Flux Joins 与 Pandas Joins 的 UX 评测
作者:Anais Dotis-Georgiou / 产品, 用例, 开发者
2018 年 12 月 17 日
导航到
InfluxData 最近发布了最新版本的 Chronograf 和 InfluxDB。随之而来的是 Flux 的技术预览。Flux 是用于时间序列数据的新查询语言和引擎。Flux 的文档可以在这里找到。
在之前的博客文章中,我分享了如何使用 Flux Joins 跨测量执行数学运算来计算热交换器的效率。请阅读“InfluxDB:如何在测量之间执行连接和数学运算”,以了解我尝试复制的数据集和连接的背景。本博客系列的 repo 可以在这里找到。
在学习 Flux 时,我会将其与我已经熟悉的语言或库进行比较。我决定分享我学习和使用 Flux 的经验,因为我惊讶地发现我更喜欢它而不是 Pandas 来处理时间序列数据。我感到惊讶是因为起初我对 Flux 非常怀疑。例如,我不太喜欢 |>,管道前向。我几乎从不使用管道,并且不确定是否必须学习新的笔划。现在,我发现它们大大提高了可读性。每个管道前向都返回一个结果。阅读 Flux 查询感觉就像阅读项目符号列表。
在我解释为什么我的语言偏好发生了变化之前,我想分享我对 Flux 之前的 Pandas 的评论。
Flux 之前的 Pandas Joins 评测
“我喜欢 Pandas。DataFrames 非常棒。太容易了。我无法想象有任何东西比 Pandas Joins 或 Merges 更让我喜欢。它们的行为完全符合预期。”
既然您知道我对 Pandas 进入 Flux 的感受,让我们通过查看我在之前的博客中进行的第一个连接来开始比较。
Flux 中的连接
Th1 = from(bucket: "sensors")
|> range(start: dashboardTime)
|> filter(fn: (r) => r._measurement == "Tc1")
|> drop(columns:["_start", "_stop", "_measurement", "position", "_field"])
Tc2 = from(bucket: "sensors")
|> range(start: dashboardTime)
|> filter(fn: (r) => r._measurement == "Tc2")
|> drop(columns:["_start", "_stop", "_measurement", "position", "_field"])
TC = join(tables: {Tc1: Tc1, Tc2: Tc2}, on: ["_time"]])其中 Tc1 看起来像

其中 Tc2 看起来像

连接看起来像
Pandas 中的连接
我的数据集作为 DataFrame 看起来像这样。
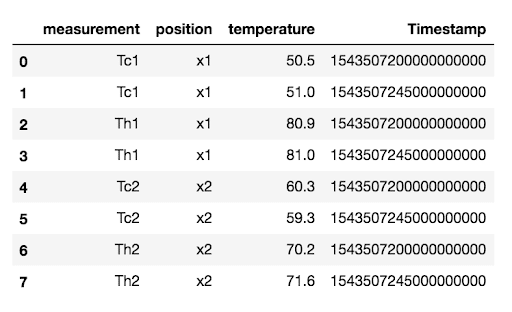
为了复制连接,我将数据分成 4 个不同的 DataFrames,以反映 InfluxDB 中的 4 个不同的测量值
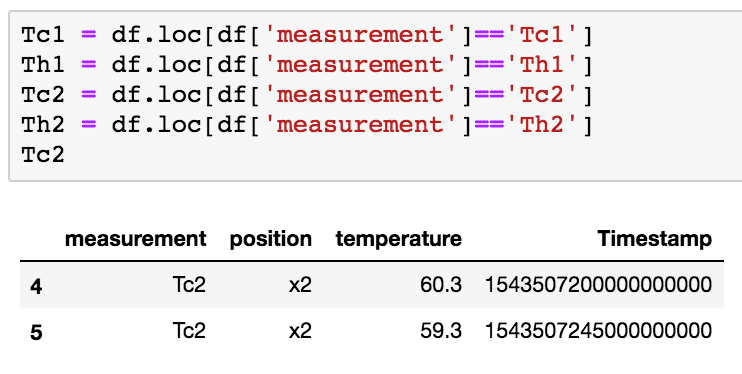
现在,如果我想复制我制作的 Flux Join,我必须重置较小 DataFrames 的索引。这是因为 Pandas 中的 Joins 在索引上运行。
现在我可以执行连接了。

