InfluxDB Cloud 2.0 Beta 免费层级发布
作者:Paul Dix / 产品, 开发者
2019 年 5 月 7 日
导航至
我很高兴地宣布,今天我们发布了 InfluxDB 2.0 Cloud 产品的公开 Beta 版。此云版本包含 InfluxDB 2.0 开源 alpha 9 版本中发布的所有内容,但采用完全托管和托管的产品形式。虽然我们的 InfluxDB 1.x Cloud 产品类似于 RDS 的托管数据库服务,但 InfluxDB Cloud 2.0 服务更像是一个时间序列数据库、仪表板、分析、监控和无服务器 Flux 系统合而为一。它被设计为多租户的,这使我们能够为所有用户提供免费层级。更棒的是,它将提供基于使用量的定价,无需客户提前确定他们需要的实例、存储或内存的大小。InfluxDB 2.0 Cloud 将根据您的需求进行扩展,您只需为您使用的部分付费。在这篇文章中,我将介绍 Beta 阶段的预期内容、未来几周和几个月内我们将推出的功能以及定价模型的工作方式。
Beta 阶段和示例
在 Beta 阶段,我们将所有人的使用量限制在免费层级限制内。它不适用于生产用途,并且在这个早期阶段,事情可能会出错。但我们认为尽早发布以与社区迭代非常重要。关于 InfluxDB Cloud 的反馈直接影响我们为 InfluxDB 2.0 开源版本开发的内容。
尽管存在限制,您应该能够通过我们的数据收集代理 Telegraf 收集服务器、服务或任何类型的数据,并将其发送到我们的云端。我们预计您将能够从大约 10 个独立的 Telegraf 代理发送数据,这些代理以 10 秒的间隔收集数据,数据保留期限限制为 72 小时,查询吞吐量限制在拥有实时仪表板的一个用户产生的数据量左右。