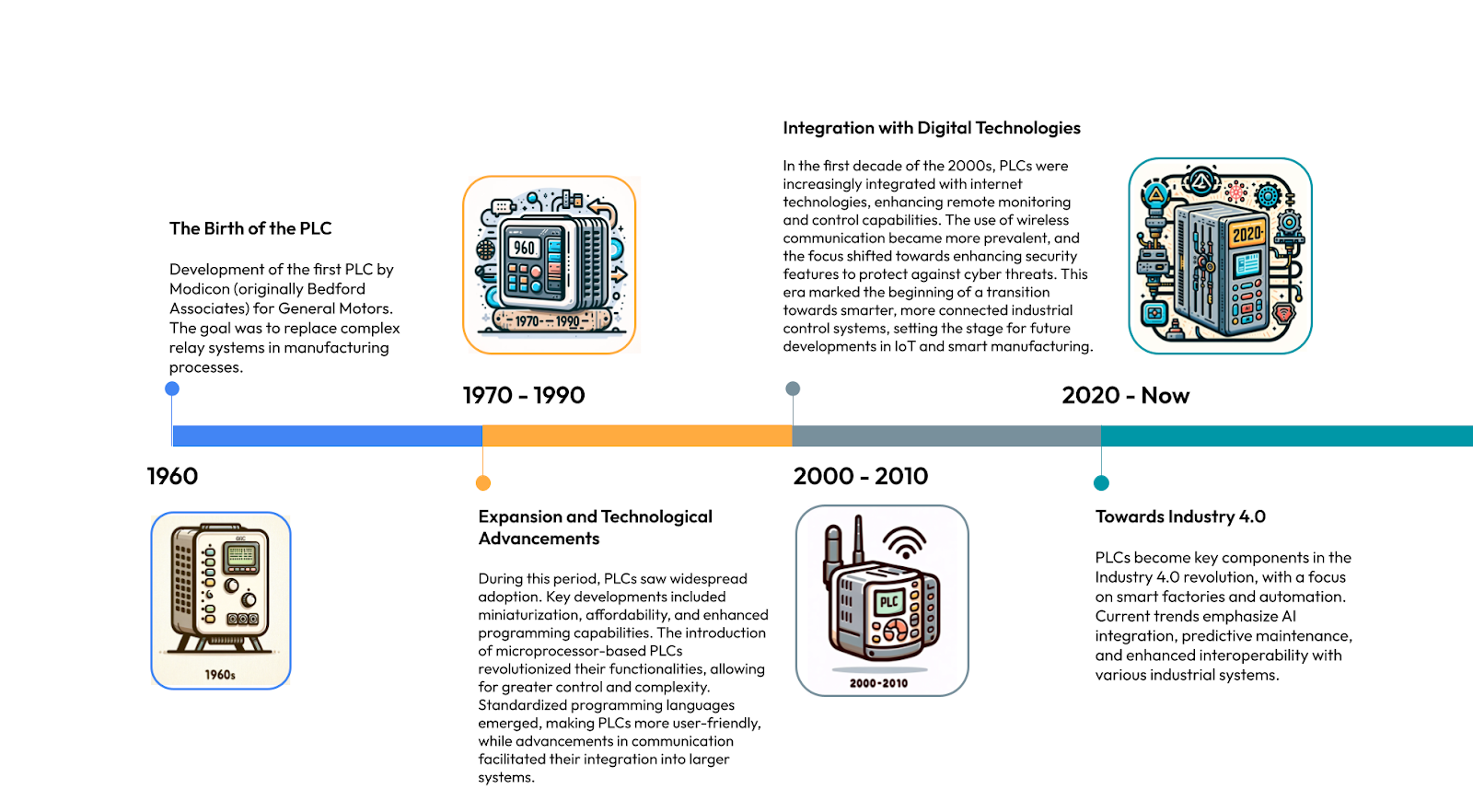 从那时起,我们看到了 PLC 的形式和功能在多年中的逐步改进。问题是?虽然 PLC 在管理和控制工业流程方面非常出色,但现代制造业不断发展的需求要求这些设备不仅仅是控制机器。制造商现在寻求利用 PLC 的计算能力来执行更复杂的任务,尤其是在监控机器的健康状况和状态方面。对更高效率、预测性维护 和实时数据分析的需求推动了这种转变。那么,这是否意味着我们需要重新审视组织如何设计和使用 PLC?
