使用 InfluxDB Cloud、Python 和 Flask 构建 IoT 应用(第 3 部分)
作者:Rick Spencer / 产品, 用例, 开发者
2021 年 7 月 2 日
导航至
去年我启动了一个物联网项目,Plant Buddy。这个项目需要将一些传感器焊接到 Arduino 上,并教会该设备如何直接与 InfluxDB Cloud 通信,以便我可以监控这些植物。现在我正在将这个概念更进一步,为 plantbuddy.com 编写应用程序。这个应用程序将允许用户可视化并从他们上传的 Plant Buddy 设备数据中创建警报,以获得定制的用户体验。
如果您想要一些背景信息,您可以查看第 1 部分,我在其中设计了设备的基础知识,并教会它进行通信并添加一些通知,以及第 2 部分,我在其中开始了一些降采样和仪表板。(在第 4 部分中,Barbara Nelson 提供了本文的续篇,她在其中展示了如何使用 UI 而不是 CLI 来实现相同的功能。)
目标(基于 InfluxDB Cloud 构建)
本教程的编写非常注重应用程序开发者。我碰巧在本教程中使用了 Python 和 Flask,但所有概念都应同样适用于任何语言或 Web 开发框架。
本教程将涵盖
- 如何引导您的开发环境以开始在 InfluxDB Cloud 上进行开发
- 如何使用 InfluxDB Python 客户端库从您的用户接收数据,并将该数据写入 InfluxDB Cloud
- 如何查询 InfluxDB Cloud,以便您的应用程序可以为您的用户可视化数据。
- 如何在 InfluxDB 中安装降采样任务,这既可以节省您的存储成本,又可以优化用户的用户体验
- 如何使用 InfluxDB Cloud 强大的“检查和通知”系统来帮助您为用户提供自定义警报
本教程旨在关注 InfluxDB,而不是一般的 IoT 应用程序,因此我将不关注以下内容
- 创建您的设备并从中发送数据
- 您自己的 Web 应用程序的用户授权
- 在您自己的 Web 应用程序中管理密钥
- 如何为不同平台使用许多强大的可视化库
代码在哪里?
本教程的代码可在 GitHub 上找到。有两个分支
- 如果您只想查看起点,那在 demo-start 分支中。
- 如果您想查看已完成的项目,那在 demo-done 分支中。
plantbuddy.com 概览
数据分段策略
在我们开始引导开发环境之前,这里有一些关于是否以及如何分段您的用户数据的思考。本节相当概念化,因此您可以随意跳过它。
最有可能的是,您的应用程序将有许多用户。您通常只想向每个用户显示他们写入应用程序的数据。根据您的应用程序的规模和其他需求,有 3 种通用方法需要考虑。
- 单个多用户 Bucket。 这是默认方法。在这种方法中,您将所有用户的数据放入 InfluxDB 中的单个 bucket 中,并为每个用户使用不同的标签来启用快速查询。
- 每个用户一个 Bucket。 在这种方法中,您为每个用户创建一个单独的 bucket。这种方法在您的应用程序中更难管理,但允许您为用户提供读写令牌,以便他们可以在需要时直接从自己的 bucket 中读取和写入以用于您的应用程序。
- 多组织。 在这种方法中,您为每个用户创建一个单独的组织。这提供了客户数据的最终隔离,但设置和管理起来更复杂。当您充当某种 OEM 时,这种方法很有用,您的客户有自己的客户,并且您需要为您的客户提供管理工具。
| 方法 | 优点 | 缺点 | 总结 |
| 多用户 Bucket |
|
|
默认方法,使用标签在单个 bucket 中分段客户 |
| 每个用户一个 Bucket |
|
|
当分段客户数据很重要时很有用,但需要更多工作。允许直接读取和写入。 |
| 多组织 |
|
|
客户数据分段的最终方案。当您的客户有自己的客户时很有用。 |
由于 Plant Buddy 的相对简单和低敏感性性质,多用户 Bucket 的默认方法最有意义。Plant Buddy 具有相当简单的模式。但是,如果您有兴趣了解有关这些主题的更多信息,您可以在此处阅读有关数据布局和模式设计的更多信息。
IoT 应用程序和 InfluxDB Cloud 架构概述
从更宏观的角度来看,Plant Buddy 的工作方式大致如下
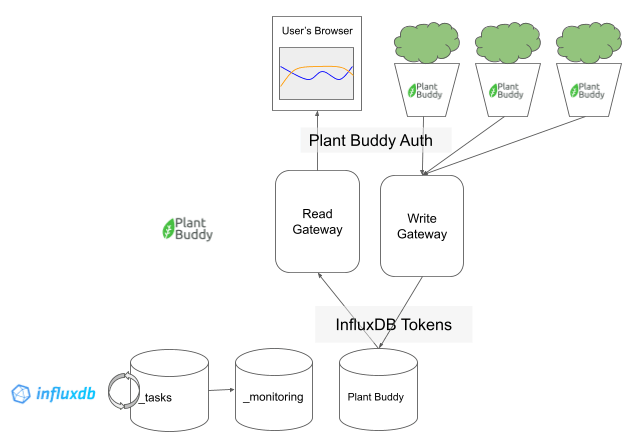
在顶层是用户体验。他们将能够在 Web 浏览器中查看传感器读数,并且每个用户可以有任意数量的 Plant Buddy 报告数据。
Plant Buddy 应用程序本身大致分为两部分:我称之为“写入网关”和“读取网关”。正如您将看到的,这些“网关”实际上只是 Plant Buddy Flask 应用程序中的端点,但它们可以很容易地划分为它们自己的应用程序。
用户与其设备之间读取和写入的用户身份验证由 Plant Buddy 本身处理。每个设备和每个浏览器请求都应由 Plant Buddy 授权。
最后是后端,即 InfluxDB。读取网关和写入网关写入同一个 bucket(首先,稍后在介绍降采样时会详细介绍)。我们还将利用 InfluxDB 的任务系统和提供的 _tasks 和 _monitoring 系统 buckets。
Plant Buddy 代码和 InfluxDB 后端之间的身份验证由 InfluxDB 令牌管理,这些令牌作为密钥存储在 Web 应用程序中。
Plant Buddy 启动器代码
首先,Plant Buddy 能够接收来自用户设备的信息,但只能解析发送的数据并将其打印出来。写入 InfluxDB 尚未实现。
@app.route("/write", methods = ['POST'])
def write():
user = users.authorize_and_get_user(request)
d = parse_line(request.data.decode("UTF-8"), user["user_name"])
print(d, flush=True)
return {'result': "OK"}, 200
def parse_line(line, user_name):
data = {"device" : line[:2],
"sensor_name" : sensor_names.get(line[2:4], "unknown"),
"value" : line[4:],
"user": user_name}
return data同样,有一个 html 模板集已设置好,其中包含一个用于渲染图表的插槽,但到目前为止仅打印从请求对象中提取的用户名。
@app.route("/")
def index():
user = users.authorize_and_get_user(request)
return render_template("home.html",
user_name = user["user_name"],
graph_code = "<i>put graph here</i>"您可以在 VSCode 中看到所有内容组合在一起
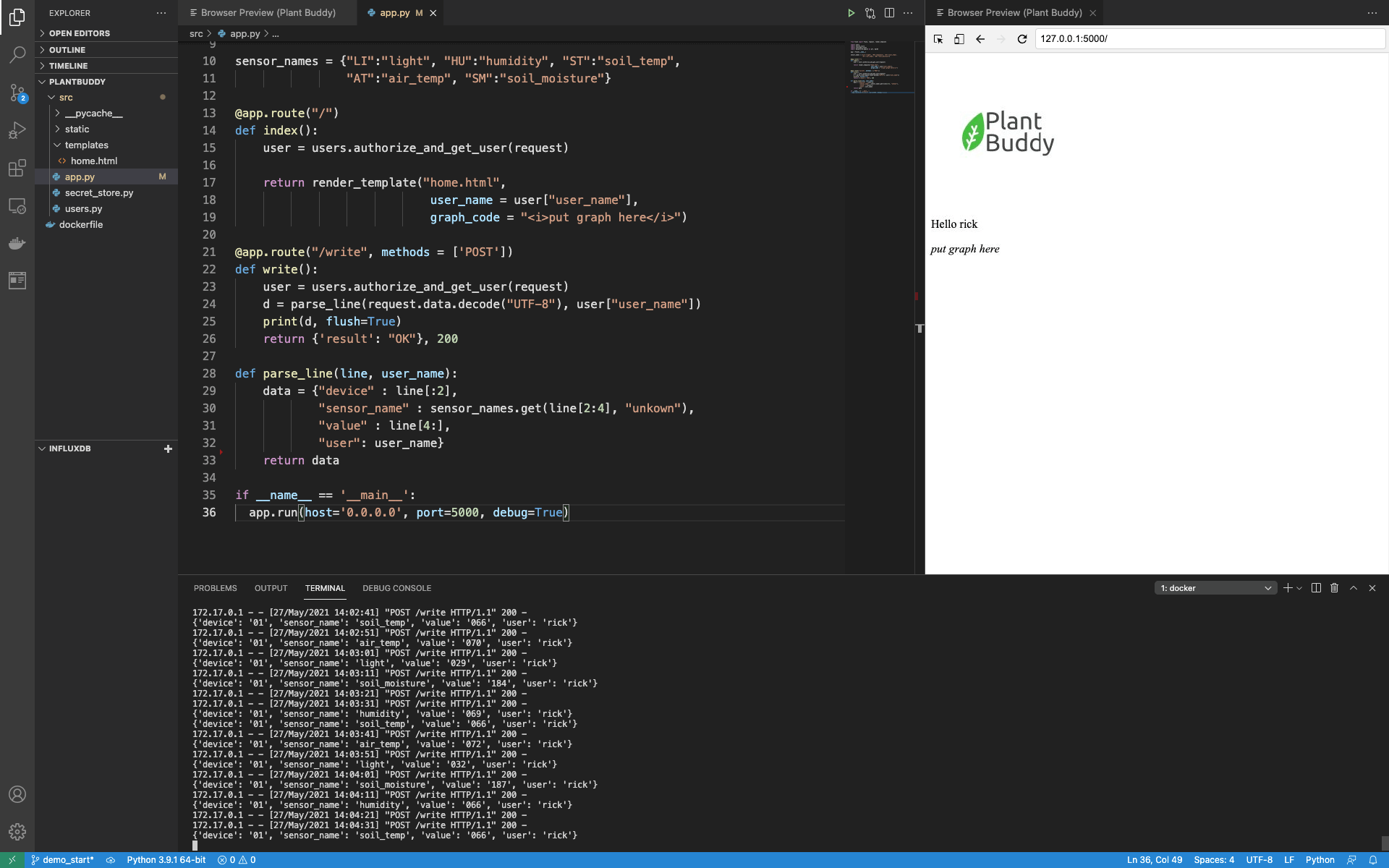
您可以在此处查看完整的启动器代码。本质上,Web 应用程序设置有
- 一个用于验证用户和提取用户名的用户模块(这是假的)。
- 一个密钥存储模块,用于安全地存储 InfluxDB 的密钥(也是假的)。
- 一个用于接受来自 Plant Buddy 设备数据的端点。
- Flask 服务器要渲染的 html 模板
- 一个用于渲染该 html 模板的端点
如您所见,我在本地主机上的 Docker 容器中运行该应用程序,以简化开发。
引导 InfluxDB Cloud 的 IoT 应用程序开发
现在我们已经完成了所有介绍性材料,是时候开始设置以使用 InfluxDB 了!
先决条件
- 设置一个 InfluxDB Cloud 账户。免费账户即可。
- 设置 VSCode。
- 下载并安装 Influx CLI。
设置 InfluxDB CLI
我有一个空的 Cloud 账户,并且我的开发笔记本电脑上安装了 CLI。可以直接使用 CLI,但我发现不断提供诸如我定位的区域、我的组织名称等信息很麻烦——因此,设置 CLI 的配置要容易得多。实际上,您可以设置多个配置并轻松地在它们之间切换,但目前,我只需要一个。
Influx CLI 有一个很好的帮助系统,所以我只是问如何创建一个
$ influx config create -h
The influx config create command creates a new InfluxDB connection configuration
and stores it in the configs file (by default, stored at ~/.influxdbv2/configs).