我们还为 Javascript 和 Go 提供了官方支持的客户端库,其他语言版本即将推出。如果您达到限制,用户界面将提示您并发送电子邮件。您可以请求增加限制,但我们希望收到您的反馈,以了解更多关于您的用例以及您对服务的看法。
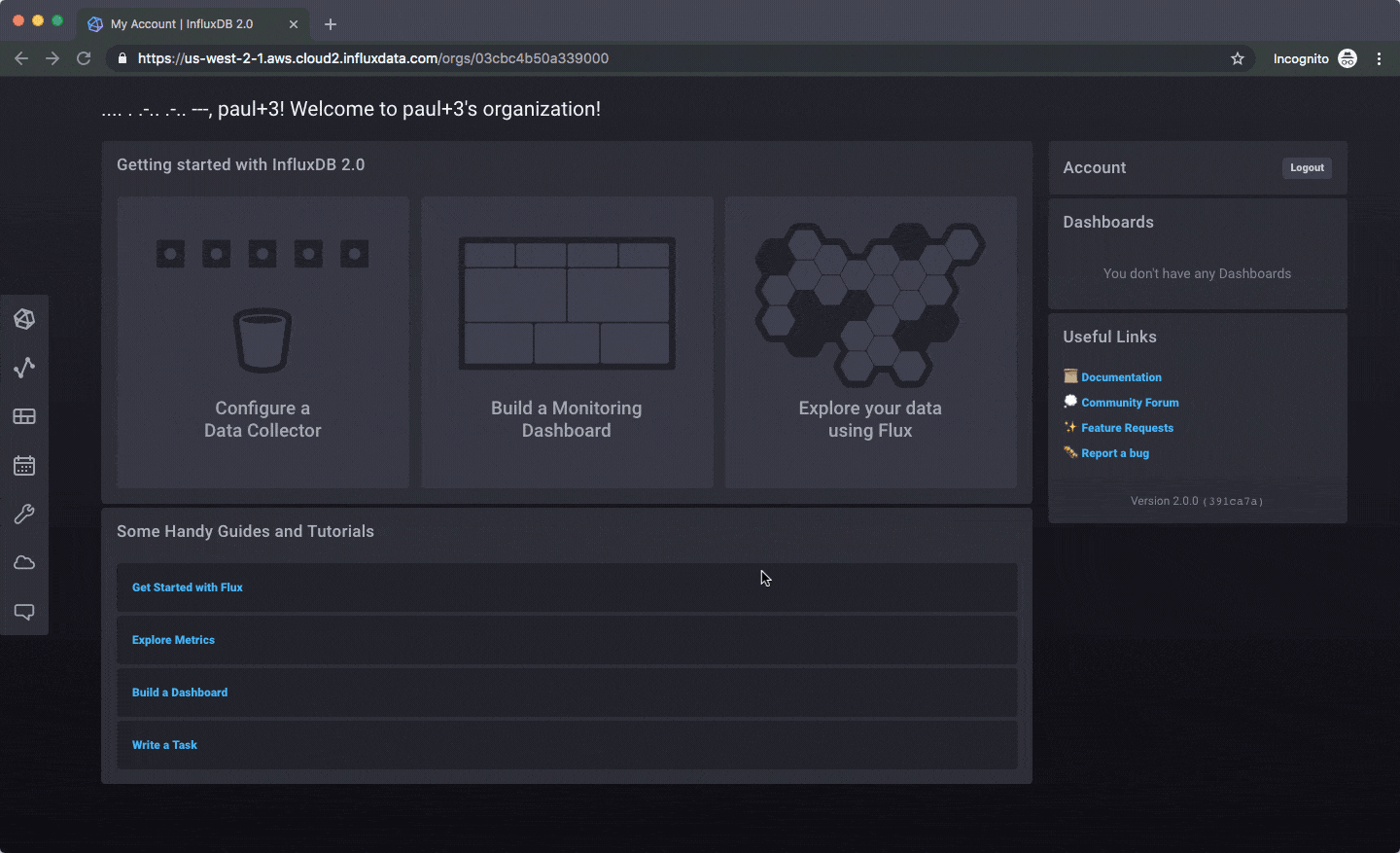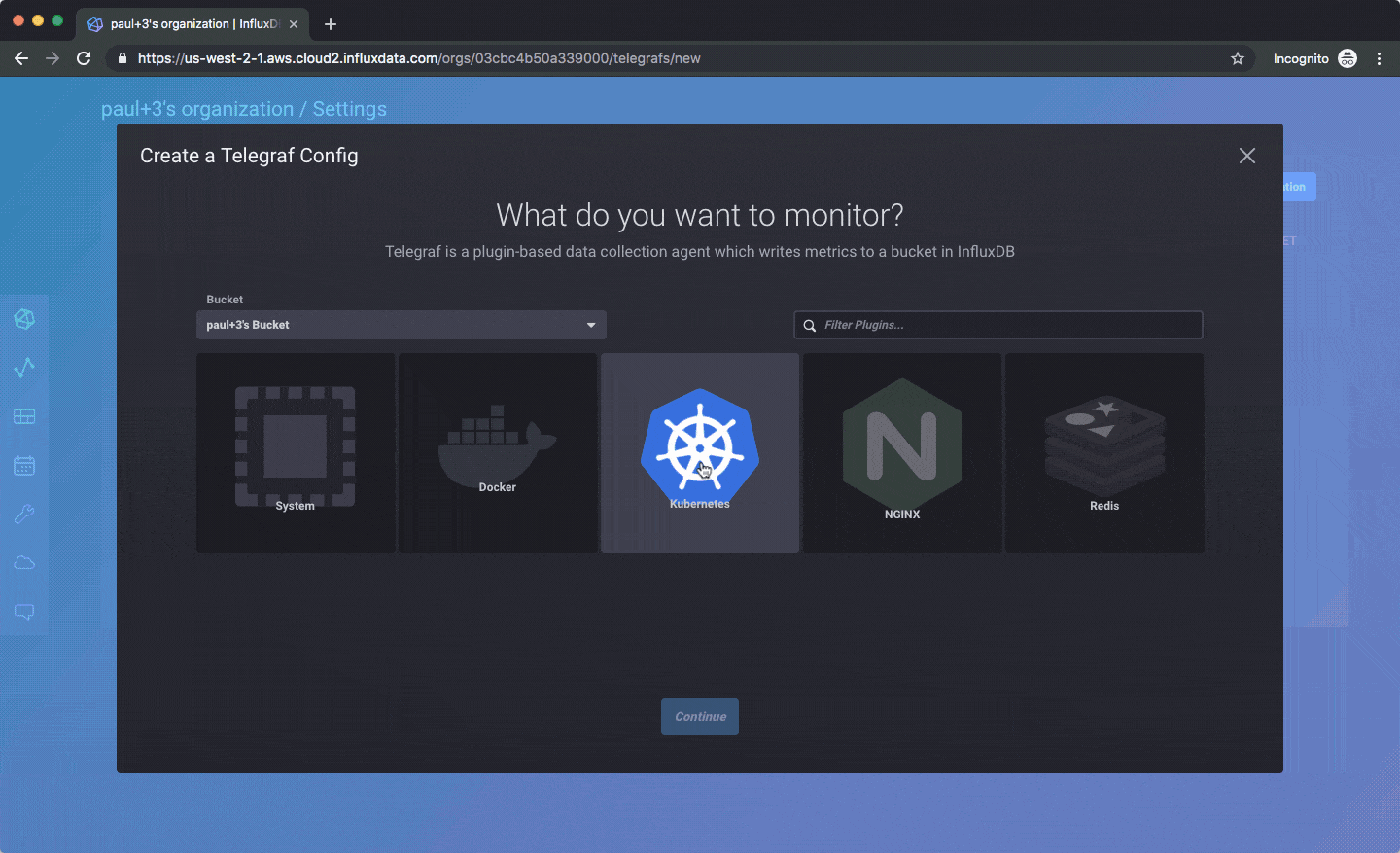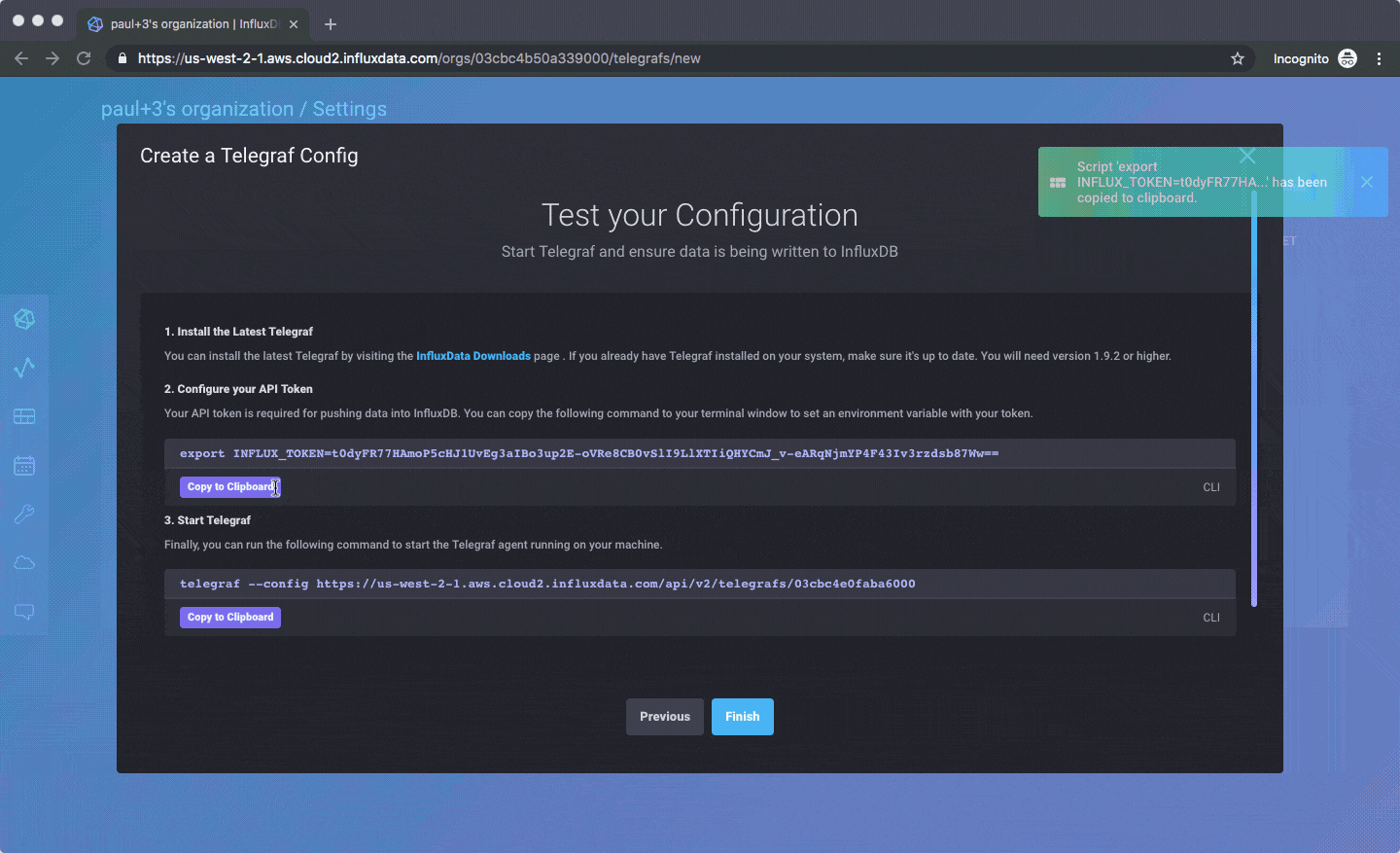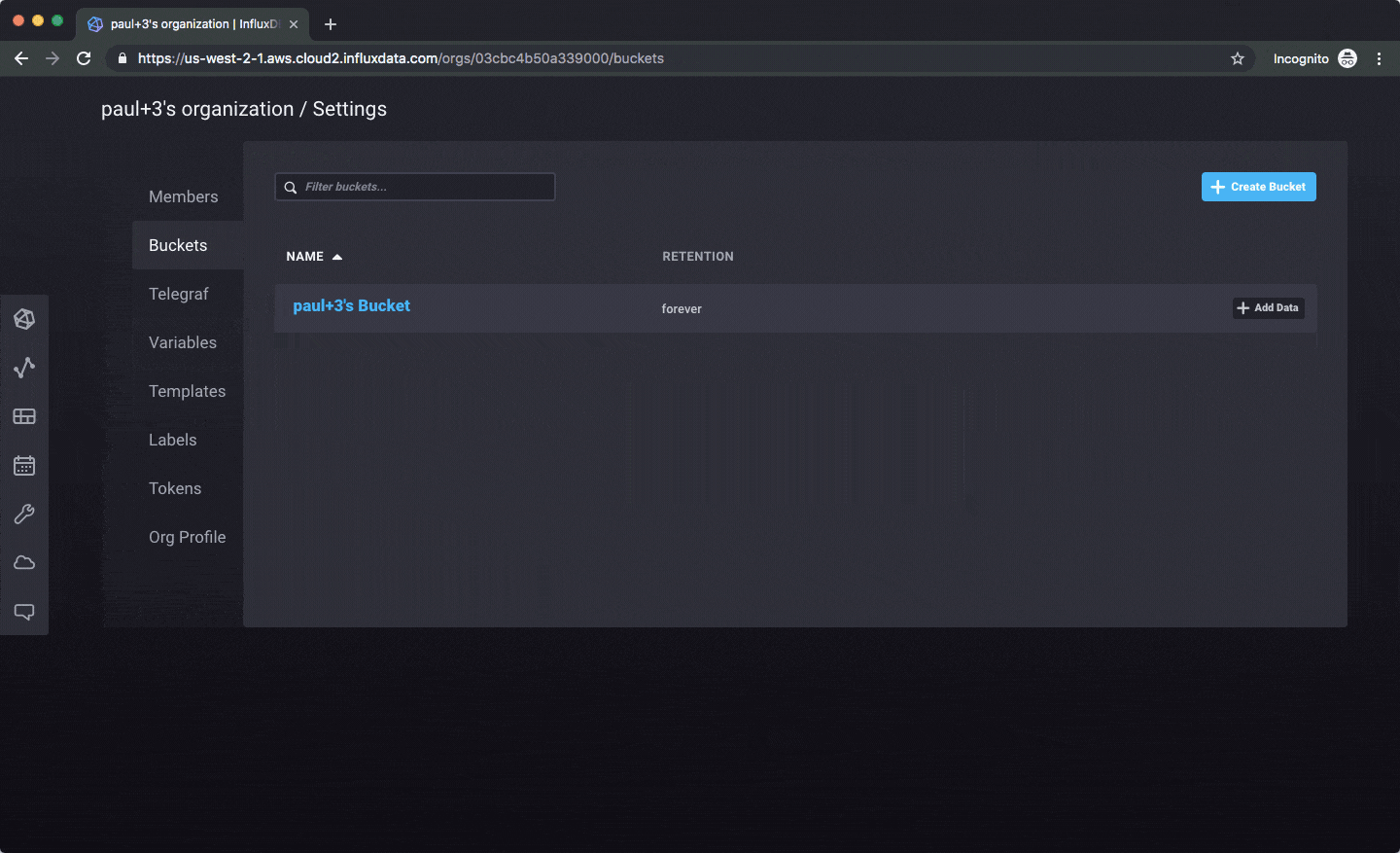
您应该能够在几分钟内启动并运行。您需要验证您的电子邮件地址,选择您的云提供商和区域(目前仅限 AWS 美西),并同意我们的 Beta 条款,之后您应该可以免费使用,无需信用卡或其他任何东西。