如果我想清理我的 DataFrame 以使其与我的 Flux Join 完全相似,我将不得不删除很多列(特别是, df.drop(["measurement_Tc1, "position_Tc1", "measurement_Tc2", "position_Tc2")。
这就是 Pandas Join 放在一起的样子
Tc1 = df.loc[df['measurement']=='Tc1'
Tc2 = df.loc[df['measurement']=='Tc2'
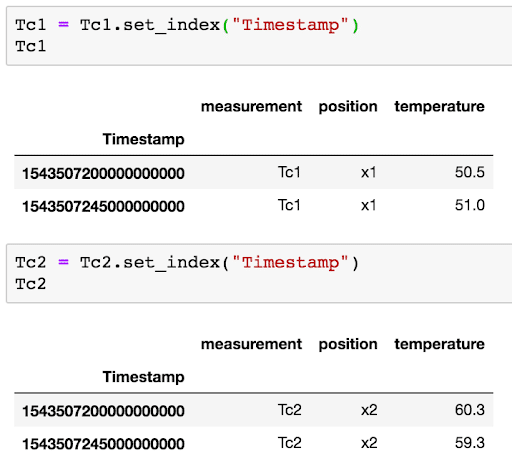
Tc1 = Tc1.set_index("Timestamp")
Tc2 = Tc2.set_index("Timestamp")
df = Tc1.join(Tc2, how="left", lsuffix='_Tc1', rsuffix='_Tc2')
df.drop(["measurement_Tc1, "position_Tc1", "measurement_Tc2", "position_Tc2"与 Flux Join 相比,此连接显得笨拙,原因有几个。首先,我必须重置索引。其次,我必须指定左后缀和右后缀。我喜欢 Flux 的方式,我可以将我的表存储在变量中,然后仅用冒号将表与我选择的后缀关联。 join(tables: {Th1: Th1, Th2: Th2}, on: ["_time", "_field"]) 既简单又清晰。我不必跟踪我的左侧和右侧。第三,如果我想删除列以使我的 Pandas Join 与我的 Flux Join 完全相同,我将不得不:a) 首先复制我的 DataFrames,这样我就不会丢失我的数据,或者 b) 将连接存储在一个新的 DataFrame 中,然后在之后删除列。选项 a) 意味着编写更多代码行。选项 b) 效率较低。
Flux Joins 实际上更类似于 Pandas Merges,所以让我们看一下一个。

这很好,但 Flux Join 仍然有一些好处。同样,我更喜欢 Flux 的冒号语法,而不是像 Pandas 那样必须指定“left_index”和“right_index”。此外,我喜欢我可以使用 Flux 连接多个列。不幸的是,我无法使用 Pandas 执行此操作。当这些列的内容相同时,连接多个列非常有用。想象一下,标签键“position”只有一个值,其中 position = x。我的 Pandas Join 看起来与上面的相同,除了“position_x”列和“position_y”列将是相同的。但是使用 Flux,我可以连接“time”和“position”。 我的结果表将只有一个位置列。通过使用 Flux 连接多个列,我可以轻松有效地消除重复或冗长的列。此功能对于时间序列数据尤其有用,在时间序列数据中,具有重复的标签值、时间戳或字段键是正常且频繁的。
我对 Pandas 的新印象是这样的。
Flux 之后的 Pandas Joins 评测
“我仍然喜欢 Pandas。但是,我开始明白为什么 Flux 是专门为时间序列数据构建的。将 Pandas 与 Flux 进行比较实际上是不公平的,因为 Pandas 并非专门为时间序列数据编写。”
当我继续将 Flux 与其他数据处理方式进行比较和对比时,我不断回到同一个想法。时间序列数据具有独特的属性,时间序列数据探索体验需要专门针对这些属性进行定制。显然,Flux 的编写考虑到了这一点。