Examples:
# create a config and set it active
influx config create -a -n $CFG_NAME -u $HOST_URL -t $TOKEN -o $ORG_NAME这告诉我我需要提供令牌、组织名称、主机 URL,以及命名配置。
首先,我需要导航到 InfluxDB UI 以生成我的第一个令牌。我通过使用 UI 中的左侧导航转到 Data -> Tokens 来执行此操作。
然后单击 Generate Token 并选择 All Access Token,并为其提供一个名称。
然后我可以单击列表中的令牌来获取令牌字符串
如果我忘记了我的组织名称,我可以从“关于”页面中获取它。
让我们将所有内容放入 CLI 中并创建配置文件
$ influx config create -t cgIsJ7uamKESRiDkRz2mNPScXw_K_zswiOfdZmIQMina1TCtWk2NGu3VssF7cJPPf-QR88nPdFFrlC9GleTpwQ== -o [email protected] -u https://eastus-1.azure.cloud2.influxdata.com/ -n plantbuddy -a产生以下输出
Active Name URL Org
* plantbuddy https://eastus-1.azure.cloud2.influxdata.com/ [email protected]我们现在创建了一个 plantbuddy CLI 配置。
创建一个 bucket 以保存用户数据
下一步是在 InfluxDB 中创建一个 bucket 以保存用户数据。这可以通过 bucket create 命令完成
$ influx bucket create -n plantbuddy
产生以下输出
ID Name Retention Shard group duration Organization ID
f8fbced4b964c6a4 plantbuddy 720h0m0s n/a f1d35b5f11f06a1d这为我创建了一个 bucket,具有默认的最大保留期,即 bucket 保留数据的时间。
上传一些 Line Protocol
现在我有一个 bucket,我可以向其中上传一些数据,以便我可以立即开始测试,而不是首先致力于从我的 Python 代码写入数据。我生成了 2 天的示例数据。
Line Protocol 格式的文档很完善。但这是一个摘录
light,user=rick,device_id=01 reading=26i 1621978469468115968
soil_moisture,user=rick,device_id=01 reading=144i 1621978469468115968
humidity,user=rick,device_id=01 reading=68i 1621978469468115968
soil_temp,user=rick,device_id=01 reading=67i 1621978469468115968
air_temp,user=rick,device_id=01 reading=72i 1621978469468115968
light,user=rick,device_id=01 reading=28i 1621978529468115968
soil_moisture,user=rick,device_id=01 reading=140i 1621978529468115968
humidity,user=rick,device_id=01 reading=65i 1621978529468115968
soil_temp,user=rick,device_id=01 reading=67i 1621978529468115968
air_temp,user=rick,device_id=01 reading=72i 1621978529468115968这表明我正在报告 5 个指标:light、soil_moisture、humidity、soil_temp 和 air_temp。对于每个点,都有一个 user 标签和一个 device id 标签。请注意,此解决方案仅在预期用户拥有有限数量的设备时才有效。否则,标签值的组合最终可能会超出您的基数。字段名称是“reading”,它具有整数值。使用一个快速而粗糙的 Python 脚本,我在过去 48 小时内每分钟生成了其中一个指标,因此它是一个较长的文件。
$ influx write -b plantbuddy -f ~/generated.lp
没有报告错误,所以看起来它工作了,但让我们运行一个查询以确保。
运行查询
我可以使用 CLI 中的 influx query 命令运行测试查询,如下所示
$ influx query "from(bucket: \"plantbuddy\") |> range(start: 0)这会产生大量输出,所以我知道上传 Line Protocol 有效,但我可以优化查询以获得更紧凑的输出。
$ influx query "from(bucket: \"plantbuddy\") |> range(start: 0) |> last() |> keep(columns: [\"_time\",\"_measurement\",\"_value\"]) |> group()"此查询具有以下输出
Result: _result
Table: keys: []
_time:time _value:float _measurement:string
------------------------------ ---------------------------- ----------------------
2021-05-27T16:00:22.881946112Z 70 air_temp
2021-05-27T16:00:22.881946112Z 69 humidity
2021-05-27T16:00:22.881946112Z 36 light
2021-05-27T16:00:22.881946112Z 173 soil_moisture
2021-05-27T16:00:22.881946112Z 66 soil_temp因此,我已经有数据并且可以开始使用查询探索它,但是通过 CLI 迭代查询并不是特别容易。因此,让我们安装并设置 InfluxDB VSCode 插件。
设置 VSCode 和用于 InfluxDB Cloud 的 Flux 扩展
作为 VSCode 用户,我自然希望在编写 Flux 查询时使用他们的编辑器,并保持我的整个项目处于源代码控制之下。因此,下一步是设置 InfluxDB VSCode 扩展。Flux 扩展很容易通过在扩展管理器中搜索“Influx”来找到。