这是一个创建 Telegraf 配置的动画 GIF,然后您可以从您自己的服务器上的任何 Telegraf 代理中提取该配置
以下是如何创建 API 令牌以用于客户端库
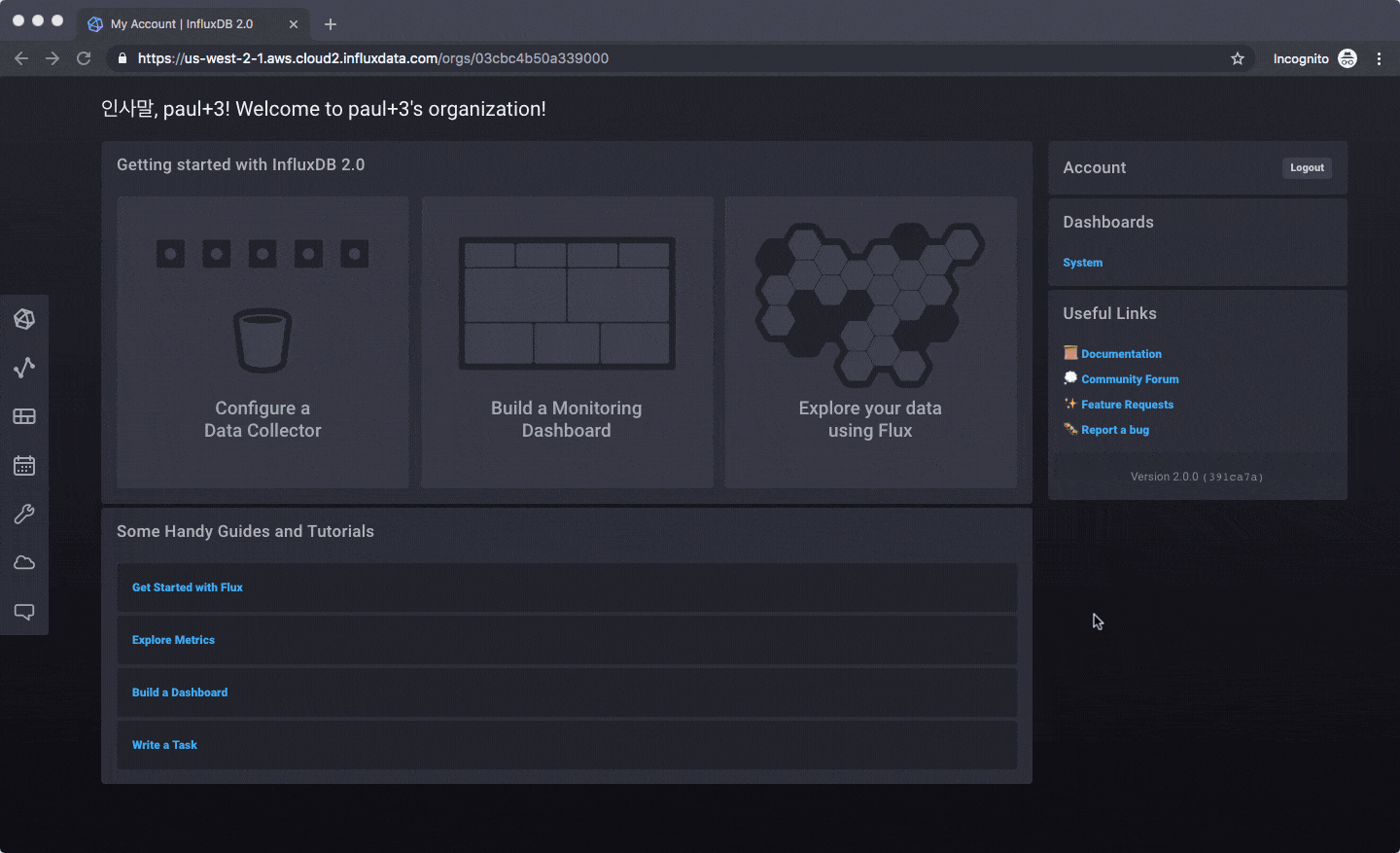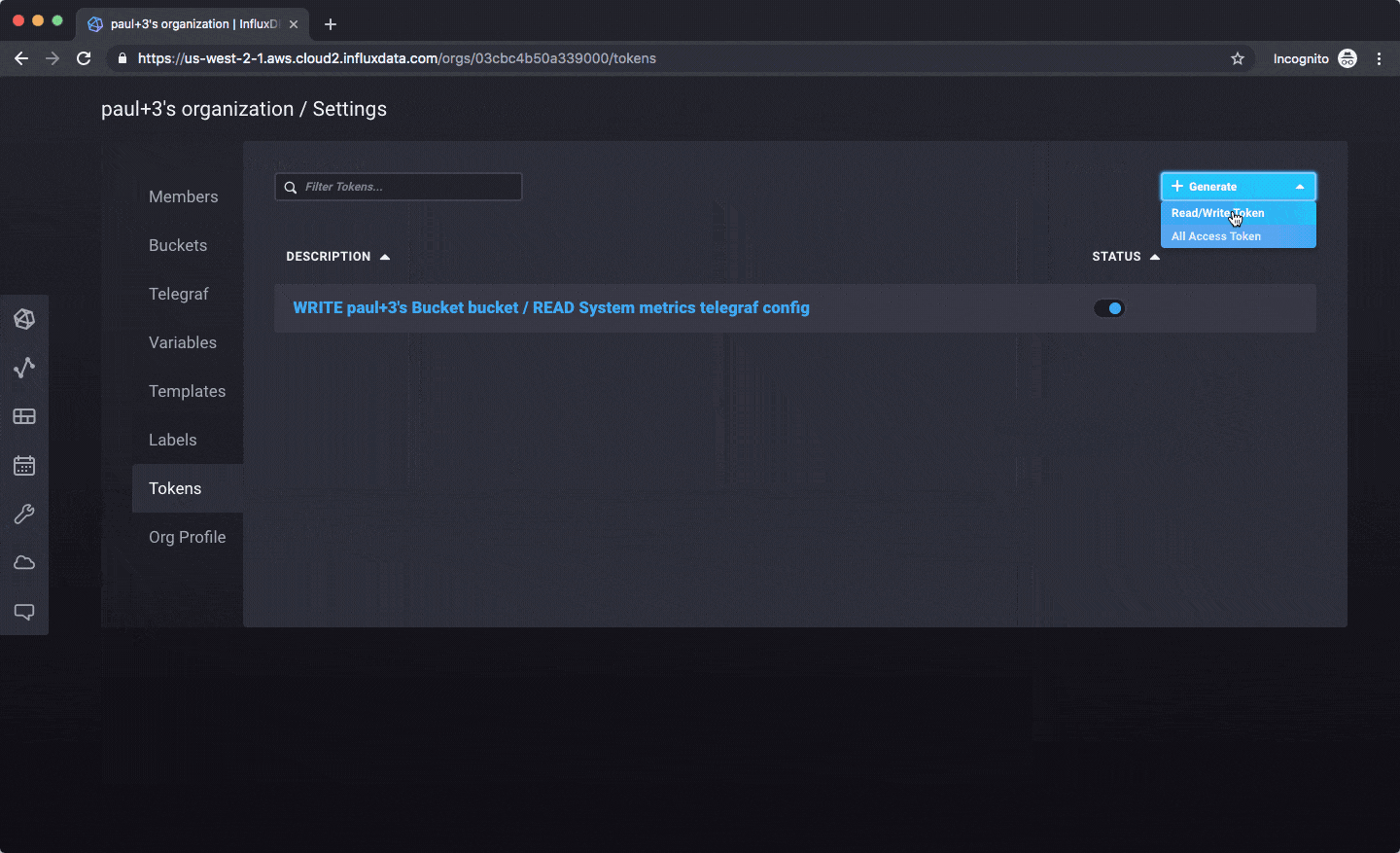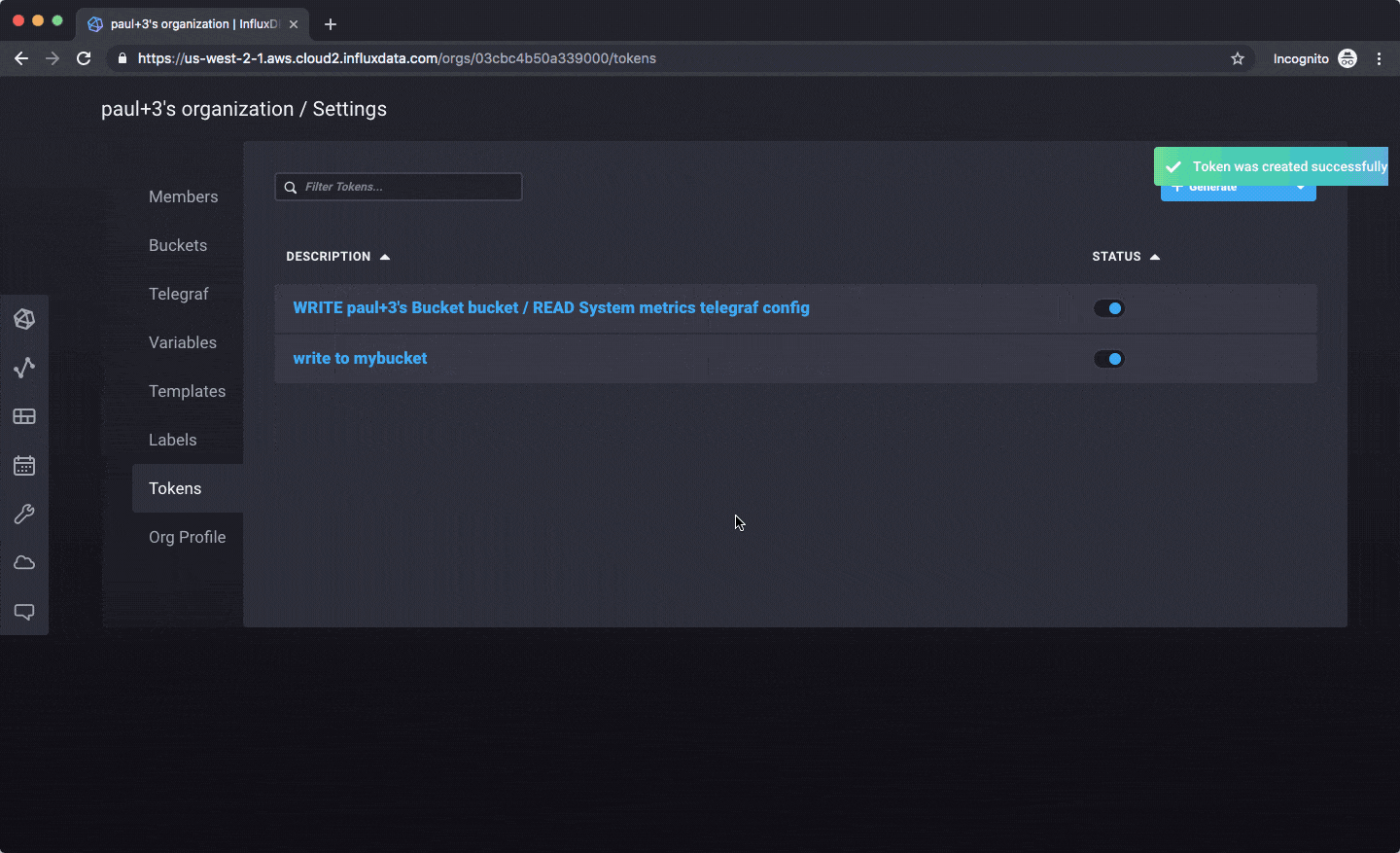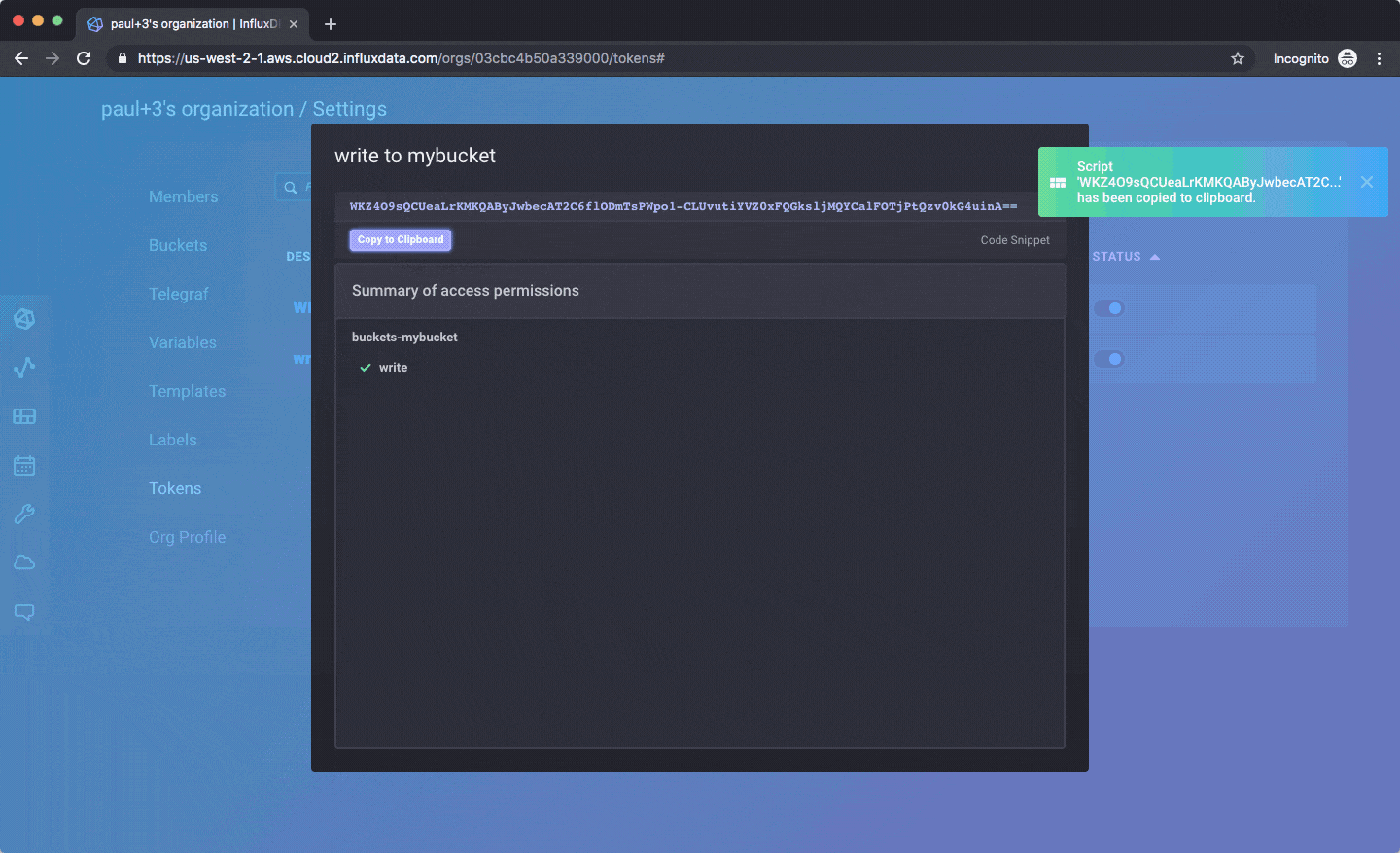
获得令牌后,您可以使用我们官方支持的客户端库写入数据或访问 API。您可以在 此处找到 InfluxDB 2.0 Javascript 库,或使用 HTTP API,其他库即将推出。
一旦您写入数据,您就可以以图形、表格的形式探索数据,或编写原始 Flux 查询来处理数据。
