构建更好的 Telegraf 插件(仍然是面向初学者)
作者:David G. Simmons / 产品, 用例, 开发者
2017 年 9 月 30 日
导航至
似乎就在昨天,我还在写一篇关于 如何为初学者构建 Telegraf 插件 的博客。等等,那**确实**就是昨天!然而,我又回来写另一篇了。如果您阅读了昨天的帖子,并一直读到结尾,您会记得我说过
最终,我希望稍微扩展和概括它,使其不那么特定于 *我* 的需求——让它解析发送给它的读数,并根据 JSON 中的其他字段将它们放入数据库
我刚点击“发布”那篇文章,就决定“为什么不直接做呢?” 所以我就做了。而且我做得比我想象的还要好!我之前只用那个插件发布一个值,这真的没什么用。实际上,我的小传感器 发布 6 个值,因此发布 6 条不同的消息,每条消息对应一个值,效率会非常低,而且资源消耗也太大了。我必须在设备、Particle Cloud 和插件上进行更改,才能使其全部工作,所以我将带您了解所有这些更改。
在 Particle 设备和 Cloud 上
以前,使用行协议,我一次发布所有读数和标签,所以我认为我也要为这个插件重新利用它。为了刷新,这是我之前发布的方式
request.body = String::format("influxdata_sensors,id=%s,location=%s temp_c=%f,temp_f=%f,humidity=%f,pressure=%f,altitude=%f,broadband=%d,infrared=%d,lux=%f", myID.c_str(), myName.c_str(), temperature, fTemp, humidity, pressure, altitude, broadband, infrared, lux);
http.post(request, response, headers);所有标签、字段和值都整齐地在一个 HTTP POST 中。事实证明,从设备角度来看,我所要做的就是重新格式化字符串,以便从中构建一个合适的 JSON,然后将其发布到 Particle 云
String data = String::format("{ \"tags\" : {\"id\": \"%s\", \"location\": \"%s\"}, \"values\": {\"temp_c\": %f, \"temp_f\": %f, \"humidity\": %f, \"pressure\": %f, \"altitude\": %f, \"broadband\": %d, \"infrared\": %d, \"lux\": %d}}", myID.c_str(), myName.c_str(), temperature, fTemp, humidity, pressure, altitude, broadband, infrared, lux);
Particle.publish("sensor", data, PRIVATE);这将发布一个 JSON 字符串,在 Particle 云处理完后,看起来像这样
{"data":"{ "tags" : { "id": "2b123b123123123123123123", "location": "MyLocation" }, "values": { "temp_c": 23.459999, "temp_f": 74.227998, "humidity": 45.628906, "pressure": 1017.543274, "altitude": -35.683643, "broadband": 34, "infrared": 19, "lux": 0 } }", "ttl":60, "published_at":"2017-09-30T17:00:27.832Z", "coreid":"2b003b001047343438323536", "userid":"XXXX", "version":11, "public":false, "productID":5343, "name":"sensor", "influx_db":"influxdata_sensors" }最后一个字段是我在 Particle.io 集成页面中使用自定义 JSON 添加的,如下所示
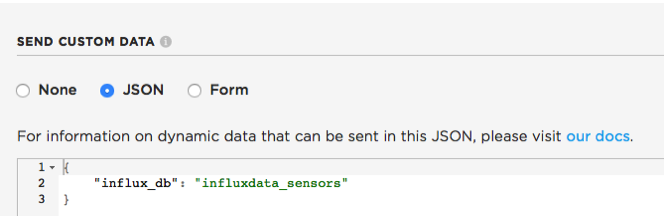
当我们讲到插件细节部分时,您就会明白为什么了。
整个过程中最好的部分是,我将设备上的代码大小减少了约 80%,因为我不再在每次循环中创建和拆除自己的 http 通信通道。使用内置调用 Particle Cloud 会更有效率。
在插件端
现在我已经让设备一次性将所有读数发送到 Particle Cloud,并且我已经设置了 Particle 集成,我必须修复 Telegraf 插件以处理所有这些新数据——以及它即将接收的更复杂的 JSON。这远没有我想象的那么难。我要做的第一件事是,由于新的 JSON 具有多个级别,因此创建一个“虚拟”结构,我可以将传入的 JSON 反序列化到其中。从那里,我会将**该**结构的一部分反序列化到一个新的结构中,该结构具有标签、字段和值。
type DummyData struct { Event string `json:"event"` Data string `json:"data"` Ttl int `json:"ttl"` PublishedAt string `json:"published_at"` InfluxDB string `json:"influx_db"` }我可以提取 ProductID、版本和其他字段,但我实际上对这些不感兴趣。我将所有传感器数据提取到“Data”元素中,然后我可以进入该元素并获取我需要的一切。请注意“InfluxDB”字段。这是我在 Particle Cloud 上定义 Webhook 时插入的字段,我将使用它将数据插入到我想要的 InfluxDB 数据库中。
type ParticleData struct { Event string `json:"event"` Tags map[string]string `json:"tags"` Fields map[string]interface{} `json:"values"` }我能够使用 map 作为标签和值,因为我已经将这些在 JSON 中正确设置为我希望它们作为什么插入到数据库中。这就是让它如此容易的原因。我想做的另一件事是,由于多个设备将通过此插件推送数据,因此使用提交的时间戳,而不是让插件为数据添加时间戳。为此,我需要将“PublishedAt”字段解析为正确的 InfluxDB 时间戳,如下所示
func (d *DummyData) Time() (time.Time, error) { return time.Parse("2006-01-02T15:04:05Z", d.PublishedAt) }所以这些是我创建的对象,这是我如何使用它们的
func (rb *ParticleWebhook) eventHandler(w http.ResponseWriter, r *http.Request) { defer r.Body.Close() data, err := ioutil.ReadAll(r.Body) if err != nil { w.WriteHeader(http.StatusBadRequest) return } dummy := &DummyData{} if err := json.Unmarshal(data, dummy); err != nil { w.WriteHeader(http.StatusBadRequest) return } pd := &ParticleData{} if err := json.Unmarshal([]byte(dummy.Data), pd); err != nil { w.WriteHeader(http.StatusBadRequest) return } pTime, err := dummy.Time() if err != nil { log.Printf("Time Conversion Error") } rb.acc.AddFields(dummy.InfluxDB, pd.Fields, pd.Tags, pTime) w.WriteHeader(http.StatusOK) }如您所见,我将传入的数据反序列化到 DummyData 结构中,然后将 DummyData 的 Data 字段反序列化到 ParticleData 结构中。我执行时间戳解析,然后将所有数据写入我选择的 InfluxDB 数据库。但这里真正酷的事情是,实际上是两个。我可以只发送标签和字段的 map,它们都会被正确分类,并且我可以在 Particle Cloud 级别选择要使用的数据库。在我的例子中,我能够无缝地将设备过渡到使用插件,而无需在我的数据库上移动数据。我还可以使用 Particle JSON 中的单个定义将其他 Particle 产品指向其他数据库。
我们完成了——几乎
我现在已经完成了我的插件,我可以非常轻松地将其用于几乎任何 Particle 项目。但我还*没有*完全完成,因为**您**还不能使用它!因此,我的待办事项清单上的最后一件事是完成此插件的单元测试,然后在 GitHub 上提交 Pull Request,以便将其包含在未来的版本中。如果有人想自己构建它,我会在过渡期间将其推送到 我的 GitHub。