安装扩展后,您可以看到左下方添加了一个 InfluxDB 窗口。
现在我可以使用该窗口通过将焦点放在 InfluxDB 窗口上并单击 + 按钮来设置与我的 Cloud 账户的连接。
如果我忘记了配置 Flux 扩展所需的任何信息,我可以使用 influx config 命令来获取我的凭据
$ influx config
Active Name URL Org
* plantbuddy https://eastus-1.azure.cloud2.influxdata.com/ [email protected]我可以使用 influx auth list 命令找到我的令牌字符串,如下所示
$ influx auth list
由于我的组织名称有一些特殊字符,我需要提供我的组织 ID 而不是我的组织名称。我可以使用 influx org list 命令找到组织 ID,如下所示
$ influx org list
ID Name
f1d35b5f11f06a1d [email protected]然后填写表格。
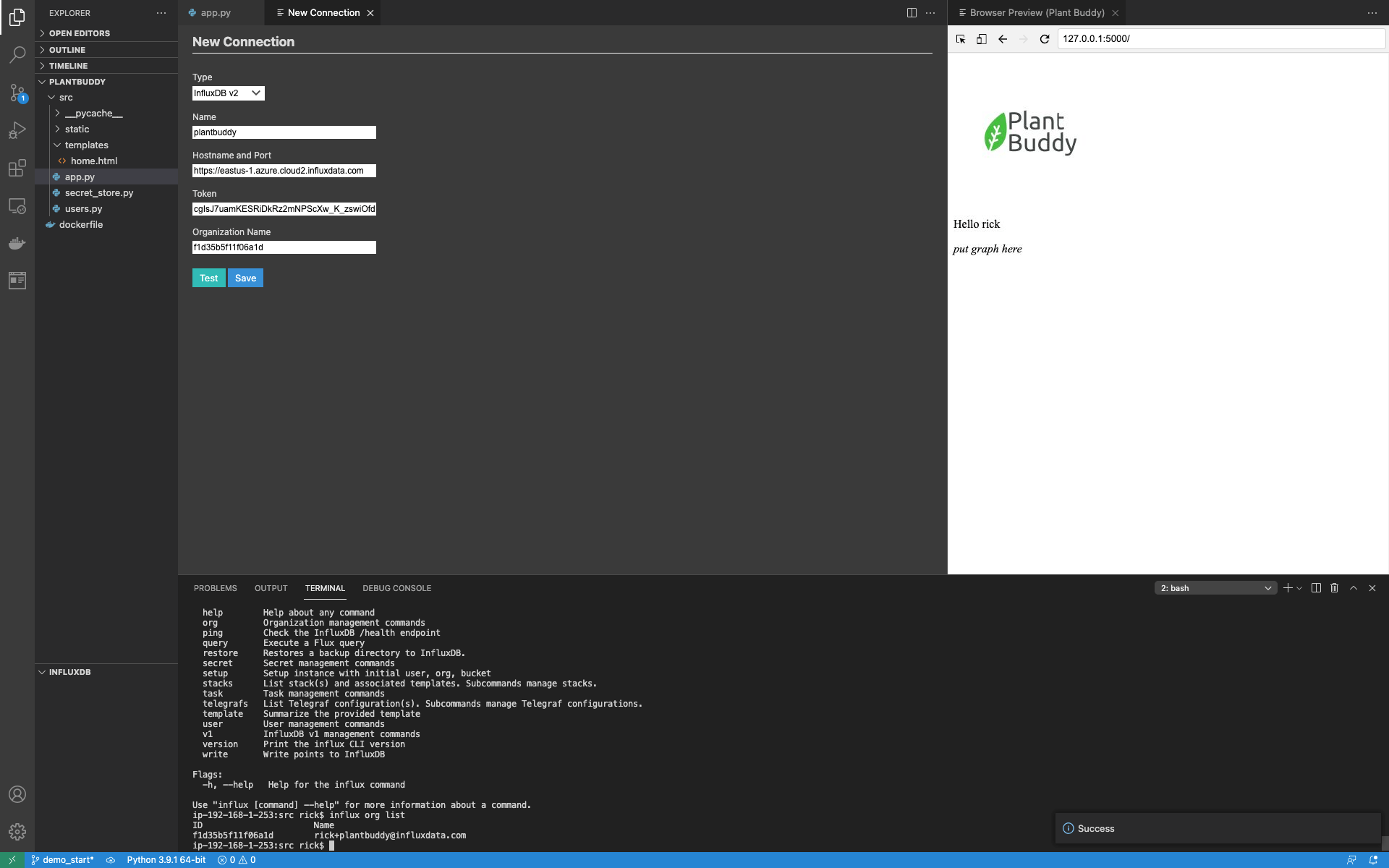
使用 Test 按钮,我可以看到连接工作正常,然后保存它。保存后,请注意 InfluxDB 窗口现在已填充,我可以浏览指标。
从代码编辑器查询 InfluxDB Cloud
现在连接已设置好,我通常会向项目中添加一个临时的 Flux 文件来运行 Flux 查询。
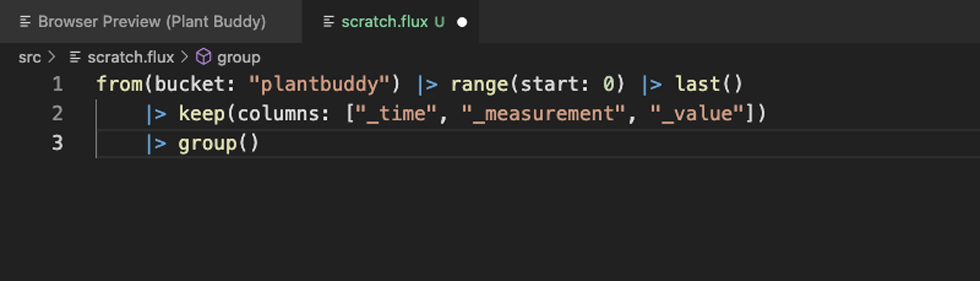
首先要注意的是格式化有效。Flux 扩展还包括语句完成和原位帮助,正如您所期望的那样。
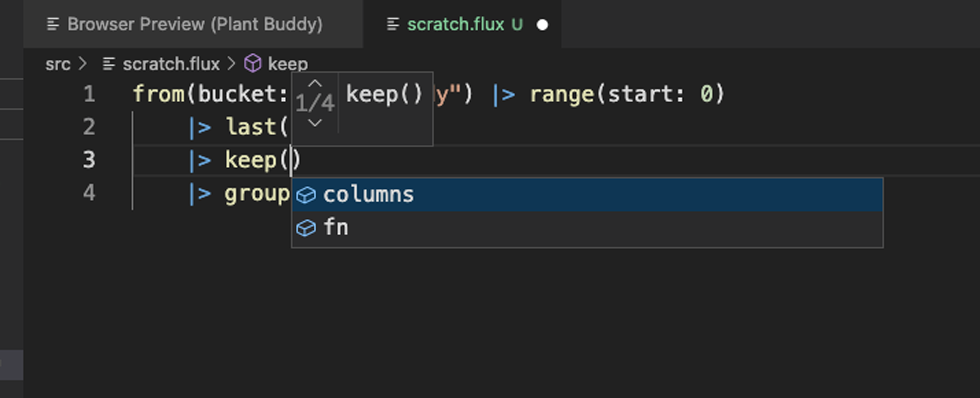
然后我可以尝试直接从编辑器运行查询。
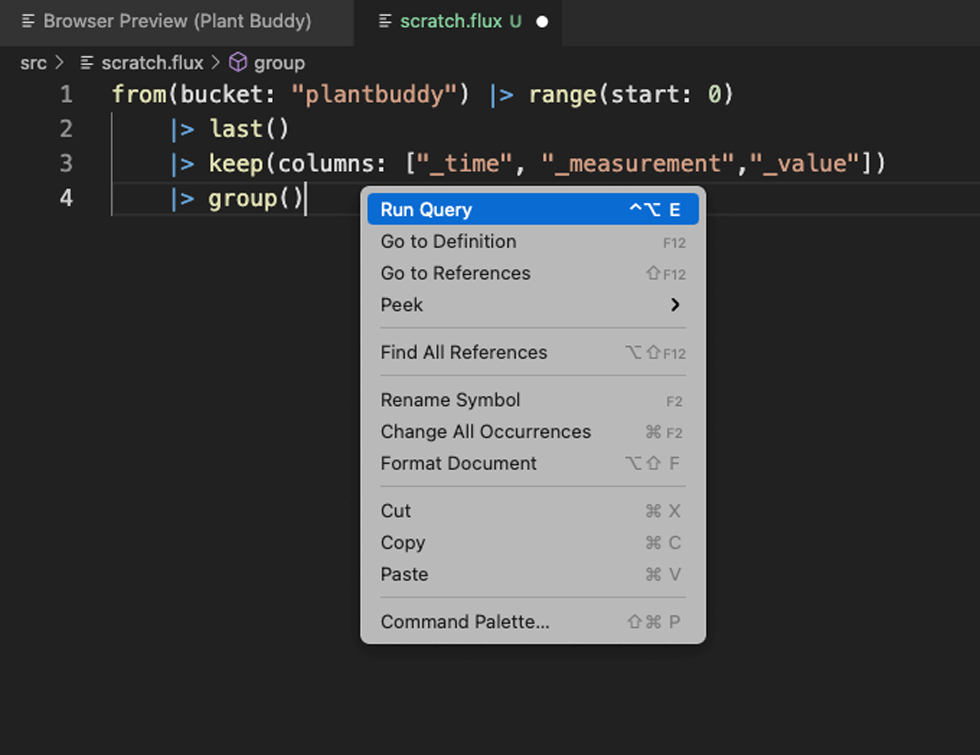
这以清晰的网格视图提供我的结果,这比转储到终端的结果更易于使用。
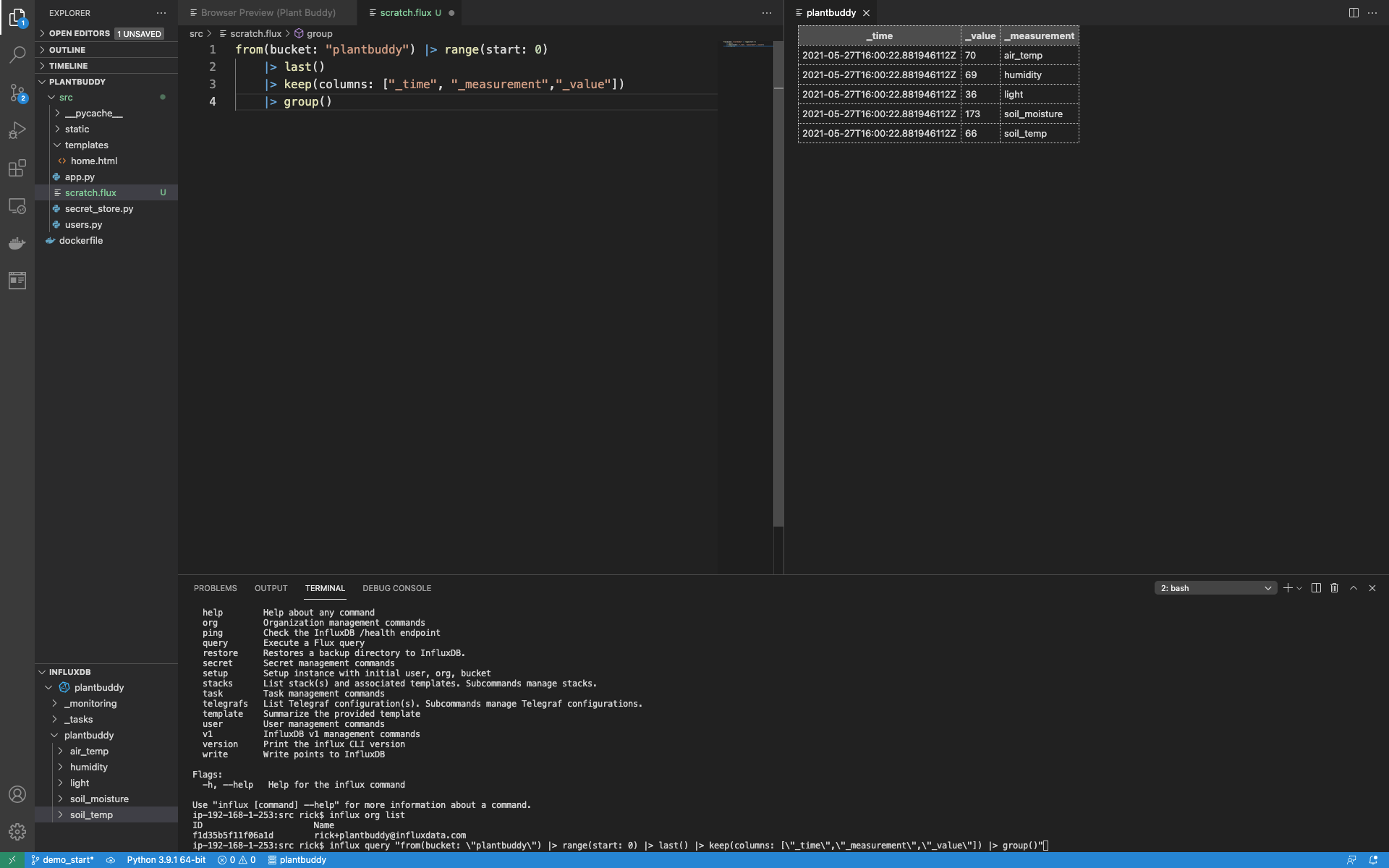
请注意,有关扩展的信息已写入 OUTPUT 窗口的 Flux 语言选项卡。如果您的 Flux 有错误,这尤其有用。
现在我已经为 InfluxDB 设置了我的开发环境,让我们实现后端。
实现写入
现在回到编写一些 Python 代码以使 Web 应用程序工作。首先,我将处理对 /write 端点的调用,方法是将这些调用转换为实际将数据放入 InfluxDB 中。
- 我已经创建了一个名为“plantbuddy”的 bucket 用于此目的。
- 接下来,我将创建一个新令牌,该令牌有权读取和写入该 bucket。
- 然后我将导入 InfluxDB v2 Python 客户端库。
- 然后我将创建 Points 并使用客户端库写入它们。
创建令牌
首先,我需要一个有权从 bucket 写入和读取的令牌。您可以从 influx auth create 帮助中看到,有很多选项可以控制令牌的权限。
k$ influx auth create -h
Create authorization
Usage:
influx auth create [flags]
Flags:
-c, --active-config string Config name to use for command; Maps to env var $INFLUX_ACTIVE_CONFIG
--configs-path string Path to the influx CLI configurations; Maps to env var $INFLUX_CONFIGS_PATH (default "/Users/rick/.influxdbv2/configs")
-d, --description string Token description
-h, --help Help for the create command
--hide-headers Hide the table headers; defaults false; Maps to env var $INFLUX_HIDE_HEADERS
--host string HTTP address of InfluxDB; Maps to env var $INFLUX_HOST
--json Output data as json; defaults false; Maps to env var $INFLUX_OUTPUT_JSON
-o, --org string The name of the organization; Maps to env var $INFLUX_ORG
--org-id string The ID of the organization; Maps to env var $INFLUX_ORG_ID
--read-bucket stringArray The bucket id
--read-buckets Grants the permission to perform read actions against organization buckets
--read-checks Grants the permission to read checks
--read-dashboards Grants the permission to read dashboards
--read-dbrps Grants the permission to read database retention policy mappings
--read-notificationEndpoints Grants the permission to read notificationEndpoints
--read-notificationRules Grants the permission to read notificationRules
--read-orgs Grants the permission to read organizations
--read-tasks Grants the permission to read tasks
--read-telegrafs Grants the permission to read telegraf configs
--read-user Grants the permission to perform read actions against organization users
--skip-verify Skip TLS certificate chain and host name verification.
-t, --token string Authentication token; Maps to env var $INFLUX_TOKEN
-u, --user string The user name