从那时起,我们看到了 PLC 的形式和功能在多年中的逐步改进。问题是?虽然 PLC 在管理和控制工业流程方面非常出色,但现代制造业不断发展的需求要求这些设备不仅仅是控制机器。制造商现在寻求利用 PLC 的计算能力来执行更复杂的任务,尤其是在监控机器的健康状况和状态方面。对更高效率、预测性维护 和实时数据分析的需求推动了这种转变。那么,这是否意味着我们需要重新审视组织如何设计和使用 PLC?
在本博客中,我们将探讨下一代 PLC,即 Rexroth 的 ctrlX core,以及我们如何利用该平台集成一流的开源项目,例如 InfluxDB 和 Grafana,以创建现代的互联异常检测堆栈。
PLC 到底是什么?
在我们深入了解之前,让我们先分解一下标准 PLC 的架构和作用。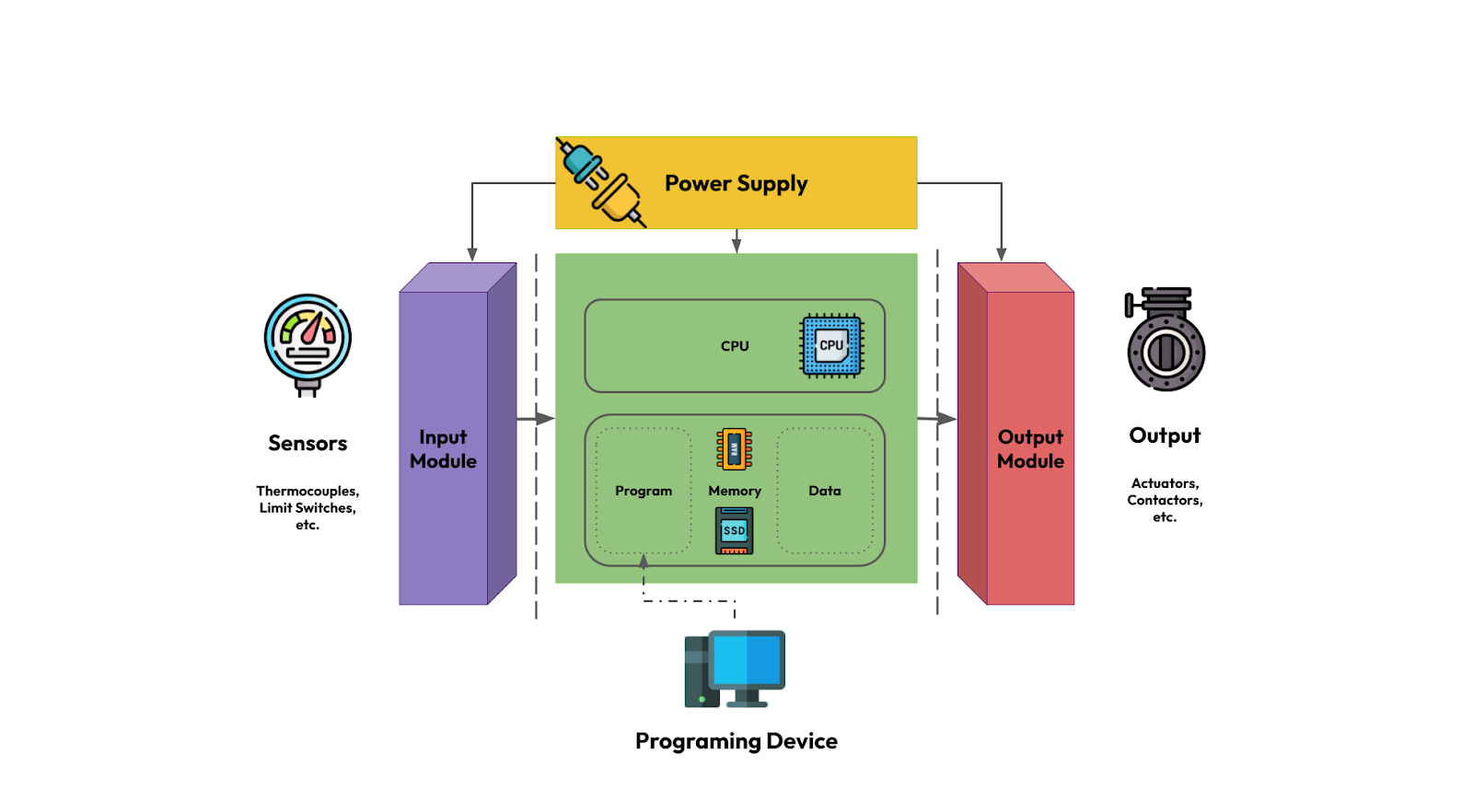 上图分解了 PLC 的核心组件
上图分解了 PLC 的核心组件
- 输入模块:接收来自传感器、开关和按钮等输入设备的信号,并将这些信号转换为 PLC CPU 可以处理的格式。