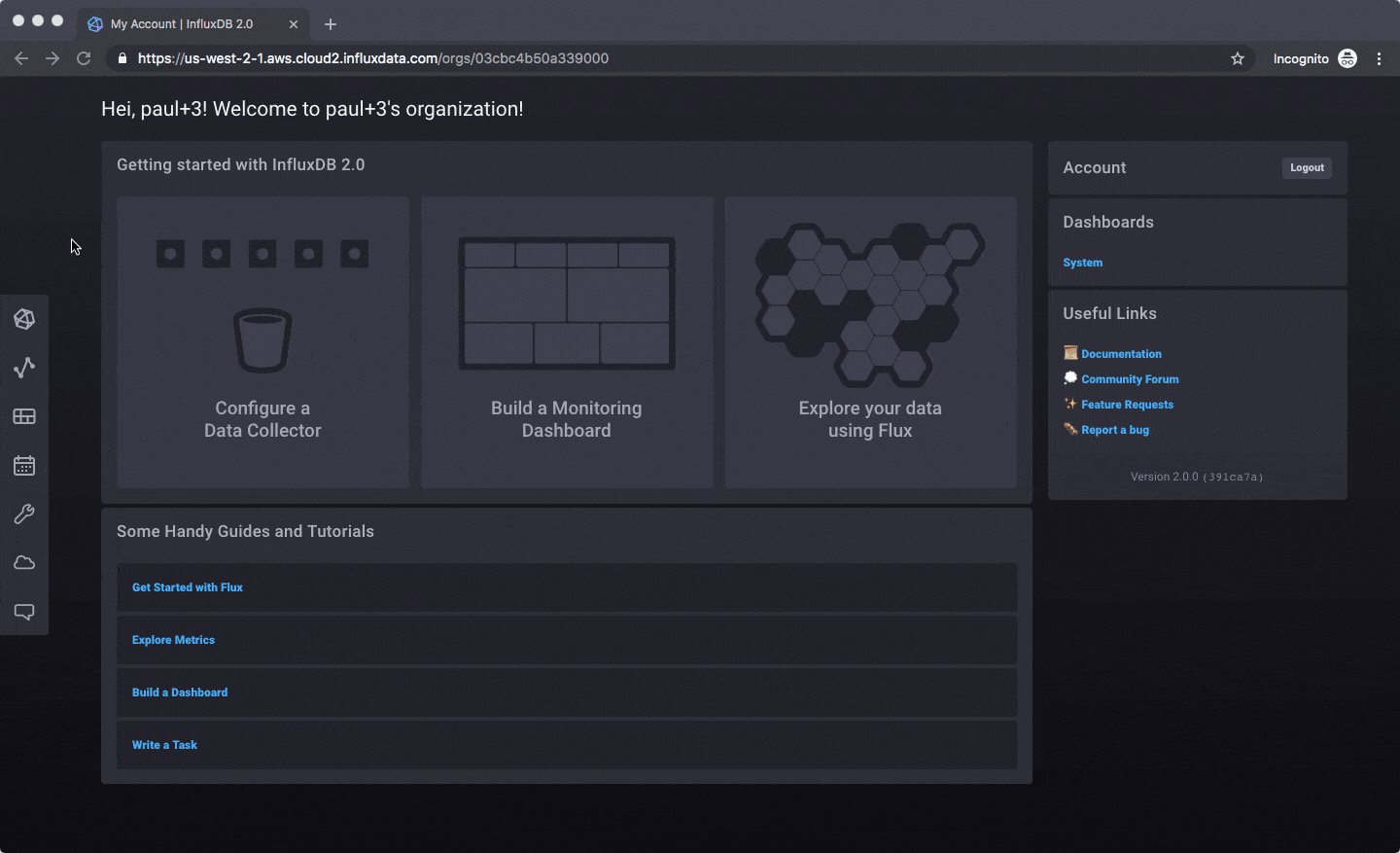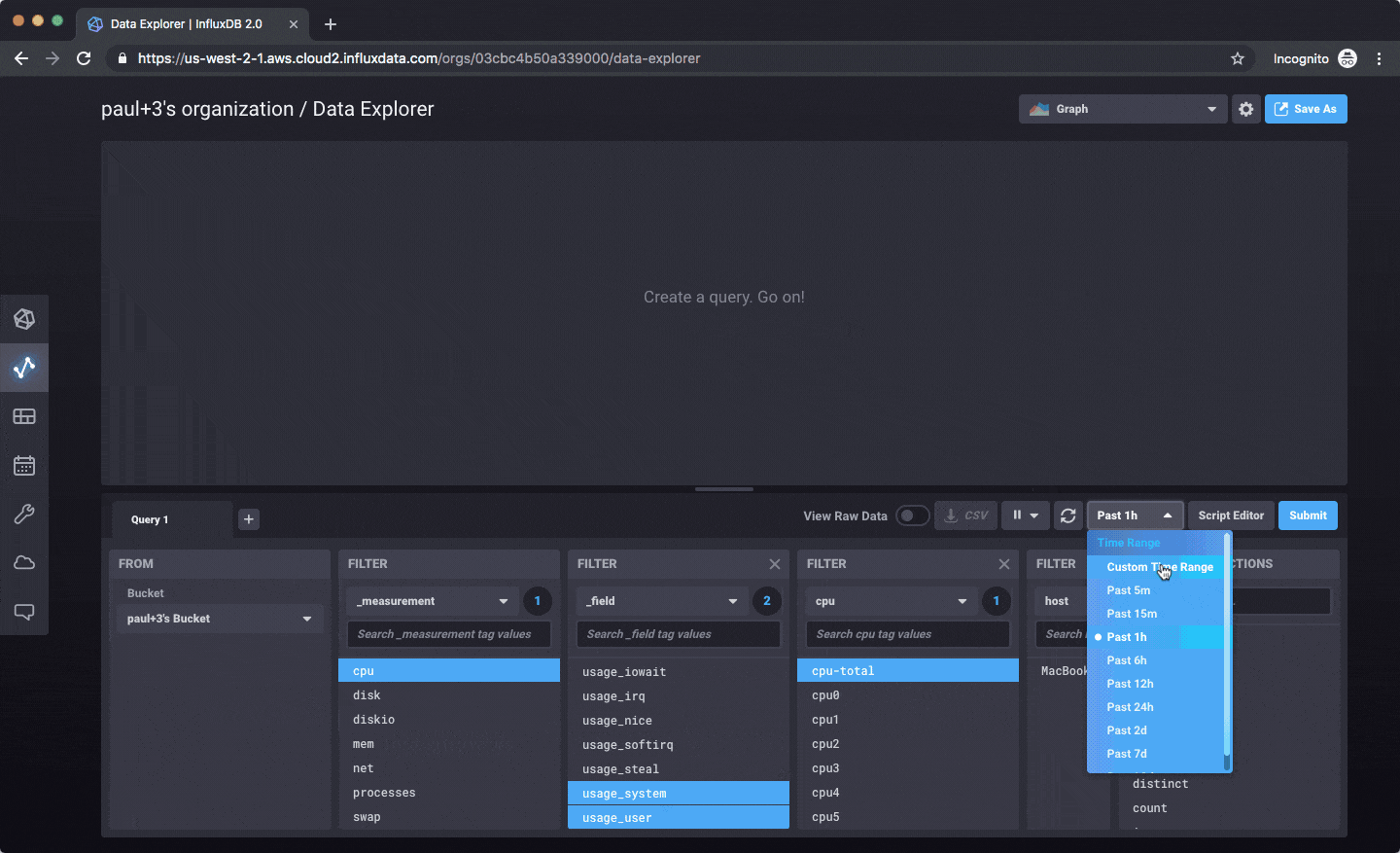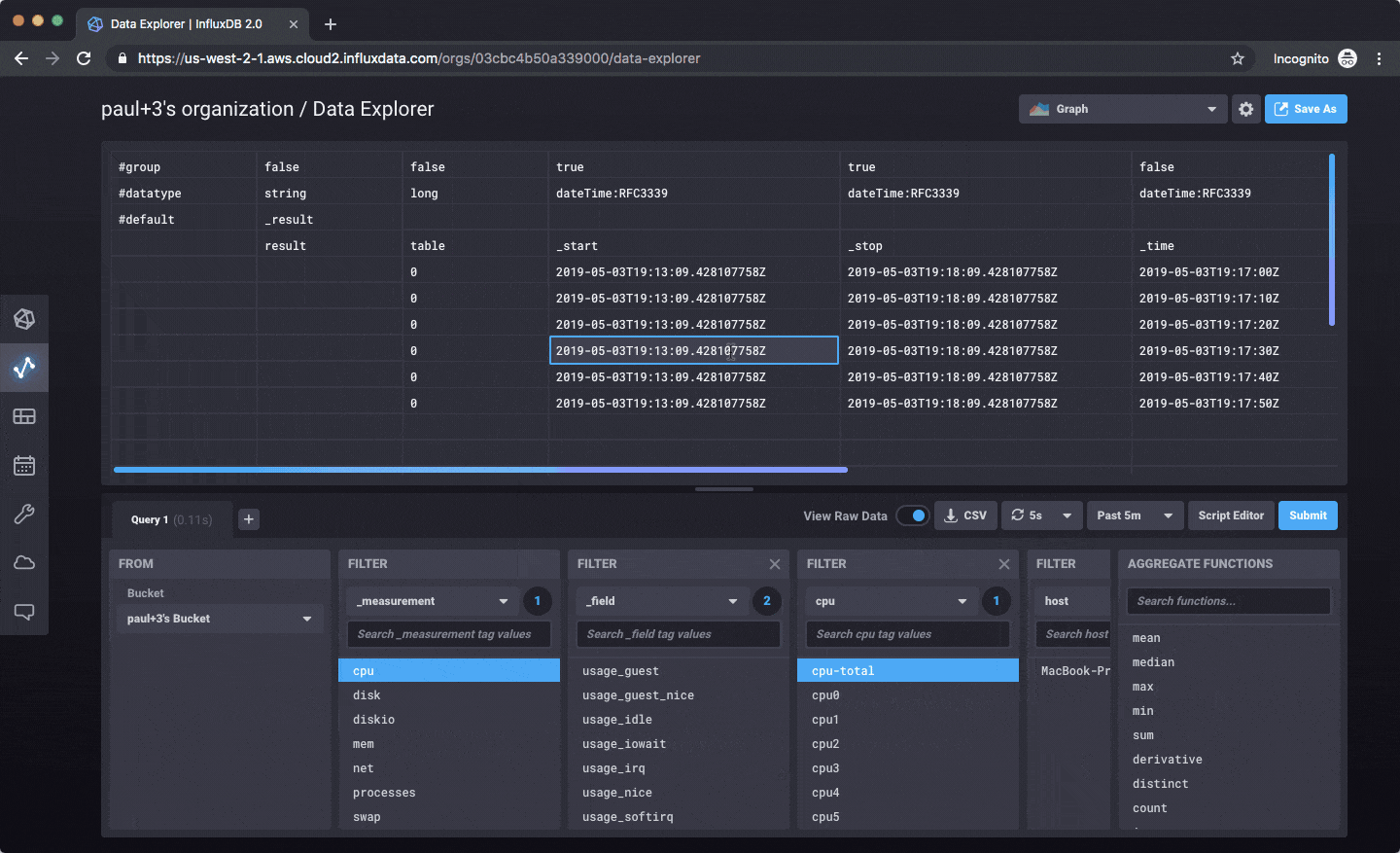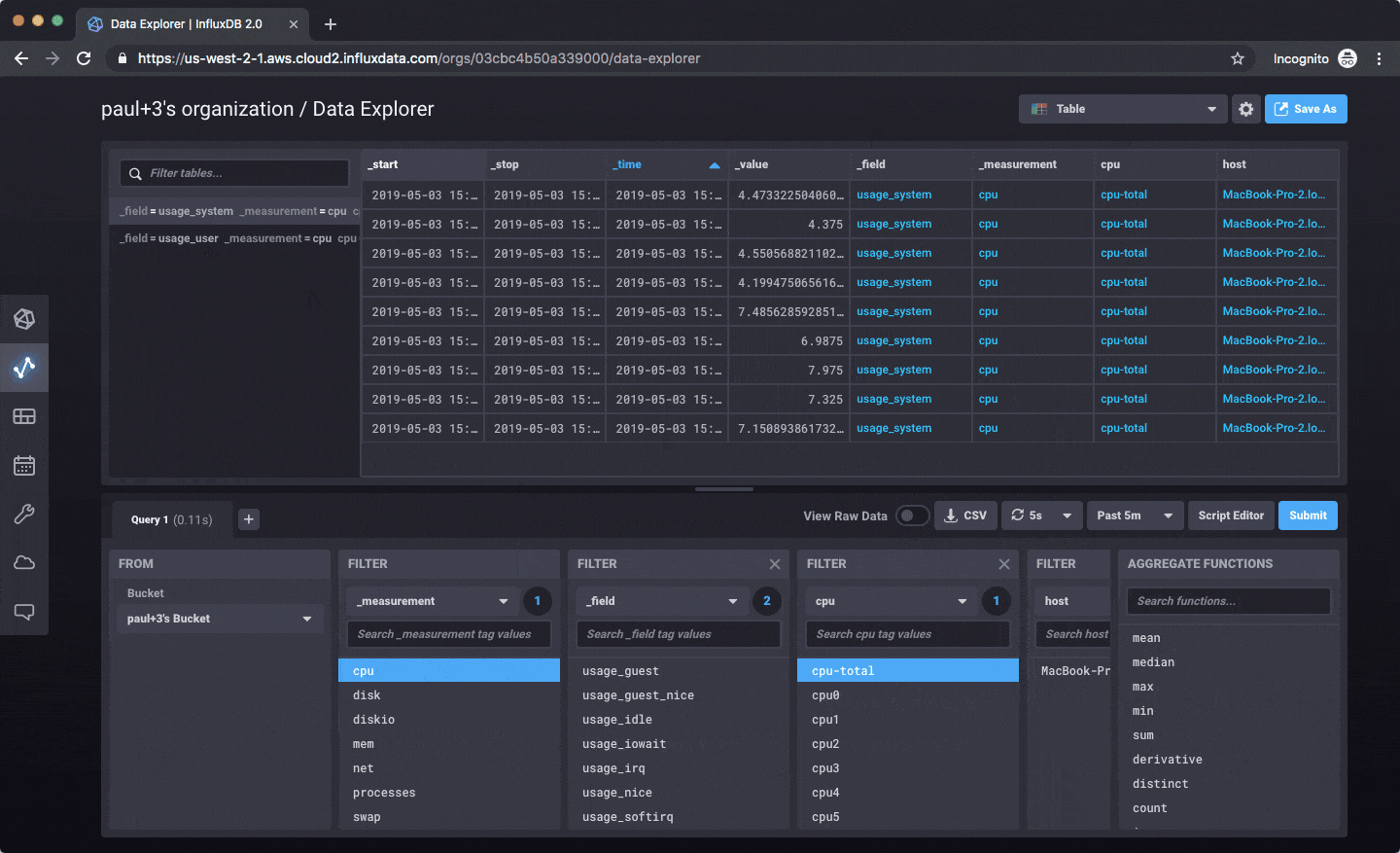
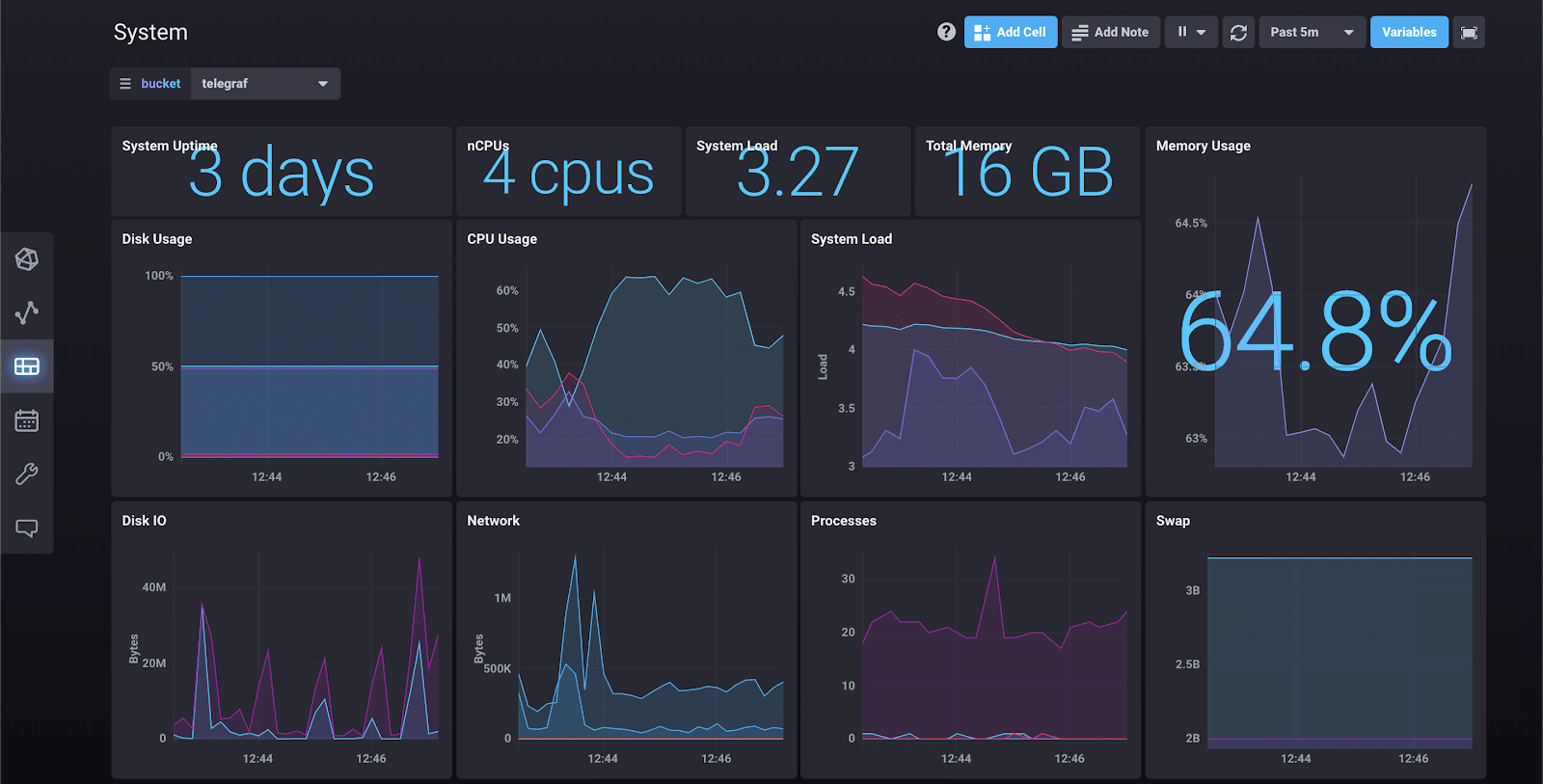
目前,一切都集中在写入数据、查询、探索和仪表板方面。这是一个示例
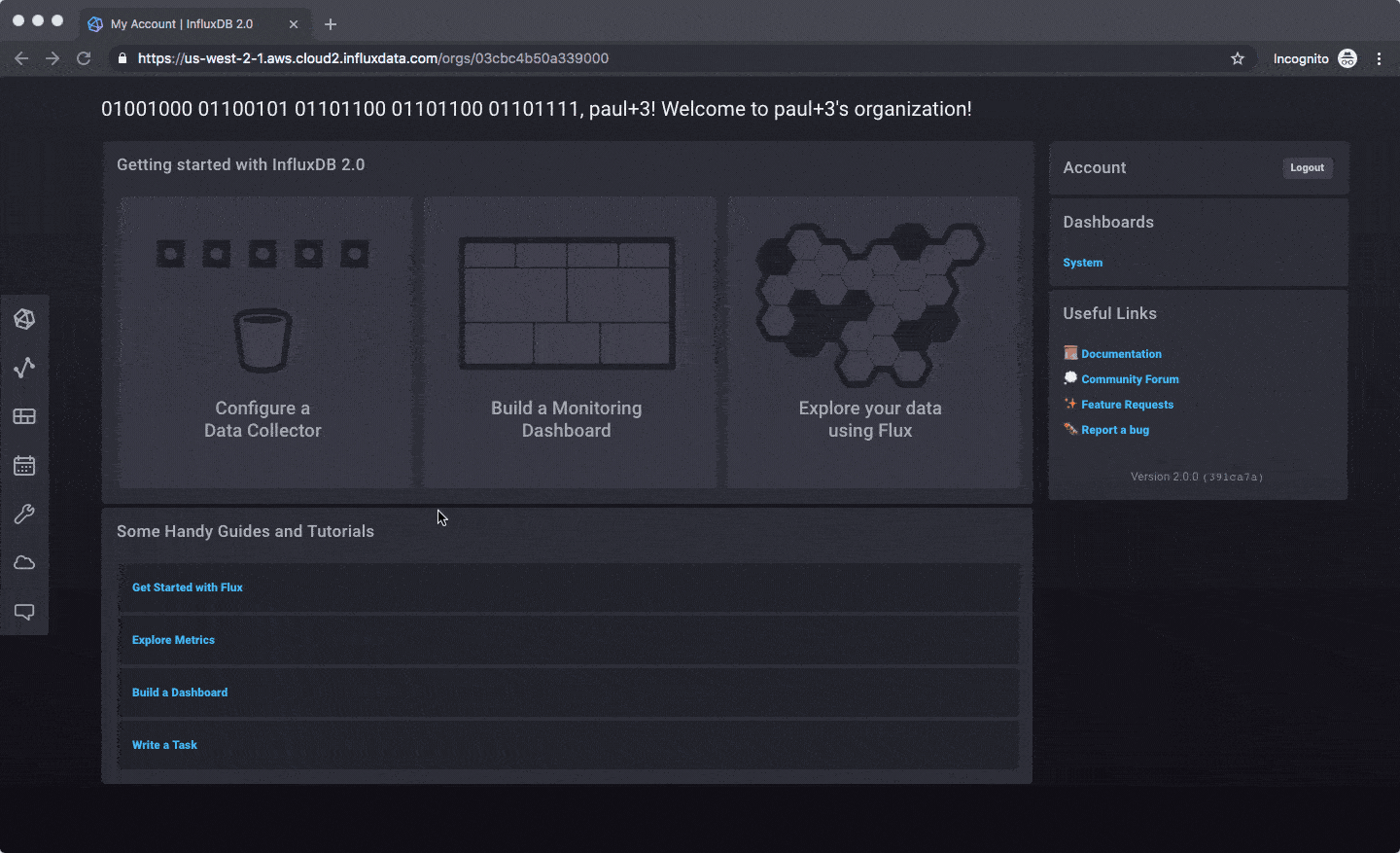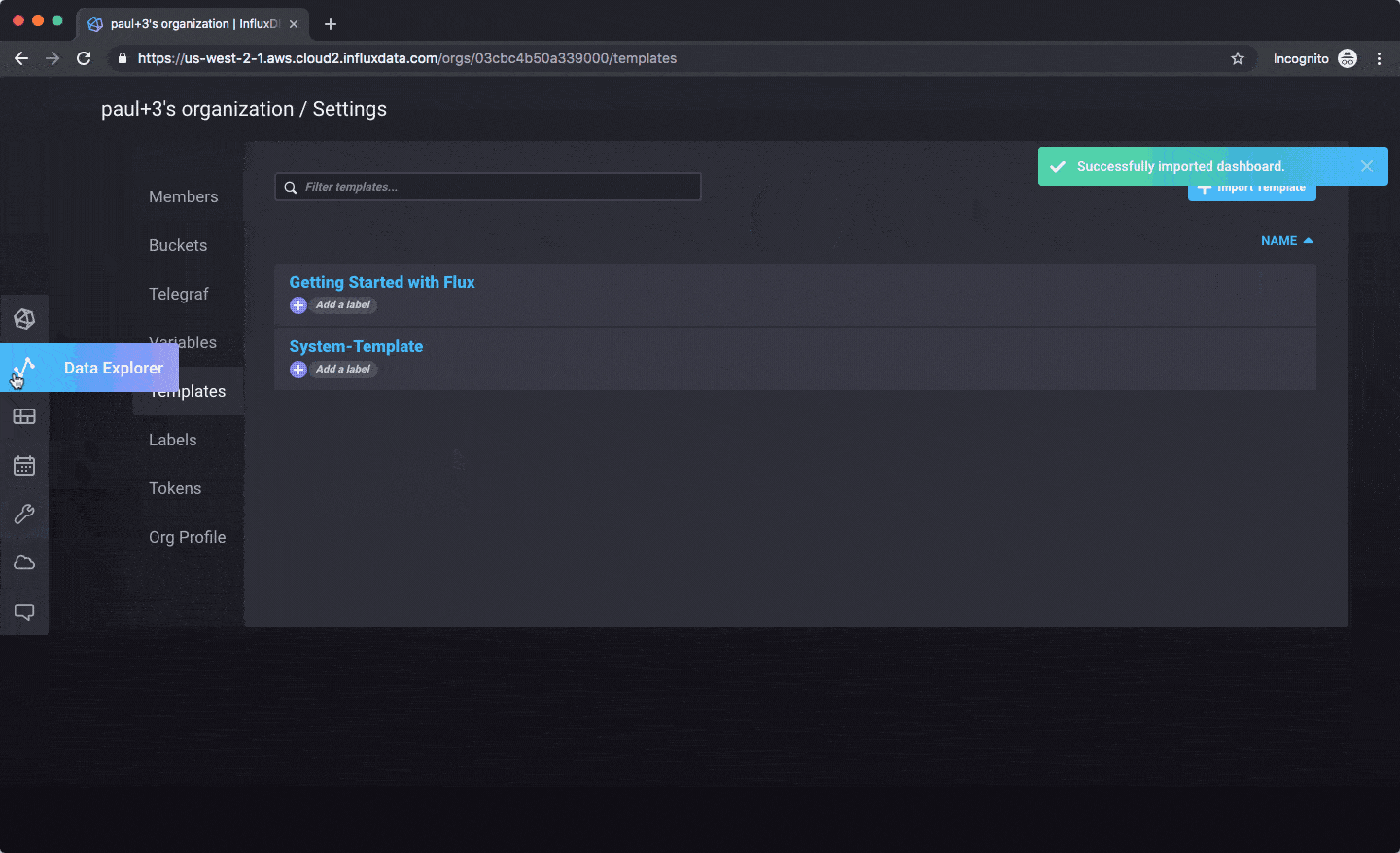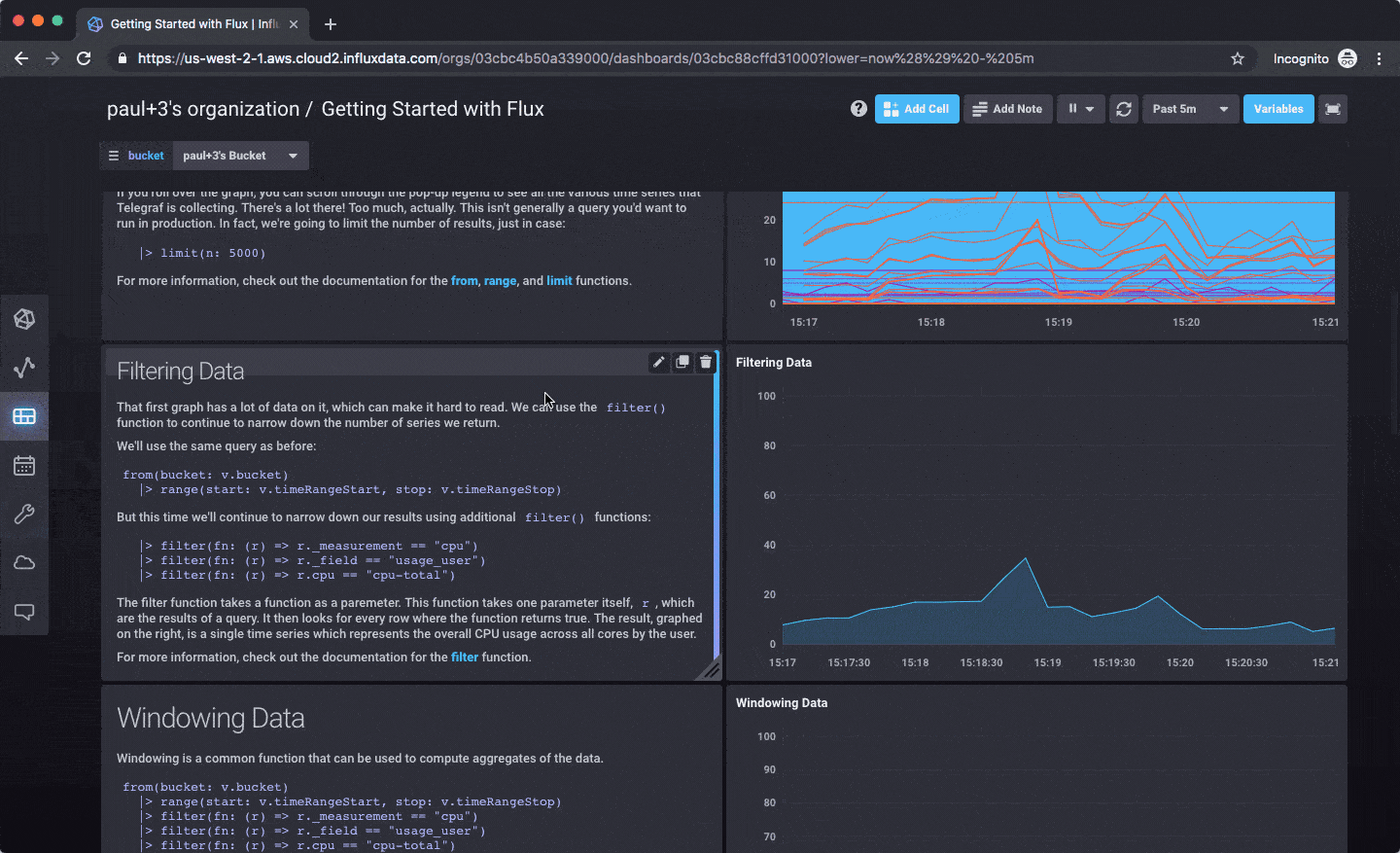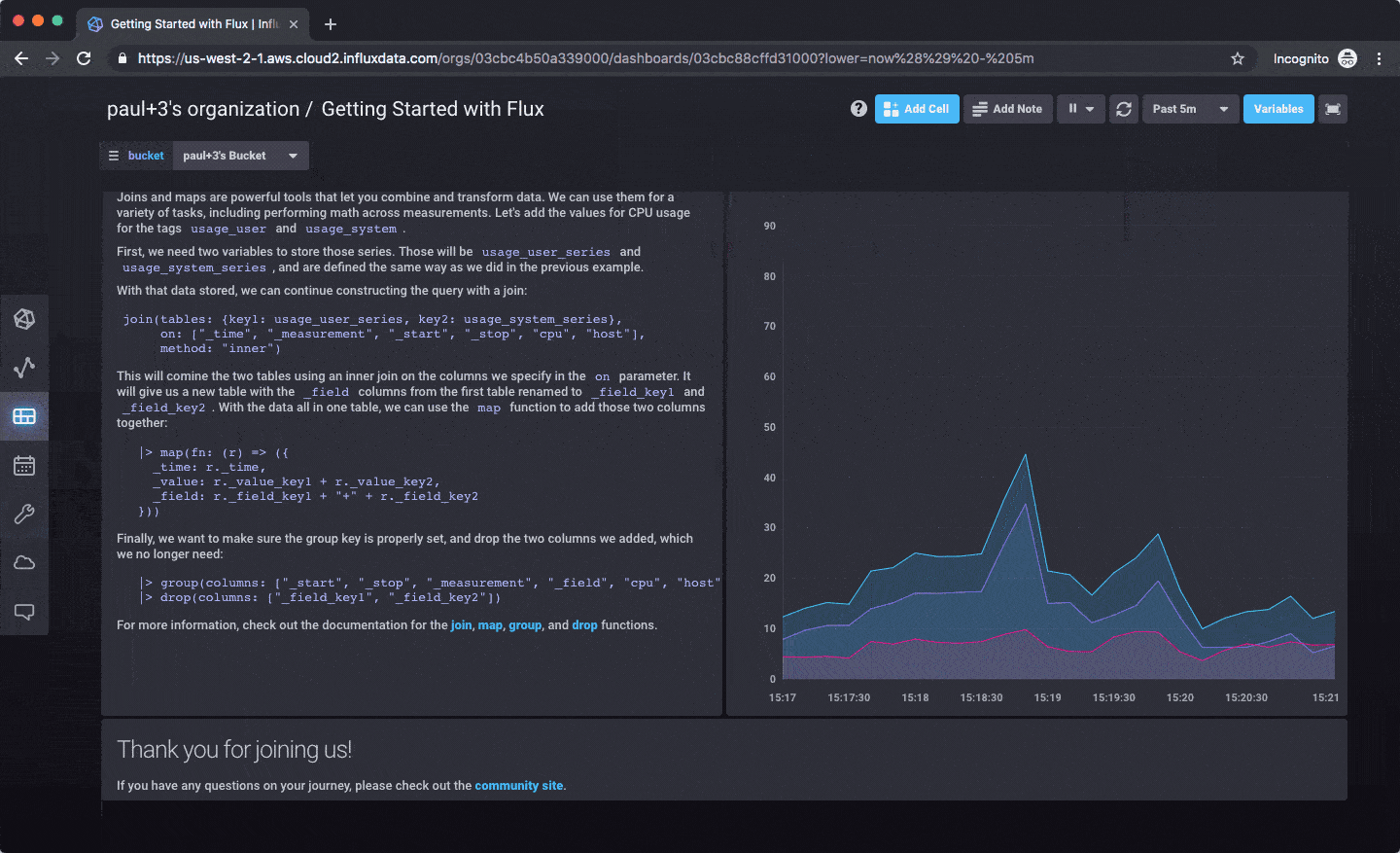