--write-bucket stringArray The bucket id
--write-buckets Grants the permission to perform mutative actions against organization buckets
--write-checks Grants the permission to create checks
--write-dashboards Grants the permission to create dashboards
--write-dbrps Grants the permission to create database retention policy mappings
--write-notificationEndpoints Grants the permission to create notificationEndpoints
--write-notificationRules Grants the permission to create notificationRules
--write-orgs Grants the permission to create organizations
--write-tasks Grants the permission to create tasks
--write-telegrafs Grants the permission to create telegraf configs
--write-user Grants the permission to perform mutative actions against organization users--write-bucket 和 --read-bucket 是我正在寻找的选项。这些选项采用 bucket ID 而不是 bucket 名称。ID 很容易通过 influx bucket list 命令找到
$ influx bucket list
ID Name Retention Shard group duration Organization ID
d6ec11a304c652aa _monitoring 168h0m0s n/a f1d35b5f11f06a1d
fe25b83e9e002181 _tasks 72h0m0s n/a f1d35b5f11f06a1d
f8fbced4b964c6a4 plantbuddy 720h0m0s n/a f1d35b5f11f06a1d然后我可以使用 influx auth create 命令创建令牌,如下所示
$ influx auth create --write-bucket f8fbced4b964c6a4 --read-bucket f8fbced4b964c6a4输出包括令牌字符串,然后我可以将其注册到我的应用程序服务器的密钥存储中。
ID Description Token User Name User ID Permissions
0797c045bc99e000 d0QnHz8bTrQU2XI798YKQzmMQY36HuDPRWiCwi8Lppo1U4Ej5IKhCC-rTgeRBs3MgWsomr-YXBbDO3o4BLJe9g== [email protected] 078bedcd5c762000 [read:orgs/f1d35b5f11f06a1d/buckets/f8fbced4b964c6a4 write:orgs/f1d35b5f11f06a1d/buckets/f8fbced4b964c6a4]导入并设置 InfluxDB Python 库
安装完 InfluxDB Python 客户端 后,接下来的步骤是
- 导入库。
- 设置客户端。
- 创建写入和查询 API。
import influxdb_client
client = influxdb_client.InfluxDBClient(
url = "https://eastus-1.azure.cloud2.influxdata.com/",
token = secret_store.get_bucket_secret(),
org = "f1d35b5f11f06a1d"
)
write_api = client.write_api()
query_api = client.query_api()我在代码文件的顶部添加了这段代码,这样我就可以在整个模块中轻松使用写入和查询 API。
创建和写入数据点 (Points)
现在我已经设置好了客户端库和相关的 API,我可以更改我的代码,使其不再只是打印用户正在上传的数据,而是真正地保存数据。第一步是创建一个数据点 (Point),它是一个代表我要写入的数据的对象。
我将通过创建一个新的函数 “write_to_influx” 来实现这一点
def write_to_influx(data):
p = influxdb_client.Point(data["sensor_name"]).tag("user",data["user"]).tag("device_id",data["device"]).field("reading", int(data["value"]))
write_api.write(bucket="plantbuddy", org="f1d35b5f11f06a1d", record=p)
print(p, flush=True)该方法接收一个 Python 字典,并提取值用于标签 (tags) 和字段 (field)。您可以在一个数据点 (Point) 中包含多个标签 (tags) 和字段 (fields),但 Plant Buddy 仅使用一个字段 (field),“reading”。它还在函数末尾打印出该数据点 (point),主要是为了能够看到它在工作。
现在我可以更新我的写入端点以使用该函数
@app.route("/write", methods = ['POST'])
def write():
user = users.authorize_and_get_user(request)
d = parse_line(request.data.decode("UTF-8"), user["user_name"])
write_to_influx(d)
return {'result': "OK"}, 200我碰巧已经有一个 Plant Buddy 正在向服务器写入数据点 (points),看起来它正在工作。
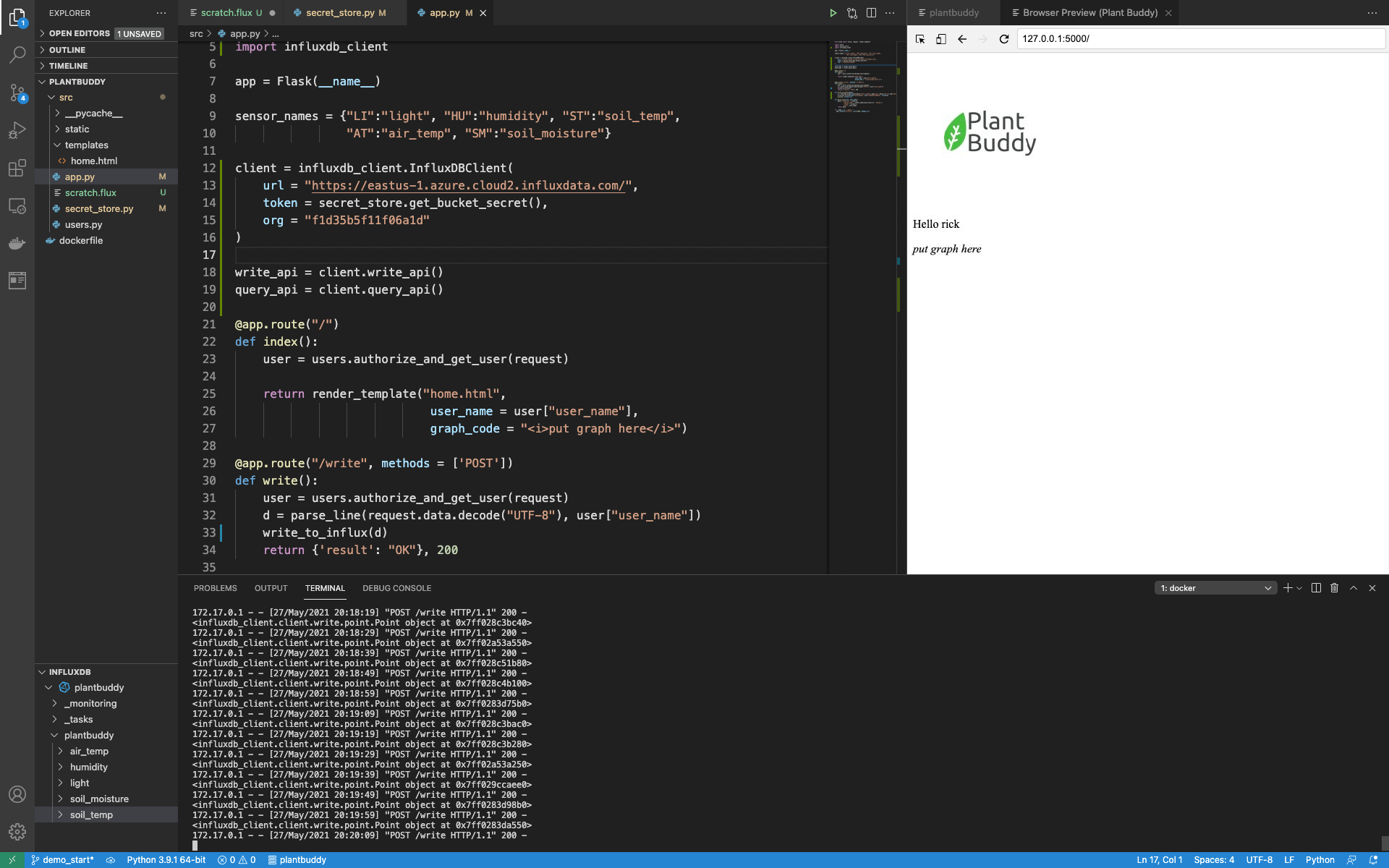
通过运行一个简单的查询,我可以确认数据正在被加载到我的存储桶 (bucket) 中。
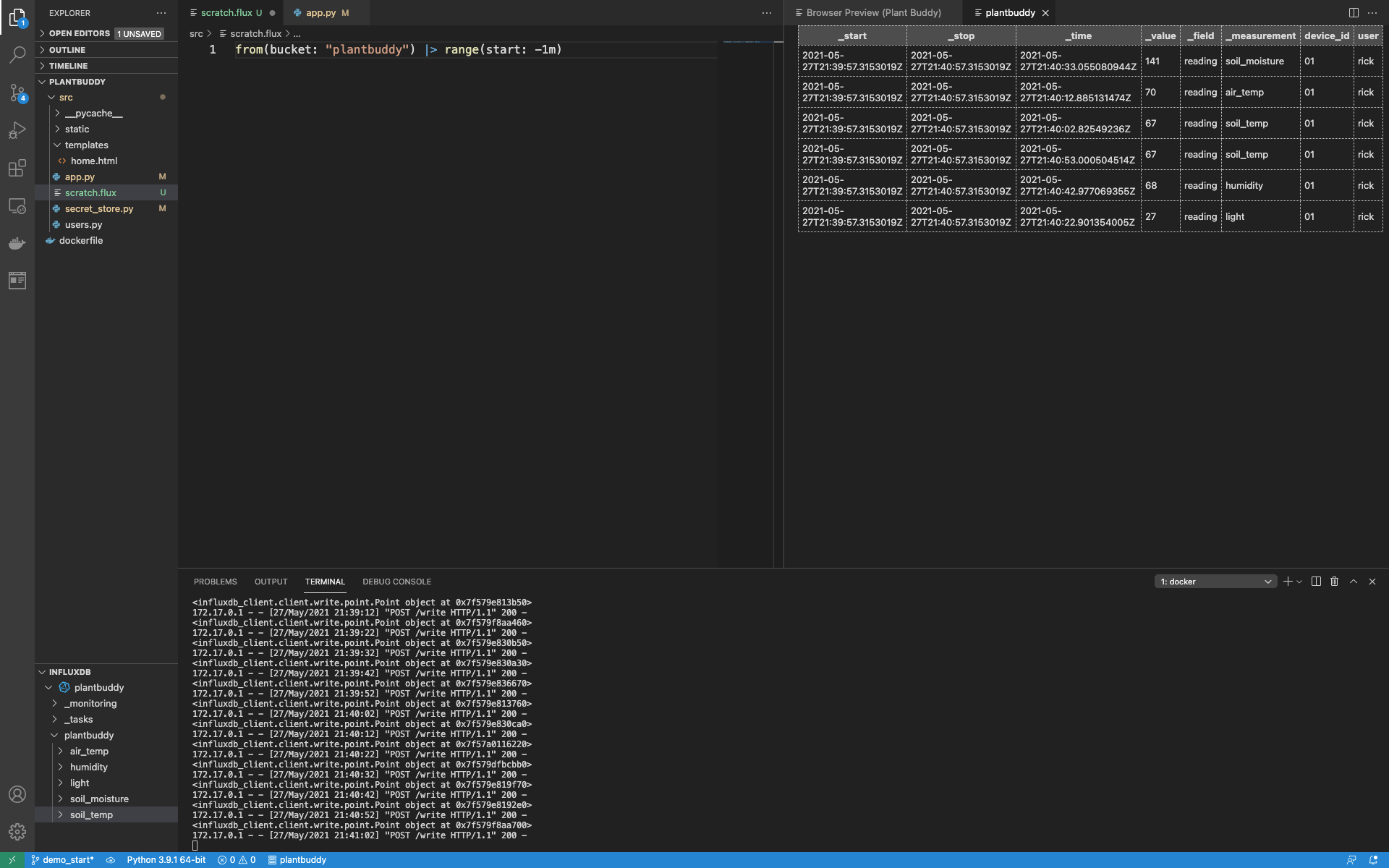
实现读取