- 输出模块: 将来自 PLC 的控制信号发送到电机、阀门、灯和继电器等输出设备。
- 电源: 将主交流电(交流电流)转换为低压直流电(直流电流),为 PLC 组件供电。
- CPU(中央处理单元): 处理程序数据和指令,根据编程逻辑执行控制操作。它处理逻辑运算、算术运算、排序、定时、计数和数据操作。
- 内存: 用于存储用户加载的控制程序。这通常包括易失性和非易失性内存类型。易失性内存(如 RAM)在操作期间临时存储数据。非易失性内存(如 ROM、EEPROM)存储 PLC 程序,即使断电也能保留。
- 编程设备: 用于将所需的程序输入到 PLC 的内存中。
我认为分解 PLC 的架构有助于消除其设计背后的歧义。从最简单的形式来看,它是一台坚固的计算机,可以重复执行程序。
为了巩固这个想法,让我们看一个场景来说明 PLC 的功能: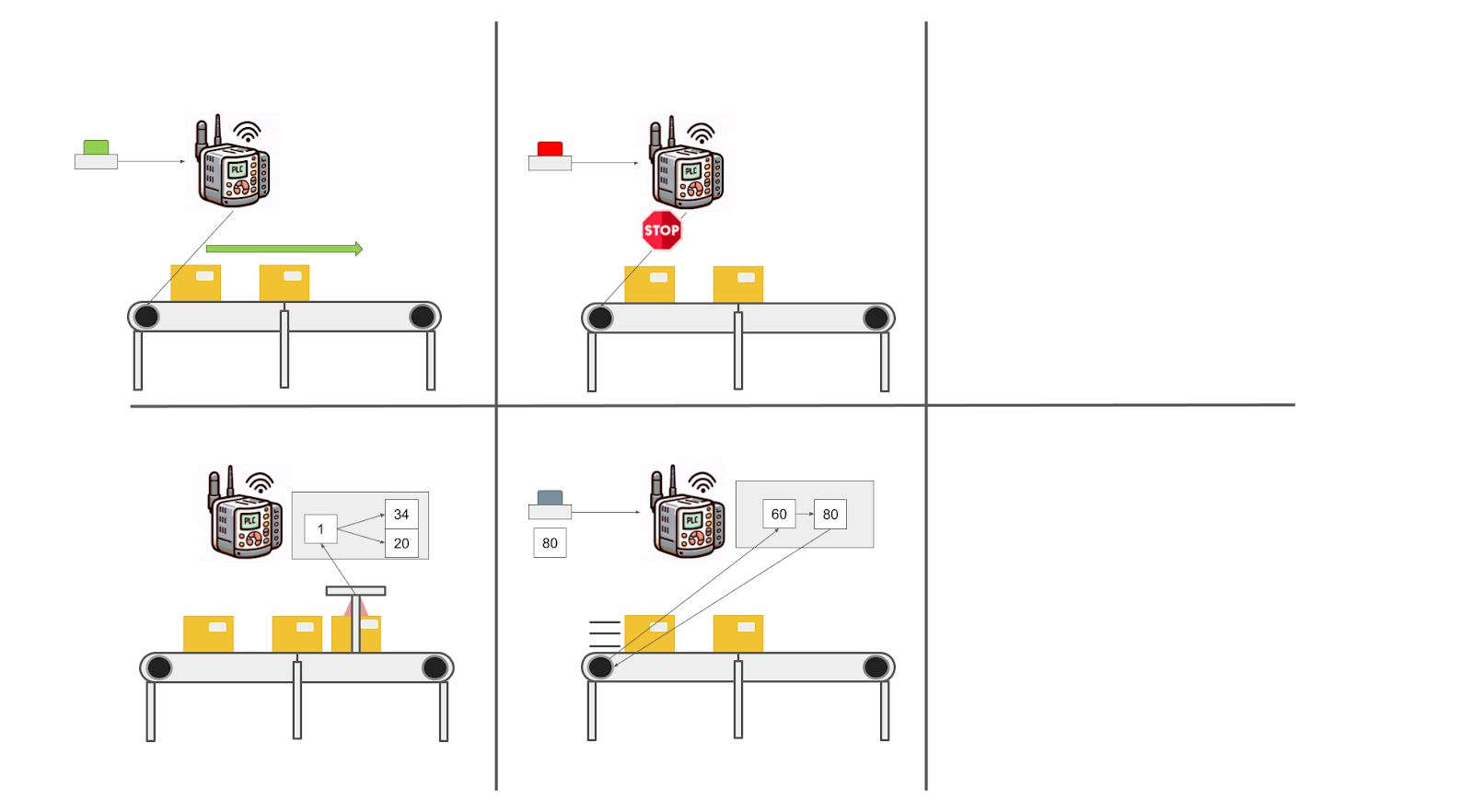 在上面的场景中,PLC 自动化了传送带的运动
在上面的场景中,PLC 自动化了传送带的运动
- 启动/停止控制
- 按下启动按钮会向电机控制继电器发送信号,从而激活传送带。