还有一个关于使用 Flux 的精彩介绍,作为模板包含在内
即将推出
我们还有大量工作要做,我们将定期在云端发布。我们将继续每周发布 OSS alpha 版本的节奏,同时更频繁地在云端发布。以下是未来几周和几个月内我们将推出的一些重要内容。
我们将完成一些重要的 Flux 语言功能。我们将添加流控制、递归函数、加载配置密钥以及与 PagerDuty、Slack 和 SMTP 等第三方 API 的连接器。我们还将添加用户定义的包和导入以及公共包存储库(如 NPM、Rubygems 或 Cargo)。这些功能与 Tasks 功能相结合,将把 InfluxDB Cloud 2.0 转变为一个全面的监控、ETL 和无服务器 Flux 平台。Tasks 可以按计划定期运行,最短可以每秒一次,或者对于较长的报告,例如每天一次或每周一次。
在 UI 中,我们将添加使配置基本监控和警报规则成为可能的功能。在底层,这将使用 Flux Tasks,但用户无需了解这一点。他们只需点击并浏览数据浏览器,然后创建规则来指定要查找的警报条件以及在这些条件下通知谁以及何时通知。我们还将从 Chronograf 中恢复日志查看器,对其进行修订,并使其成为更通用的事件查看器。
基于使用量的定价
InfluxDB Cloud 2.0 将提供基于使用量的定价。我们正在利用 Beta 阶段来确定具体细节,我们希望与我们的用户合作,了解他们有哪些需求。从广义上讲,定价将基于
- 写入 API 的字节数
- 从 API 发送的字节数(查询)
- Flux 计算时间
- 存储小时数
列表中的前三项是相当简单的计数器。您为您写入、读取的内容以及您的 Flux 脚本和查询占用的 CPU 时间付费。由于 Flux 是一种通用的编程语言,因此按时间而不是按查询收费更有意义。但是,随着我们改进底层查询计划器、优化器和引擎的性能,您的成本将会降低。
存储小时数基于您的数据每小时存储在我们系统中的量。每小时我们都会检查有多少数据在那里。较旧的数据将具有压缩和更好压缩的优势。因为我们是一个时间序列平台,所以存储量每小时可能会有很大差异,这就是为什么我们以这种方式而不是每月定价的原因。
我们希望听到您的反馈!
我们很乐意听取您关于用户体验、客户端库、定价模型、您希望看到哪些功能以及您希望看到接下来支持哪些语言的反馈。点击此处免费注册并在几分钟内探索您的数据。或点击此处查看入门指南。
请通过 Twitter (@pauldix) 与我联系,或者如果您将这篇文章提交给 HN,我会在评论中回复。谢谢!