Plant Buddy 网页的初始版本将非常简单。它将显示一个图表,其中包含 Plant Buddy 最近 48 小时的数据。为了实现这一点,我需要
- 编写一个查询来获取数据
- 使用 InfluxDB v2 Python 客户端库 来获取数据
- 创建一个图表
- 循环遍历结果并将它们添加到图表中
- 在网页中显示图表
编写查询
这是一个简单的查询。
from(bucket: "plantbuddy")
|> range(start: -48h)
|> filter(fn: (r) => r.user == "rick")这会返回大量数据。重要的是要理解,返回的数据是按时间序列组织的。时间序列首先按 measurements (测量) 组织,然后进一步按标签值和字段细分。每个时间序列本质上是一个按时间戳排序的相关数据的单独表格。非常适合绘图,每个时间序列表格都是图表中的一条线。
但是,我无法在运行时知道用户名,所以我需要参数化查询。我将使用简单的字符串替换来实现这一点。所以我只需要稍微调整一下查询
from(bucket: "plantbuddy")
|> range(start: -48h)
|> filter(fn: (r) => r.user == "{}")此外,我希望在运行时读取此查询,因此我添加了一个名为 “graph.flux” 的文件,并将查询保存在该文件中。
现在我已经准备好查询,我可以使用它来获取数据。
从 InfluxDB 获取数据
在 app.py 中的 index() 函数中,我首先打开 Flux 文件,替换用户名,然后使用我之前实例化的 query api 来获取结果集,并将其添加到我的 index() 函数中
query = open("graph.flux").read().format(user["user_name"])
result = query_api.query(query, org="f1d35b5f11f06a1d")使用 mpld3 和 InfluxDB Cloud 可视化时间序列
对于 Plant Buddy,我选择了 mpld3 库来创建我的图表。我选择这个库是因为它非常容易使用。
在将 mpld3 库及其依赖项添加到我的环境后,我需要导入一些内容
import matplotlib.pyplot as plt, mpld3
现在我可以继续使用结果构建图表了。为此,对于每个 measurement (测量)(光照、湿度等),我需要创建 x 轴的值列表和 y 轴的值列表。当然,x 轴将是时间。
如上所述,Flux 数据模型以完美的格式返回数据,以用于此应用程序。它为每个 measurement (测量) 返回一个表格,所以我只需循环遍历表格,然后循环遍历每个表格中的每条记录,构建列表,并要求 matplotlib 绘制它们。
fig = plt.figure()
for table in result:
x_vals = []
y_vals = []
label = ""
for record in table:
y_vals.append(record["_value"])
x_vals.append(record["_time"])
label = record["_measurement"]
plt.plot(x_vals, y_vals, label=label)然后我完成操作,请求图例,将图表转换为 html,并将其传递给模板以进行渲染。
plt.legend()
grph = mpld3.fig_to_html(fig)
return render_template("home.html",
user_name = user["user_name"],
graph_code = grph)现在,当我加载索引页面时,您可以看到图表正在工作。
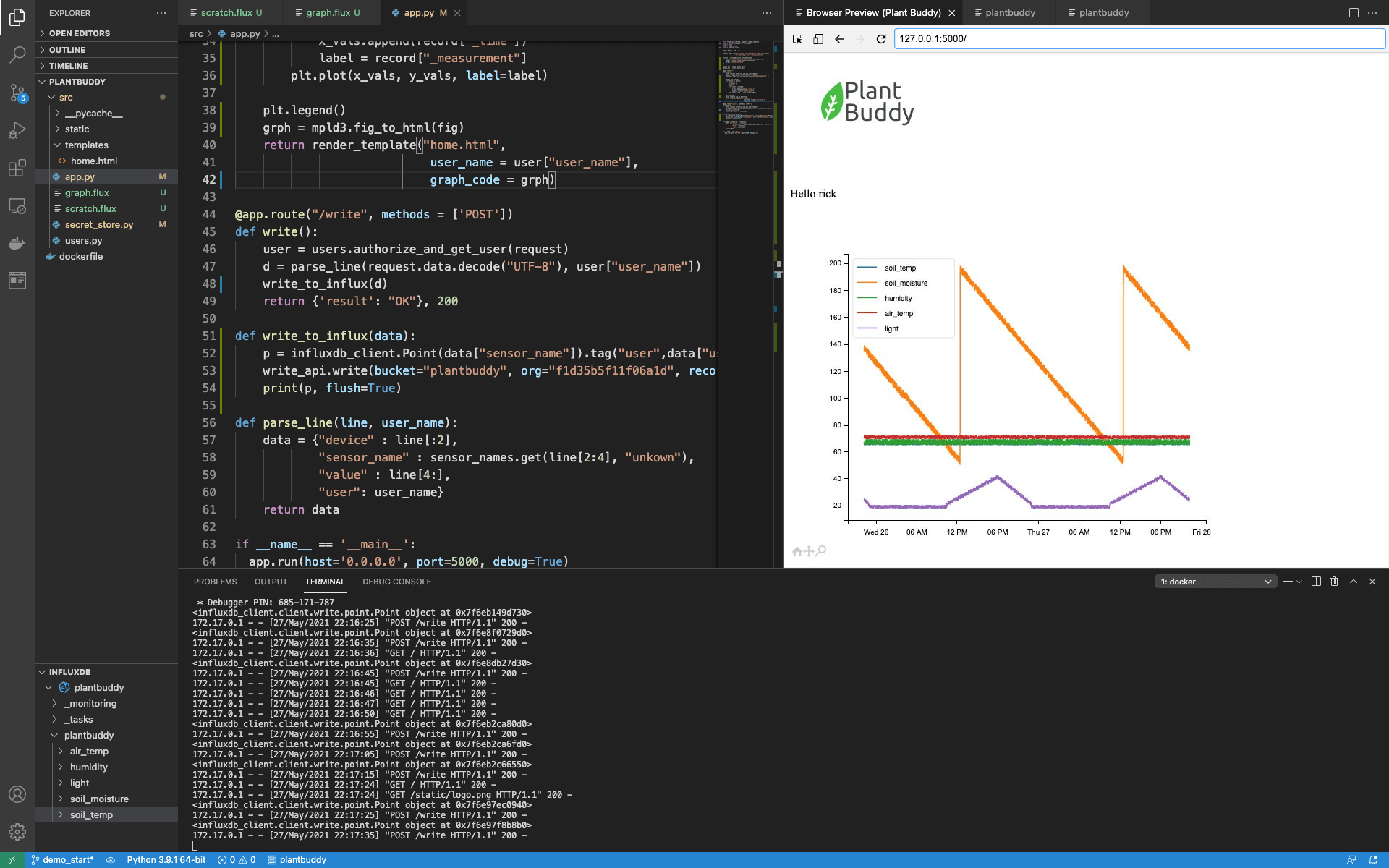
聚合和降采样
聚合
需要注意的一点是,matplotlib 需要相当长的时间来创建图表,mpld3 也需要相当长的时间将其转换为 html。但是用户实际上并不需要绘制每个数据点。因此,我们可以通过在 Flux 查询中添加一些聚合来加快 UI 速度。与其检索每个数据点,不如检索每 10 分钟的平均值。我只需使用 aggregateWindow() 函数向查询添加聚合
from(bucket: "plantbuddy")
|> range(start: -48h)
|> filter(fn: (r) => r.user == "rick")
|> aggregateWindow(every: 10m, fn: mean)页面现在加载速度快得多,而且图表看起来也更好看。
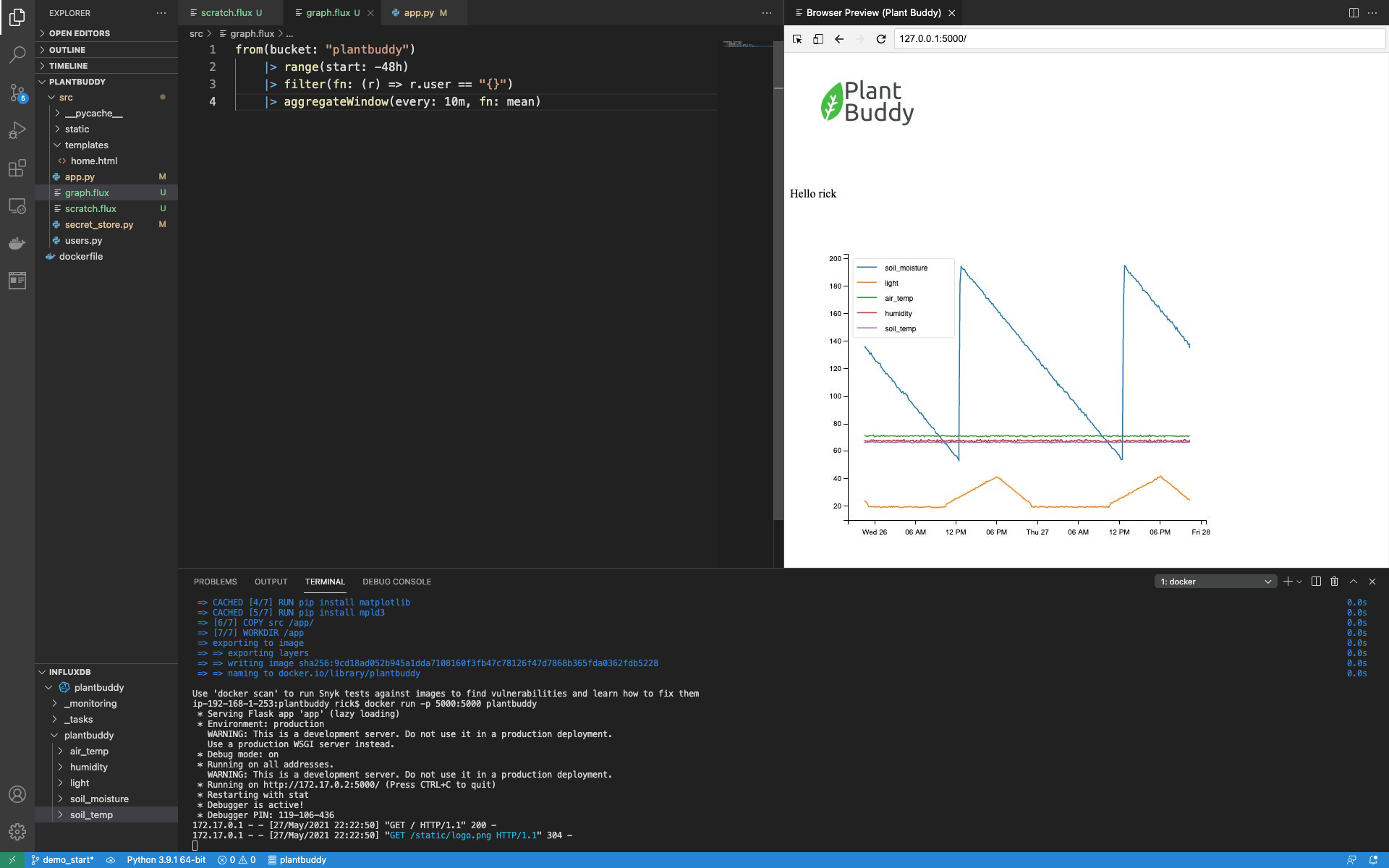
实际上,对于如此简单的查询和数据集,这样的查询对于生产用例来说已经足够了。但是,我们可以演示如何通过降采样进一步优化 UI 延迟。
降采样
降采样 需要计算低分辨率数据以从高分辨率数据中显示,并将预先计算好的数据保存下来以供显示或进一步计算。除了提供更流畅的用户体验之外,它还可以节省您的存储成本,因为您可以将降采样数据保存在保留期比原始数据更长的存储桶 (bucket) 中。
为了实现这一点,我需要
- 创建一个新的降采样存储桶 (bucket) 和一个新的令牌 (token),该令牌 (token) 可以读取和写入该存储桶 (bucket)
- 创建一个降采样 Flux 脚本
- 创建一个任务来定期运行该脚本
- 更改 graph.flux 中的 flux 以查询降采样存储桶 (bucket)
创建一个新的存储桶 (bucket) 和令牌 (token)
首先,我将像以前一样创建一个新的存储桶 (bucket) 并将其命名为 “downsampled”。
$ influx bucket create -n downsampled
输出结果友好地提供了存储桶 (bucket) id
ID Name Retention Shard group duration Organization ID
c7b43676728de98d downsampled 720h0m0s n/a f1d35b5f11f06a1d但是,为了简单起见,我将创建一个可以读取和写入两个存储桶 (bucket) 的单个令牌 (token)。首先,列出存储桶 (bucket) 以获取存储桶 (bucket) id
$ influx bucket list
ID Name Retention Shard group duration Organization ID
d6ec11a304c652aa _monitoring 168h0m0s n/a f1d35b5f11f06a1d
fe25b83e9e002181 _tasks 72h0m0s n/a f1d35b5f11f06a1d
c7b43676728de98d downsampled 720h0m0s n/a f1d35b5f11f06a1d