- 按下停止按钮或激活紧急停止会立即发送信号以停用电机控制继电器,从而停止传送带。
- 物体检测和处理
- 光电传感器检测传送带上的物体。
- PLC 可以计数物体、控制它们的间距,并停止传送带以进行特定操作,例如检查或包装。
- 速度控制和监控
- 速度传感器向 PLC 提供反馈。
- PLC 调整电机速度以保持恒定的传送带速度,这对于与其他机器同步操作至关重要。
- PLC 还可以响应用户进行的手动速度调整。
在基本了解 PLC 的工作原理之后,下一代 PLC(如 ctrlX core)如何在设计上进行迭代?InfluxDB 又如何融入这一切?
下一代 PLC
正如我们现在所知,大多数标准 PLC 都有一个嵌入式处理器来执行设计的程序。通常,这意味着 PLC 会附带自己的专有操作系统(例如,西门子 S7 PLC 的 SIMATIC Step 7 和罗克韦尔 Allen-Bradley PLC 的 RSLogix)以在嵌入式处理器上运行。这非常适合提供容错且高性能的执行引擎,但几乎没有扩展空间。
另一方面,ctrlX core 提供了灵活的硬件规范,允许制造商根据某些任务的需求控制其 PLC 的功率水平。PLC 还部署了一个名为 Ubuntu IoT Core 的 Linux 操作系统,从而可以灵活地扩展核心功能和用户可以在 PLC 上安装的服务。让我们重新审视原始 PLC 架构并对其进行修改以反映 ctrlX core 的设计: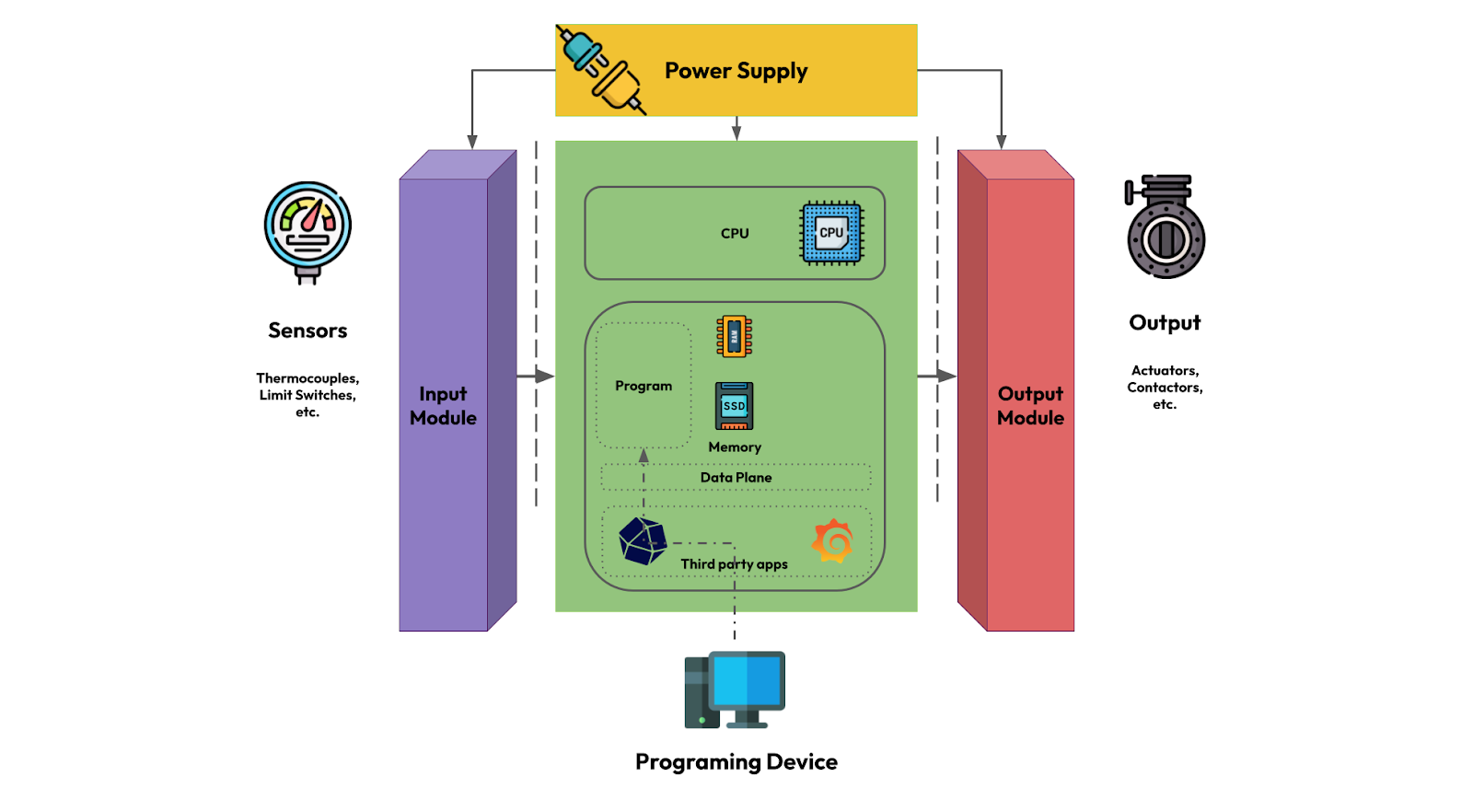 我们在 PLC 设计中引入了两个新方面
我们在 PLC 设计中引入了两个新方面
- 数据平面: 这取代了内存中的标准操作数据。它仍然为我们的 PLC 程序提供了一种访问输入和输出数据的方式,以及允许第三方应用程序订阅和发布数据的网关。
- 第三方应用程序: 因为我们的 PLC 现在使用 Linux 发行版,所以我们可以利用内置的 Linux 服务,例如容器化。这允许开发人员在 ctrlX core 上构建和部署 dockerized 应用程序,以与数据平面进行交互。
InfluxDB 和 Grafana 在这一切中扮演什么角色?我们如何利用这些新服务和 ctrlX core 的额外计算能力?