f8fbced4b964c6a4 plantbuddy 720h0m0s n/a f1d35b5f11f06a1d然后创建具有两个存储桶 (bucket) 的读取和写入权限的令牌 (token)
$ influx auth create --write-bucket c7b43676728de98d --write-bucket f8fbced4b964c6a4 --read-bucket c7b43676728de98d --read-bucket f8fbced4b964c6a4
ID Description Token User Name User ID Permissions
079820bd8b7c1000 hf356pobXyeoeqpIIt6t-ge7LI-UtcBBElq8Igf1K1wxm5Sv9XK8BleS79co32gCQwQ1voXuwXu1vEZg-sYDRg== [email protected] 078bedcd5c762000 [read:orgs/f1d35b5f11f06a1d/buckets/c7b43676728de98d read:orgs/f1d35b5f11f06a1d/buckets/f8fbced4b964c6a4 write:orgs/f1d35b5f11f06a1d/buckets/c7b43676728de98d write:orgs/f1d35b5f11f06a1d/buckets/f8fbced4b964c6a4]然后获取新的令牌 (token) 并替换我的应用程序密钥存储中的旧令牌 (token)。重新启动并确保一切仍然正常工作。
创建一个降采样 Flux 脚本
降采样脚本有两个基本步骤。首先,进行一些聚合,其次,将聚合数据写入某个位置。
我已经从创建新的 graph.flux 文件中找出了我想做的聚合。我将使用现有聚合作为起点添加一个 “downsample.flux” 文件。一个关键的区别是,我想降采样所有数据,而不仅仅是特定用户的数据。因此,我的聚合步骤将跳过过滤器
from(bucket: "plantbuddy")
|> range(start: -48h)
|> aggregateWindow(every: 10m, fn: mean)运行此操作,我可以看到这将聚合存储桶 (bucket) 中的所有数据。
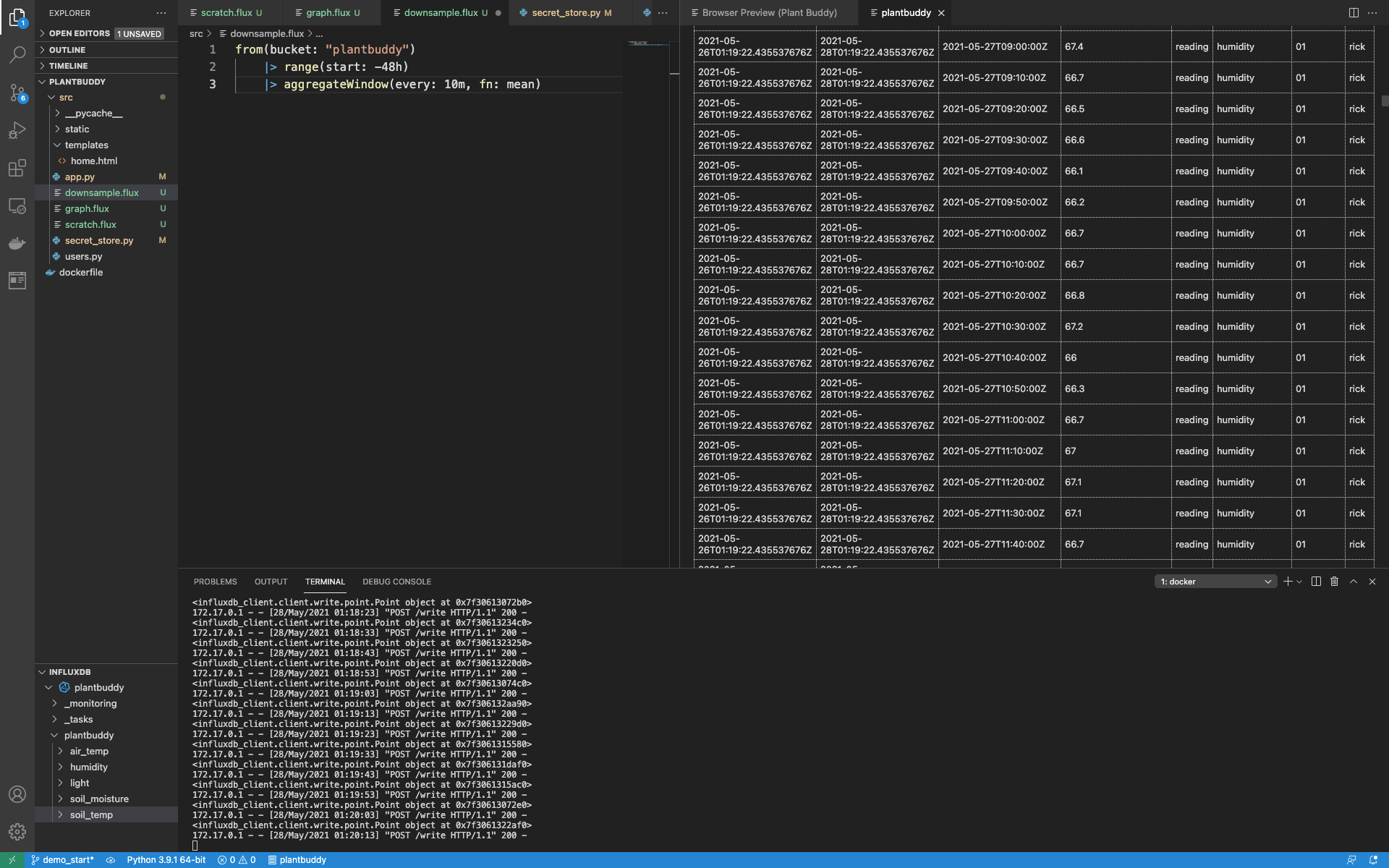
现在我只需要添加 to() 函数,将所有降采样数据写入我的降采样存储桶 (bucket)
from(bucket: "plantbuddy")
|> range(start: -48h)
|> aggregateWindow(every: 10m, fn: mean)
|> to(bucket: "downsampled")查询降采样存储桶 (bucket),我可以看到所有数据都在那里。
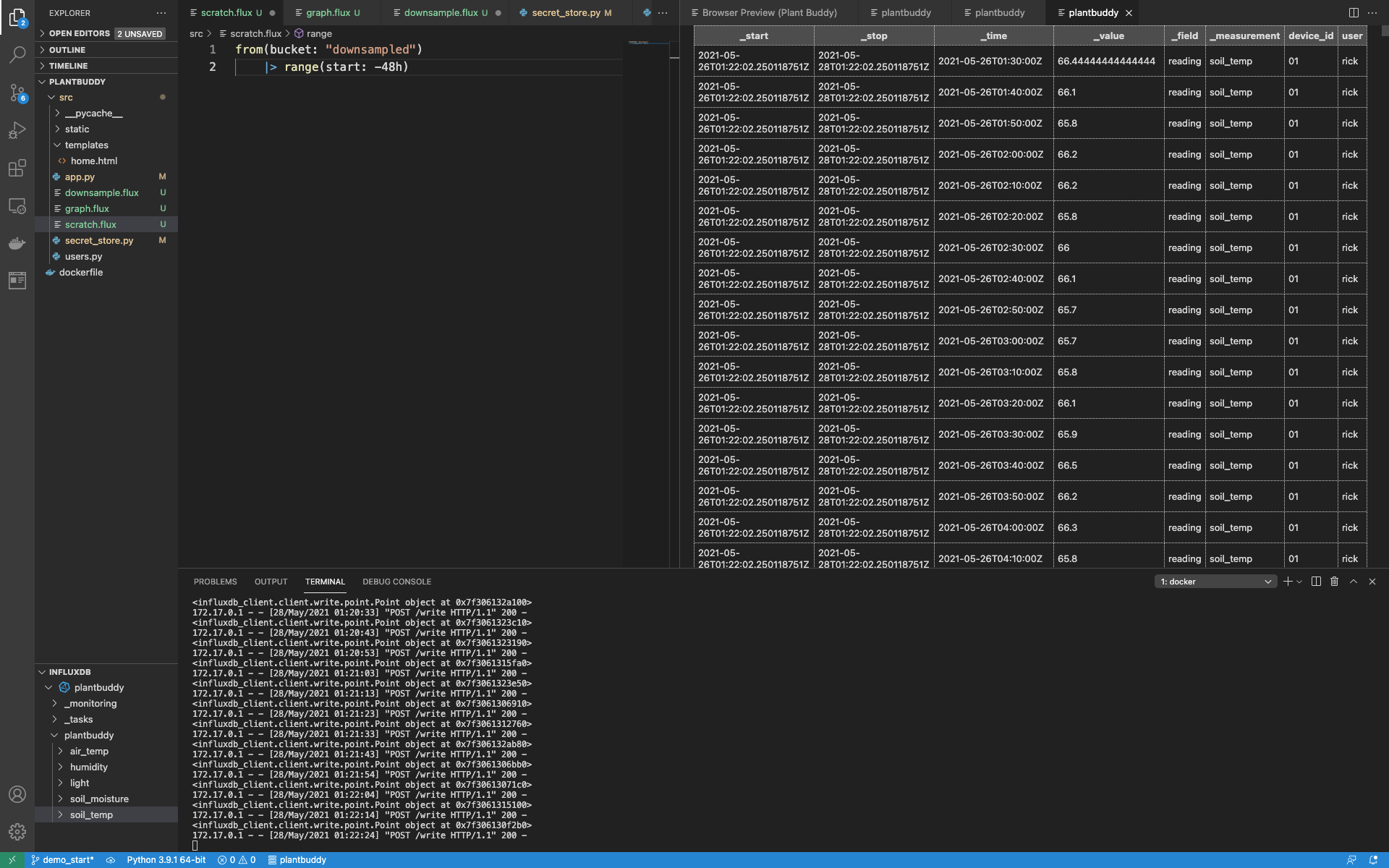
我已经降采样了所有现有数据,所以接下来我将设置一个任务,以便在数据流入时也进行降采样。
从 Flux 脚本创建降采样任务
这只是简单地将我的 downsample.flux 脚本注册为一个每 10 分钟运行一次的任务。
第一步是将范围更改为仅回溯最近 10 分钟。我不想不断地重新降采样我已经降采样过的数据。
from(bucket: "plantbuddy")
|> range(start: -10m)
|> aggregateWindow(every: 10m, fn: mean)
|> to(bucket: "downsampled")接下来,我需要添加每个任务都需要的 option。有不同的可用字段,但我只需要一个名称和 “every”,它告诉任务系统 Flux 的运行频率。
现在我的完整 downsample.flux 看起来像这样
option task = {
name: "downsampled",
every: 10m
}
from(bucket: "plantbuddy")
|> range(start: -10m)
|> aggregateWindow(every: 10m, fn: mean)
|> to(bucket: "downsampled")现在我只需要将其注册到 InfluxDB Cloud。这只需使用带有 CLI 的 task create 即可
$ influx task create -f downsample.flux
ID Name Organization ID Organization Status Every Cron
079824d7a391b000 downsampled f1d35b5f11f06a1d [email protected] active 10m由于输出为我提供了任务 id,我可以使用它来关注任务
$ influx task log list --task-id 079824d7a391b000我可以看到它已成功运行,以及其他一些有用的信息,例如实际运行的 Flux。
RunID Time Message
079825437a264000 2021-05-28T01:30:00.099978246Z Started task from script: "option task = {\n name: \"downsampled\",\n every: 10m\n}\nfrom(bucket: \"plantbuddy\") \n |> range(start: -10m)\n |> aggregateWindow(every: 10m, fn: mean) \n |> to(bucket: \"downsampled\")"
079825437a264000 2021-05-28T01:30:00.430597345Z trace_id=0adc0ed1a407fd7a is_sampled=true
079825437a264000 2021-05-28T01:30:00.466570704Z Completed(success)更新图表查询
最后,我可以更新为图表提供支持的查询,以从降采样存储桶 (bucket) 中读取数据。这是一个更简单、更快速的查询。
from(bucket: "downsampled")
|> range(start: -48h)
|> filter(fn: (r) => r.user == "{}" )重新启动一切,一切都运行得很快!
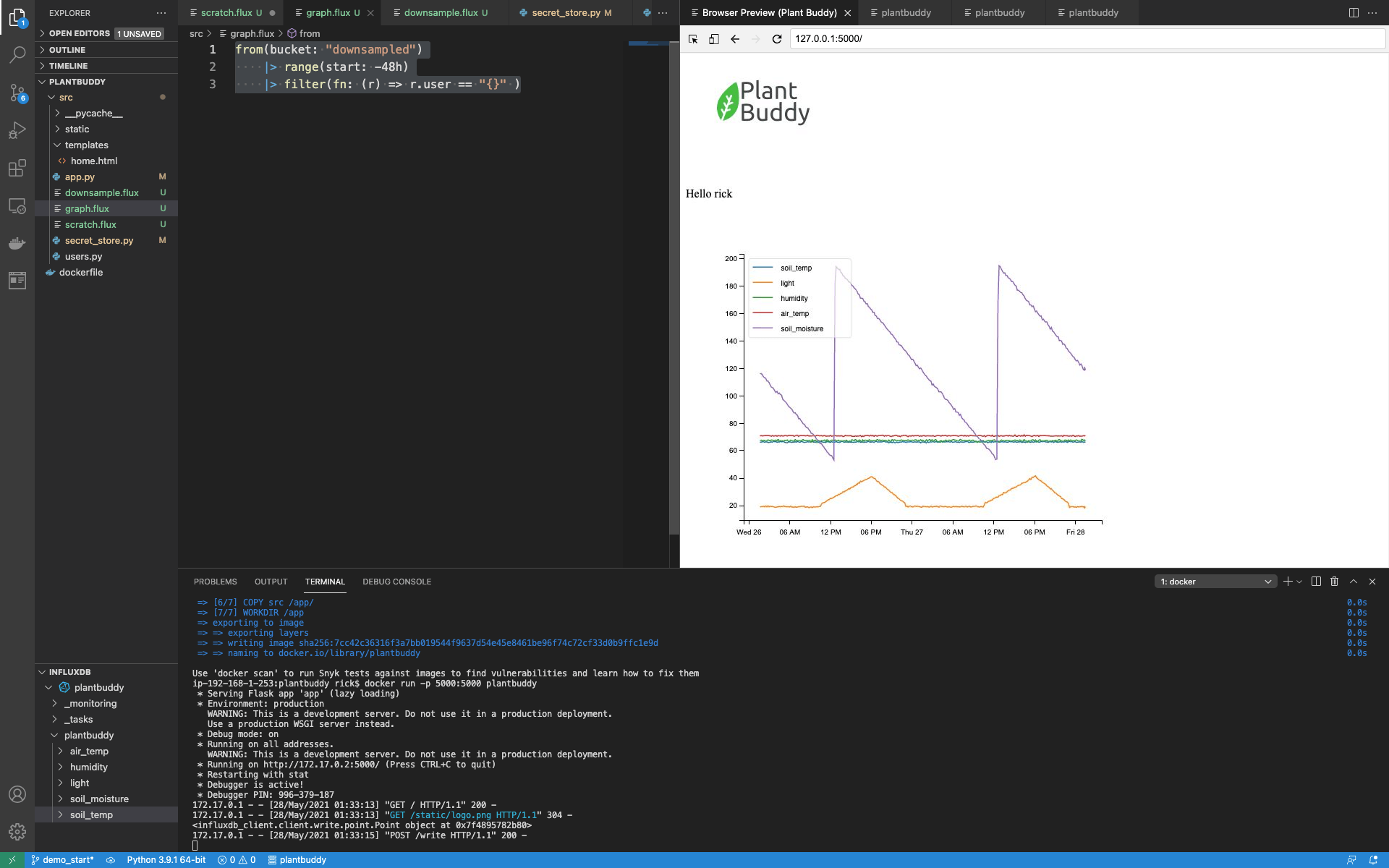
通知
我们将添加的最后一个功能是 plantbuddy.com 在用户土壤变得太干燥时通知用户的能力。使用 InfluxDB,您可以使用任务创建状态检查和通知规则,这些规则将在您定义的任何条件下向您的应用程序发送消息。您不应向您的应用程序添加轮询逻辑来读取状态;您应该让 InfluxDB 为您执行此操作!
虽然有更简单的方法可以使用单个任务来实现此功能,例如通过执行简单的查询,然后直接在同一任务中使用 http.post(),但 plantbuddy.com 将充分利用整个 Checks and Notifications System (检查和通知系统)。额外的优势尤其包括存储在 _monitoring 存储桶 (bucket) 中的状态和通知记录。此外,由于此数据以标准格式存储,因此可以轻松共享仪表板和查询等工具。
阈值检查
我要设置的第一种任务是阈值检查。这是一个任务,它
- 查询数据以查找感兴趣的值
- 检查这些值是否超过某些阈值
- 使用 Flux monitor 库将时间序列数据写入 _monitoring 存储桶 (bucket)
- 从 Flux 脚本创建一个任务并开始运行它
查询您要检查的值
如果任何用户的土壤湿度水平变得太干燥,Plant Buddy 将能够向他们提供通知。我将在一个新文件 check.flux 中创建相关的 Flux 查询(即将成为任务)。一个简单的查询可以回顾过去并找到所有(且仅限)土壤湿度水平
data = from(bucket: "plantbuddy")
|> range(start: -10m)
|> filter(fn: (r) => r._measurement == "soil_moisture")请注意,我正在查询 plantbuddy 存储桶 (bucket) 中的原始数据,而不是降采样数据。
定义值的阈值
接下来我需要确定要监视的不同阈值。Checks 系统将使用这些阈值来设置每行数据的状态。阈值检查有 4 个可能的级别
- ok (正常)
- Info (信息)
- warn (警告)
- crit (严重)
通过为每个级别创建一个谓词函数来设置阈值,该函数返回一个布尔值,定义值是否在该阈值内。您不需要在阈值检查中使用所有级别。对于 Plant Buddy,土壤湿度可以是 “ok (正常)” 或 “crit (严重)”,所以我只定义这两个函数
ok = (r) => r.reading > 35
crit = (r) => r.reading <= 35基本上,如果土壤湿度读数降至 35 或以下,则为严重。
如上所述,结果状态将写入 _monitoring 存储桶 (bucket)。您还需要提供一个谓词函数来创建要记录的消息。此消息可以是复杂的或简单的。我保持简单
messageFn = (r) => "soil moisture at ${string(v:r.reading)} for ${r.user}"这些谓词函数是 monitor.check() 函数的参数,该函数生成状态并将它们写入 _monitoring 存储桶 (bucket),我们将在下面使用它。
使用 monitoring.check() 函数为每条记录生成状态
monitoring 包有一个名为 monitoring.check() 的函数,它现在负责计算和记录您的状态。它将遍历返回的数据中的每条记录,计算状态级别(在本例中为 ok (正常) 或 crit (严重)),计算消息字符串,然后将该字符串连同其他一些信息一起记录在 _monitoring 存储桶 (bucket) 中。
但是,首先,我们需要向 monitor.check 提供一些元数据。需要 id、name、type 和标签 (tags) 列表。当您有多个通知规则时,标签 (tags) 很有用。由于目前我只计划一个,所以我将标签 (tags) 对象留空。
check = {_check_id: "check1xxxxxxxxxx",
_check_name: "soil moisture check",
_type: "threshold",
tags: {}现在我的脚本可以继续调用 monitor.check。有几件事需要注意
- 需要通过 schema.fieldsAsCols() 函数进行管道转发。这是 monitor.check 函数期望的形状。它还有助于使某些检查更容易编写,因为您可以更轻松地编写表达式来组合来自不同字段的值。
- 有点令人困惑,因为 check meta
data 参数名为 “data”。我将此选项称为 “check”,并将我检索到的时间序列数据称为 “data”。这在我看来更清楚。</li> <li>我添加了 yield(),以便我更容易运行脚本并检查结果。</li> </ol>
data
|> v1["fieldsAsCols"]()
|> yield()
|> monitor.check(data: check, messageFn: messageFn, crit: crit, ok: ok)当您将所有内容放在一个位置时,更容易看到它是如何工作的
import "influxdata/influxdb/monitor"
import "influxdata/influxdb/v1"
option task = {name: "soil moisture check", every: 10m, offset: 0s}
data = from(bucket: "plantbuddy")
|> range(start: -10m)
|> filter(fn: (r) => r._measurement == "soil_moisture")
ok = (r) => r.reading > 35
crit = (r) => r.reading <= 35
messageFn = (r) => "soil moisture at ${string(v:r.reading)} for ${r.user}"
check = {_check_id: "check1xxxxxxxxxx",
_check_name: "soil moisture check",
_type: "threshold",
tags: {}
}
data
|> v1["fieldsAsCols"]()
|> yield()
|> monitor.check(data: check, messageFn: messageFn, crit: crit, ok: ok)现在我可以手动运行我的检查了。正如预期的那样,它为过去 10 分钟的每个读数创建了一个 “_level” 为 “ok (正常)” 的状态。
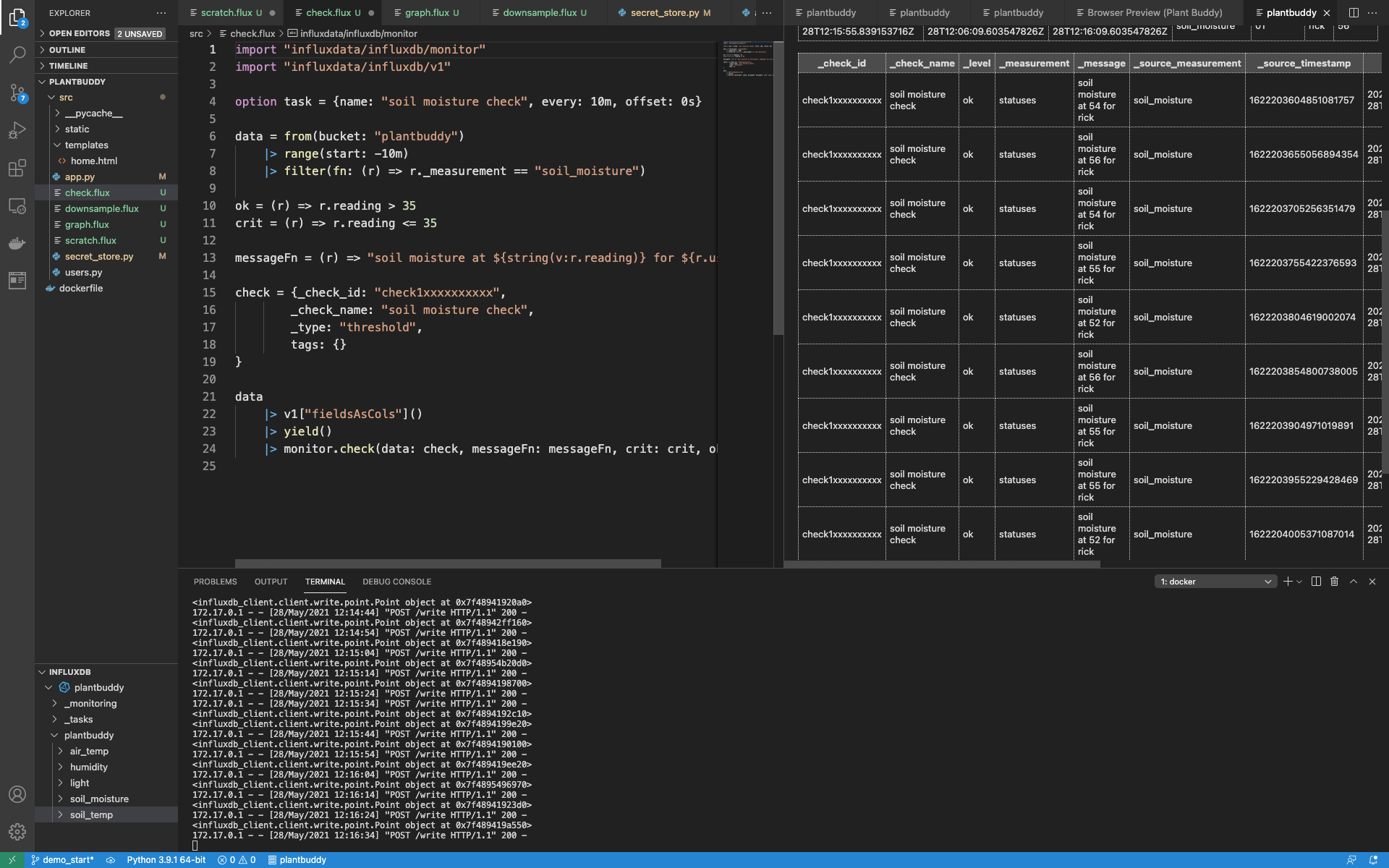
我可以更深入一点,直接查询 _monitoring 存储桶 (bucket)
from(bucket: "_monitoring")
|> range(start: -5m)
|> filter(fn: (r) => r._field == "_message")
一切看起来都不错,所以接下来,我将设置 InfluxDB 以按计划运行 check.flux 中的代码。
创建阈值检查任务
我已经添加了选项以将脚本转换为任务
option task = {name: "soil moisture check", every: 10m, offset: 0s}所以,现在我只需使用 check.flux 文件创建任务即可
$ influx task create -f check.flux
ID Name Organization ID Organization Status Every Cron
0798ba98b30d5000 soil moisture check f1d35b5f11f06a1d [email protected] active 10m现在我有一个每 10 分钟运行一次的任务,该任务正在记录状态,所以接下来我需要编写一个通知规则,这是另一个任务,它将调用 Plant Buddy 上的一个端点,以便 Plant Buddy 可以通知用户。
通知规则
为了编写此任务,我需要完成以下几件事
- 向 InfluxDB 添加一个密钥 (secret),以便 Plant Buddy 可以授权来自 InfluxDB Cloud 的任何通信
- 向 plantbuddy.com 添加一个端点,以便在满足通知规则的条件时被调用
- 在 Flux 中创建一个端点变量,该变量指向一个可公开访问的 url(我在我的防火墙上打了一个洞,以便我的开发服务器可以从 InfluxDB Cloud 访问)