开源数据 Historian
InfluxDB 是一个开源时间序列数据库,专门从头开始设计,用于处理海量时间序列数据。近年来,它已成为许多下一代数据 Historian 的基础,这些 Historian 正在取代标准关系数据库。我们可以将这种转变归因于 InfluxDB 的几个独特品质
- 高吞吐量数据摄取: InfluxDB 有效地管理来自多个并行数据源的数据摄取,使其成为具有广泛数据生成环境的理想选择。
- 写入时模式灵活性: 它提供了一种“写入时模式”方法,允许灵活快速地存储数千个机器标签,而无需预先设计的模式。这使其能够适应不同的数据结构。
- 低系统要求: InfluxDB 安装和操作需求极低,是本地数据存储的有效解决方案,为其他关键 PLC 流程节省硬件资源。
- 高级基于时间的查询: 执行高效的基于时间的聚合(如平均值、总和、最小值、最大值),跨越各种时间粒度(秒、分钟、小时、天等)。
- 高分辨率时间戳: 高度精细的时间戳(精度高达纳秒)使其适用于在详细级别进行精确的机器监控。
用户可以直接通过 ctrlX core 的第三方应用商店将 InfluxDB 安装到 ctrlX core 上。这将自动安装最新的开源实例。那么,这为我的现场工程师带来了哪些好处?让我们重新审视我们的传送带示例。
机器异常检测
在本示例中,我们部署了 ctrlX core 来控制我们的传送带。与之前一样,PLC 程序包括以下功能:
- 停止/启动控制
- 物体检测和处理
- 速度控制和监控
最重要的是,我们还将部署 InfluxDB 以充当本地边缘数据 Historian。InfluxDB 将连接到 ctrlX core 数据平面,并从传送带 伺服电机 中摄取以下健康指标
- 振动
- 速度
- 温度
在下图所示的示例中,我们可以看到在标准操作期间,系统将这些传感器指标存储在 InfluxDB 中。Grafana 直接连接到 InfluxDB,以在 HMI 上直接向用户显示这些原始指标读数: 这是行业内的标准做法。但是,使用 InfluxDB OSS(开源软件)内置的任务引擎,我们可以对历史和当前遥测数据执行自动化分析,以查找趋势。在此 InfluxDB 任务中,我们将历史读数与当前指标进行比较,以了解温度和振动都在上升。我们使用此数据通过 Grafana 发送警报,以向现场工程师指示我们当前的遥测读数表明其中一台电机承受着越来越大的压力,可能需要维修。