- 使用 monitoring 库搜索我要通知用户的任何状态(特别是当 _level 为 crit (严重) 时)
- 为每个与该条件匹配的记录调用端点,并发送检查创建的消息
在 InfluxDB Cloud 中存储和使用密钥 (secret)
首先,我想存储 Plant Buddy 将用于验证任何传入请求是否来自 InfluxDB 的令牌 (token)。我可以简单地将其添加到 Flux 脚本中,但使用平台的密钥 (secret) 存储比将它们保存在源代码中安全得多。
$ influx secret update -k pb_secret -v sqps8LCY6z8XuZ2k
Key Organization ID
pb_secret f1d35b5f11f06a1d然后我可以使用此代码检索密钥 (secret)。我创建了一个名为 notifation_rule.flux 的新文件来存储此 Flux。这就是检索密钥 (secret) 作为字符串所涉及的全部内容
import "influxdata/influxdb/secrets"
secrets.get(key: "pb_secret")向 Plant Buddy 添加端点
实际上,以某种方式通知用户尚未实现,因此,我将简单地将此代码添加到 app.py 中,以便我可以确保系统端到端地工作
@app.route("/notify", methods = ['POST'])
def notify():
print("notification received", flush=True)
print(request.data, flush=True)
return {'result': "OK"}, 200
# TODO: check the authorization and actually notify the user将端点添加到 Flux
现在我可以在我的 Flux 中引用该端点
endpoint = http.endpoint(url: "http://71.126.178.222:5000/notify")
您可能会注意到,我尚未提供标头或正文。因为我希望正文是与每个状态一起存储的消息,所以我将在实际调用端点时动态添加标头和正文。
查找匹配的状态
此代码使用 monitor 库中内置的便利函数来回顾 2 分钟,并查找任何设置为 crit (严重) 的状态
monitor.from(start: -2m)
|> filter(fn: (r) => r._level == "crit")在接下来的步骤中,我将实际触发并记录任何匹配的通知。
设置通知规则任务
就像状态检查一样,Flux 中的 monitor 库需要特定格式的元数据,以便 notify 函数可以工作。我在此对象中定义它
rule = {
_notification_rule_id: "notif-rule01xxxx",
_notification_rule_name: "soil moisture crit",
_notification_endpoint_id: "1234567890123456",
_notification_endpoint_name: "soil moisture crit",
}通知
我现在可以完成工作并调用 monitor.notify() 函数。我只需要提供
- 我为通知定义的元数据。当触发通知时,这将用于记录 InfluxDB 中发生的通知事件(以及通知是否已成功发送)。
- 提供一个 map() 函数,该函数返回我想通过 http.post() 发送到我定义的端点的标头和数据。
monitor.from(start: -2m)
|> filter(fn: (r) => r._level == "crit")
|> monitor.notify(
data: rule,
endpoint: endpoint(
mapFn: (r) => ({
headers: {"Authorization":secrets.get(key: "pb_secret")},
data: bytes(v: r._message),
}),
),
)
|> yield(name: "monitor.notify")当我运行此操作时,没有结果。
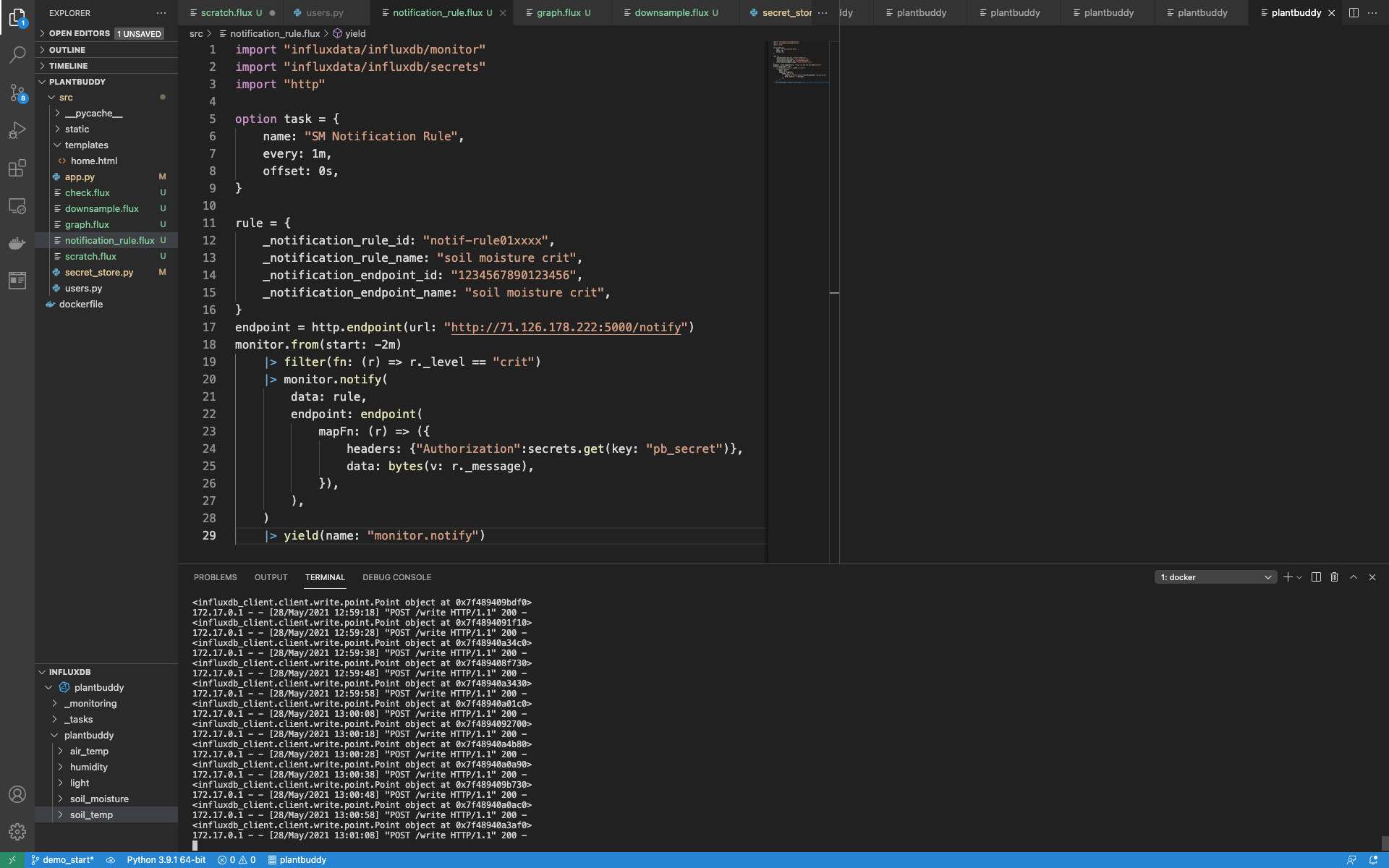
这是因为没有 crit (严重) 状态。但是,我可以人为地创建一个 crit (严重) 状态来产生结果
$ influx write --bucket plantbuddy "soil_moisture,user=rick,device_id=01 reading=20i"
然后我可以重新运行 check.flux 和 notifcation_rule.flux,并查看我的应用程序是否收到了通知,以及 InfluxDB 是否记录了已发送的通知。
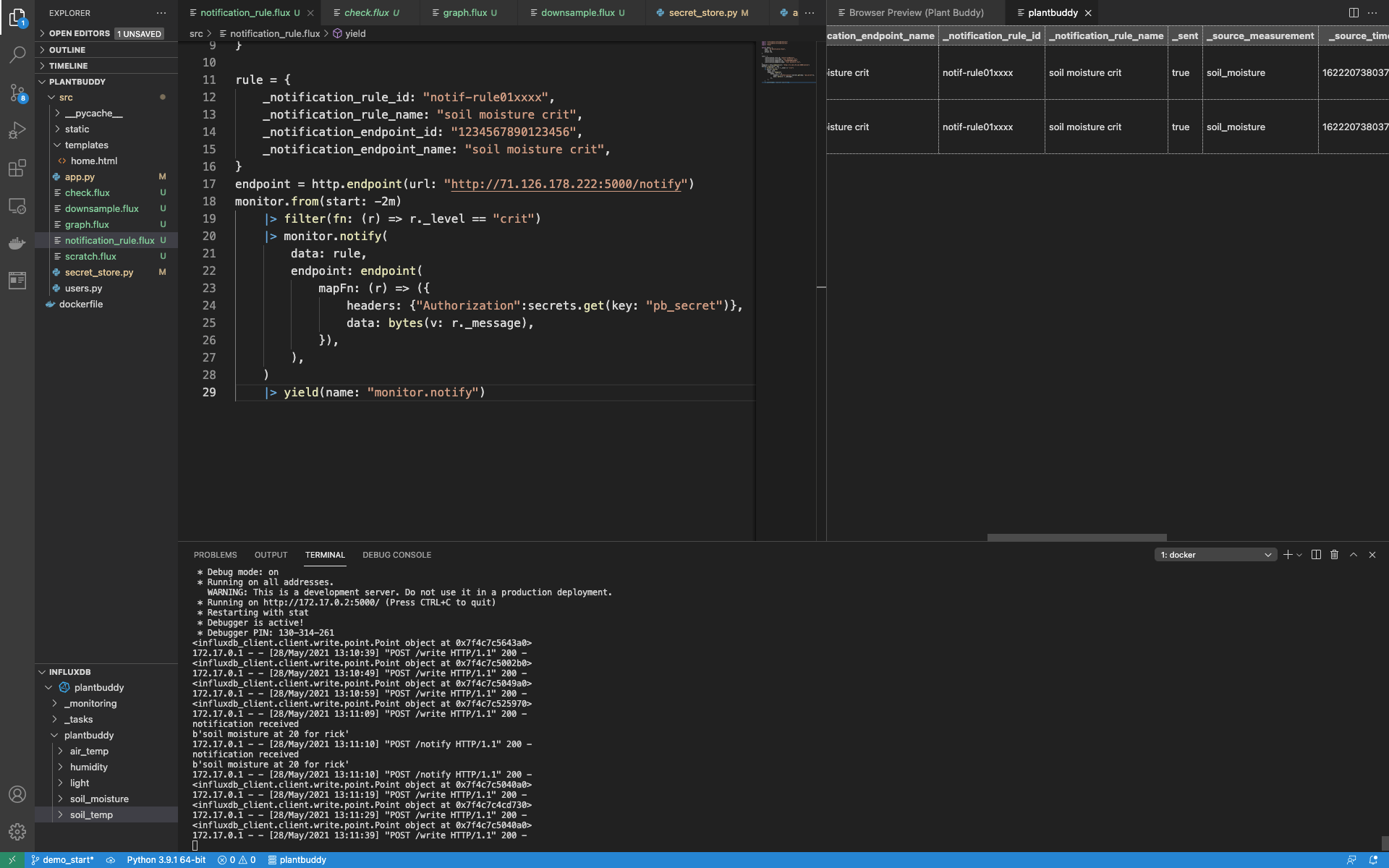
再一次,我认为当您看到 notification_rule.flux 的完整内容时,更容易看到它是如何协同工作的
import "influxdata/influxdb/monitor"
import "influxdata/influxdb/secrets"
import "http"
option task = {
name: "SM Notification Rule",
every: 1m,
offset: 0s,
}
rule = {
_notification_rule_id: "notif-rule01xxxx",
_notification_rule_name: "soil moisture crit",
_notification_endpoint_id: "1234567890123456",
_notification_endpoint_name: "soil moisture crit",
}
endpoint = http.endpoint(url: "http://71.126.178.222:5000/notify")
monitor.from(start: -2m)
|> filter(fn: (r) => r._level == "crit")
|> monitor.notify(
data: rule,
endpoint: endpoint(
mapFn: (r) => ({
headers: {"Authorization":secrets.get(key: "pb_secret")},
data: bytes(v: r._message),
}),
),
)
|> yield(name: "monitor.notify")创建通知规则任务
最后,为了完成它,我需要将通知规则注册为 InfluxDB 的任务。与之前一样,我需要创建一个名为 “task” 的选项,以便任务系统知道如何处理脚本
option task = {
name: "SM Notification Rule",
every: 1m,
offset: 0s,
}然后,我可以像以前一样简单地创建任务。
$ influx task create -f notification_rule.flux
ID Name Organization ID Organization Status Every Cron
0798c6de048d5000 SM Notification Rule f1d35b5f11f06a1d [email protected] active 1m运维监控
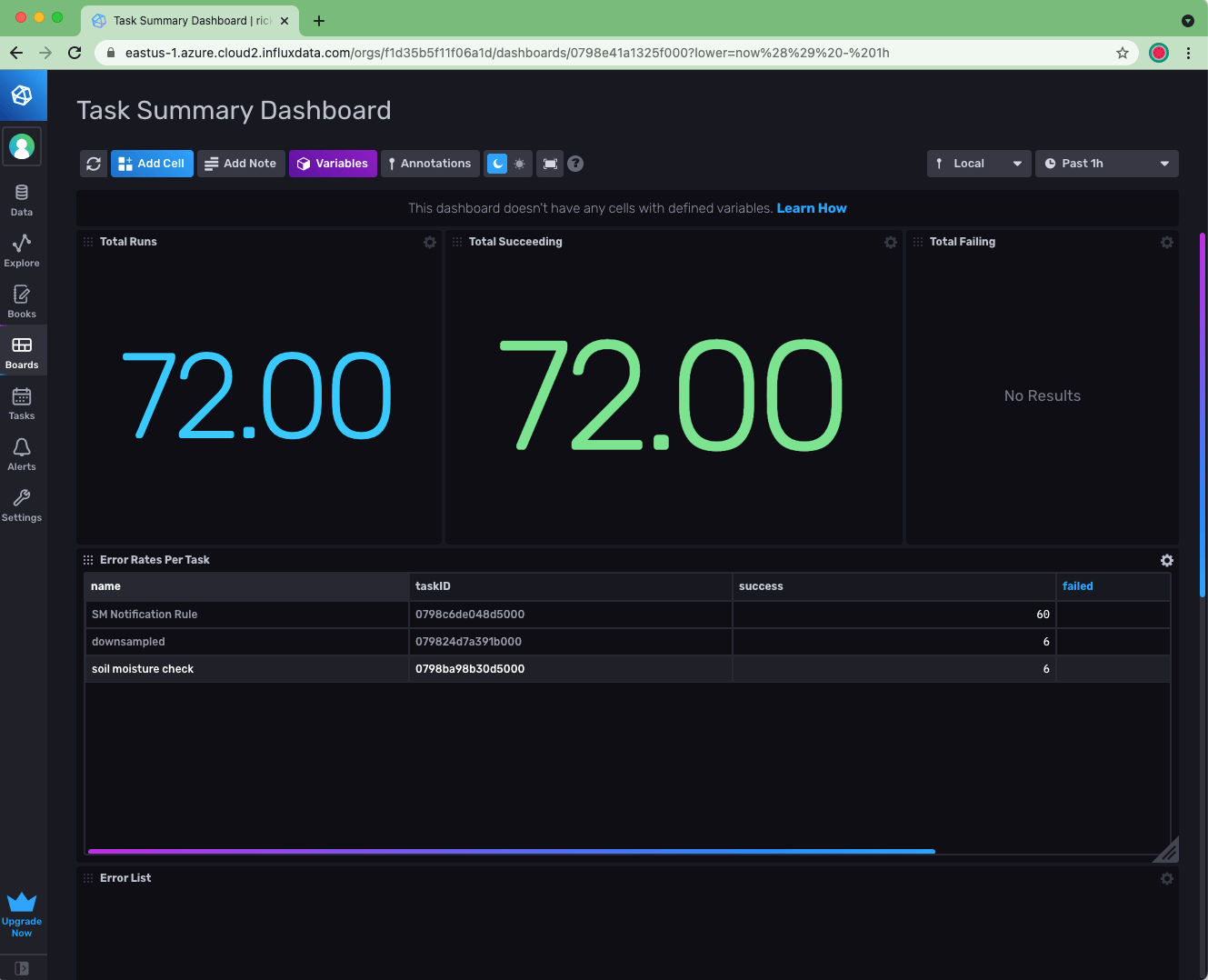
关于我的 InfluxDB 后端,我现在有
- 数据流入 InfluxDB
- 3 个任务正在运行:降采样任务、阈值检查任务和通知规则任务
我如何密切关注后端是否正常运行?通过将 Operational Monitoring Template (运维监控模板) 安装到您的帐户中,可以轻松实现这一点。请注意,您需要从免费帐户升级才能拥有足够的存储桶 (bucket) 配额来安装模板。
安装模板后,例如,我可以使用 Task Summary Dashboard (任务摘要仪表板) 来确认我的所有任务都运行良好。我可以继续创建检查和通知,以便在出现任何问题时提醒我(而不是我的用户)。