这是行业内的标准做法。但是,使用 InfluxDB OSS(开源软件)内置的任务引擎,我们可以对历史和当前遥测数据执行自动化分析,以查找趋势。在此 InfluxDB 任务中,我们将历史读数与当前指标进行比较,以了解温度和振动都在上升。我们使用此数据通过 Grafana 发送警报,以向现场工程师指示我们当前的遥测读数表明其中一台电机承受着越来越大的压力,可能需要维修。
此场景提供了一种基本方法,让 InfluxDB 和 Grafana 将预测性维护和异常检测直接引入 PLC。这种方法的好处是在识别和警报潜在故障时延迟更低,因为这些过程更接近数据源发生。我们还利用 PLC 的硬件功能,而不是引入另一个边缘设备来执行此分析。
边缘数据复制
最后,作为额外的补充,InfluxDB OSS 具有内置功能,可以将数据从一个 InfluxDB 实例写入到另一个远程 InfluxDB 实例。这可以是 InfluxDB Serverless、Dedicated、Clustered(本地部署),甚至另一个远程 InfluxDB OSS 实例。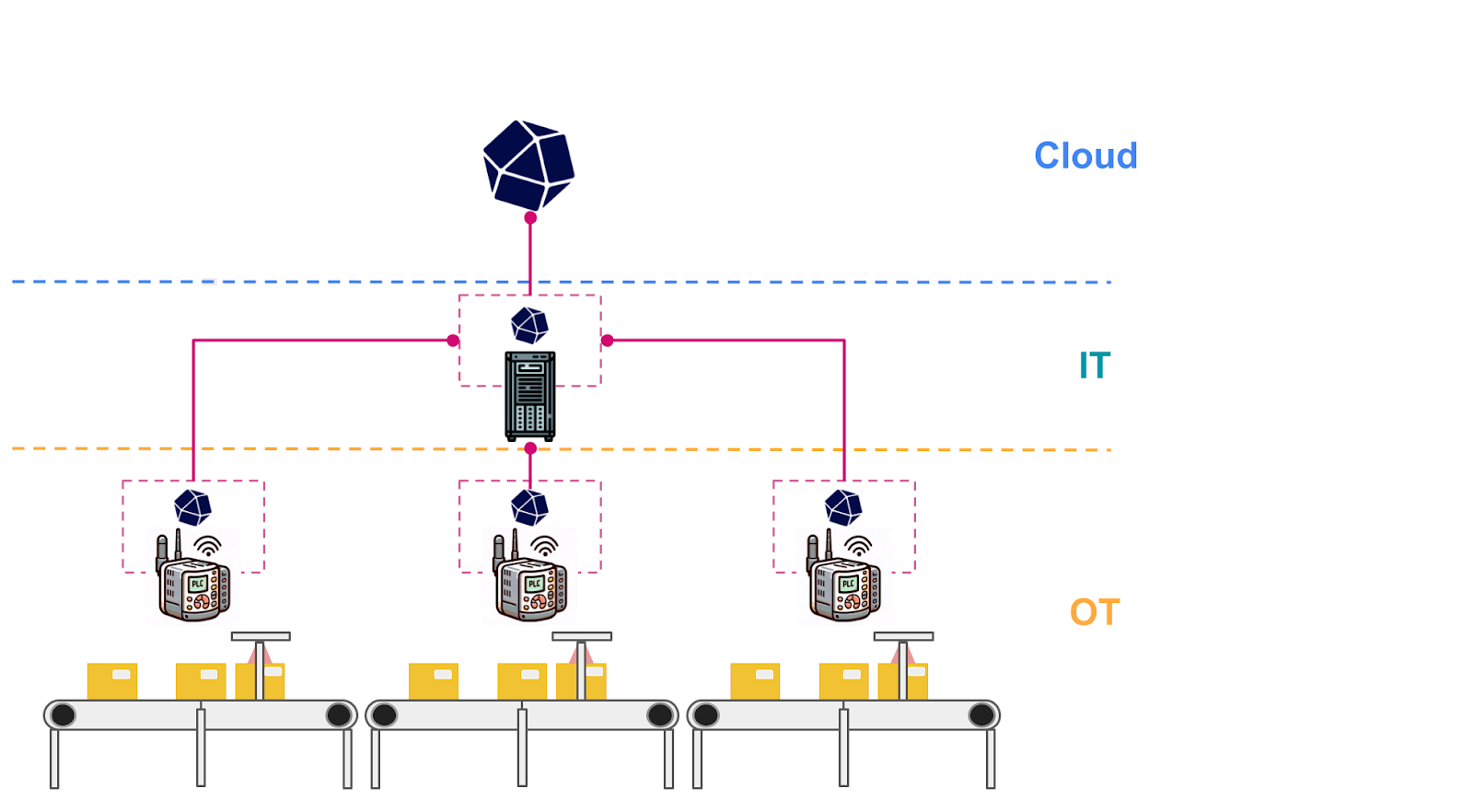 此功能允许您将来自不同生产线的数据聚合到单个聚合存储库中,以进行进一步分析。一些优势包括
此功能允许您将来自不同生产线的数据聚合到单个聚合存储库中,以进行进一步分析。一些优势包括
- 相同类型的生产线之间的异常检测——发现一条生产线是否开始偏离其他生产线。
- 更高的组织可见性。例如,如果您的数据科学家之一需要真实的机器数据来训练 ML 模型,则此功能提供了一种非侵入式的方式来卸载必要的数据。
- 固有的安全性。InfluxDB 充当 OT 和基于 IT 的网络之间的数据写入器和接收器——数据移动仅单向发生。
结论
工业 4.0 的发展正在迫使许多制造商创造性地思考如何从车间的 PLC 中提取、存储和分析数据。对于许多较旧的系统,这种做法不会改变(在这些情况下,将 PTC Kepware 和 InfluxDB 结合使用将适用于大多数 PLC)。但是,我希望这篇博客在您考虑将新机器引入生产线时对您有所帮助。像 ctrlX core 这样的下一代 PLC 从头开始构建,以适应作为强大的机器控制器和强大的边缘计算设备执行任务的灵活性和适应性。将此与 InfluxDB 和 Grafana 等开源项目配对,您将能够开发一种经济高效的解决方案,用于自动化机器的健康分析。
要了解配置 InfluxDB 有多容易,我强烈建议您查看此 交互式演示。 我还建议 Rexroth 提供的关于 如何在 ctrlX core 上安装和配置 InfluxDB 的演练。如果您对本博客或 InfluxDB 有任何疑问,我强烈建议您加入 InfluxDB 社区。
